
Joined July 2008
- Tweets 2,035
- Following 780
- Followers 4,848
- Likes 2,181
817 Photos and videos









Pinned Tweet

9 Mar 2017
An animated tour of Stitch Fix Algorithms.
algorithms-tour.stitchfix.co… via @stitchfix_algo #datascience #algotour
5
136
328
18 Nov 2024
Find me on Bluesky:
@ecolson.bsky.social. Love all things data science, machine learning, AI, and management there of.
176
28 Mar 2024
One of my heroes. Thank you for all the contributions to knowledge

Today we’ve lost a giant and a visionary: Prof. Daniel Kahneman has passed at the age of 90. The Princeton SPIA community shares our condolences with his family and all who knew him, learned from him, and loved him. bit.ly/4cy0arM
3
792
6 Mar 2024
Working in companies shouldn't be so hard. Even when we all want the same things, we trip over bad process and unnecessary coordination. At the same time, other things can be too easy and we do things we later regret. Learn how to smartly work with friction.
The Friction Project: How Smart Leaders Make the Right Things Easier and the Wrong Things Harder. By @work_matters and Huggy Rao
amazon.com/Friction-Project-…
1
5
1,374
5 Mar 2024
Must be fun to be a PhD student right now. So many adjacent possibilities surface now that foundational models are available.
Cool paper on the relationships between objects in an image.
arxiv.org/pdf/2402.19474v1.p…
#AI #computervision
2
413
9 Jan 2024
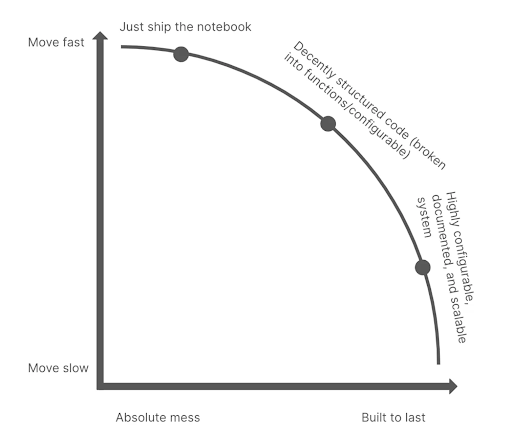
Good framing on the tradeoff between moving fast and shipping high quality code. In a data science context, I believe one needs to lean towards 'fast' in the short-term in order to learn more quickly and allay uncertainty. But, once value is found, we need refactor to achieve a robust system in the long-term to enable future learnings. Good infrastructure can shift the efficient frontier to outward.
Nice job @elijahbenizzy
blog.dagworks.io/p/how-well-…
#datascience
1
2
11
1,274
19 Dec 2023
Gorgeous visualization. Effective too. Coneys so much more than text alone. NYTimes always does a nice job.
nytimes.com/interactive/2023…
222
14 Dec 2023
Great article featuring @work_matters and @huggyrao on "addition sickness": the unnecessary rules, procedures, communications, tools, and roles that seem to inexorably grow, stifling productivity and
creativity.
13 Dec 2023

Our friends Bob Sutton and Huggy Rao—two professors who have been working with the d.school from the start—share their work with @HarvardBiz.
bit.ly/3GHJi3h
@work_matters @huggyrao @StanfordGSB
2
445
24 Oct 2023
So many companies say they are okay with failure but they still behave in ways which discourages risk-taking and innovation. In @AmyCEdmondson new book she articulates the different types of failures which gives us with the vocabulary to adjust and embrace the right kind of wrong.
1
3
610
29 Sep 2023
RIP Netflix DVD. A long run.

Netflix has shipped 5.2 billion DVDs over the last 25 years — here's a timeline of the most rented movies throughout those years.

1
564
5 Sep 2023
Very appreciative to @wesmckinn and so many others that help evolve this space. So many of us stand on your shoulders while focusing on the mere application of these technologies and receiving the kudos for the value they generate. Thank you!
vldb.org/pvldb/vol16/p2679-p…
#datascience #machinelearning #Ai
2
2,825
24 Aug 2023
Expressing PySpark Transformations Declaratively with Hamilton blog.dagworks.io/p/expressin…
1
5
783
22 Aug 2023
Mind blown. I just realized that iPhone and MacBooks can share a copy buffer. Copy on one, paste to the other. How long has that been there?
5
1
7
2,922
18 Aug 2023
Hamilton in action (a technology that spun out of the Stitch Fix algorithms team).
blog.dagworks.io/p/container…
#DataScience #LLMs
1
8
625
27 Jun 2023
Pretty much any metrics layer, etl, or feature store would benefit from this.
27 Jun 2023

🎇 Big news this week! @DagWorks is open for anyone to sign up. It's free to get started! 🍾
TL;DR: Build better data/ML pipelines. Faster.
DAGWorks is your unifying platform layer for data & ML pipelines.
1/n

4
734
21 Jun 2023
The graphics on Netflix's tech blog have leveled-up. Good content too.
netflixtechblog.com/detectin…
1
442
19 Jun 2023
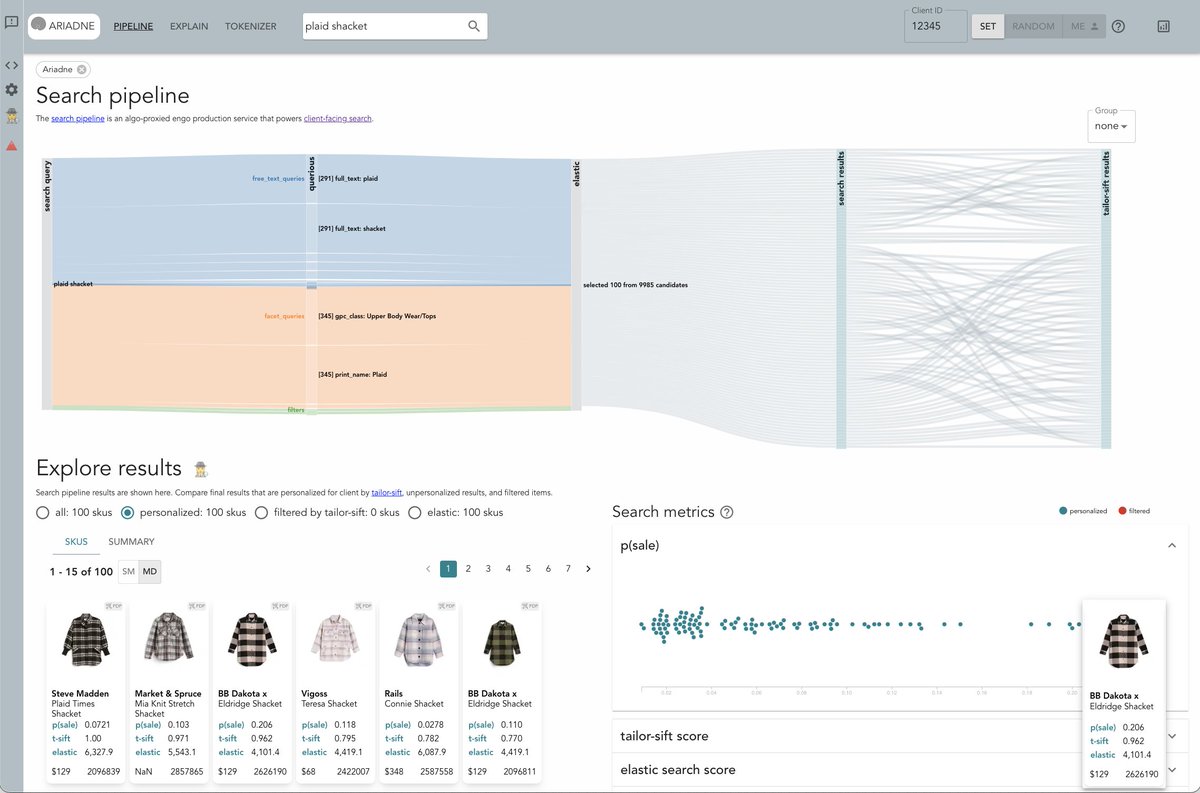
I always appreciated the Stitch Fix Algorithms team's willingness to invest in amazing internal tools. Ariadne: building a custom observability UI for personalized search multithreaded.stitchfix.com/…
3
10
1,399
19 Jun 2023
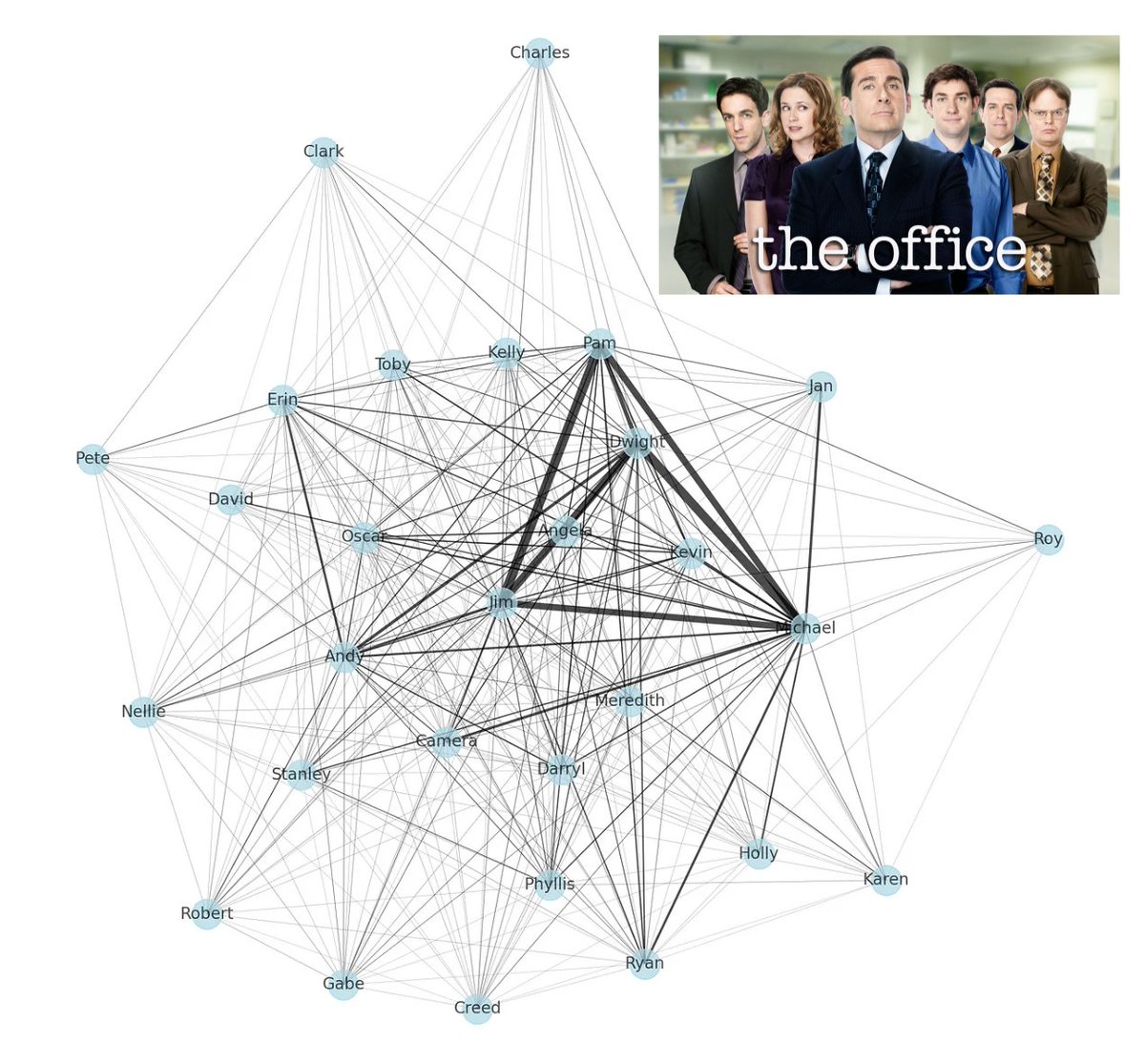
Fun network diagram of data for The Office. Made with my son!
medium.com/@ccolsonbball/the… #TheOffice #DataScience
5
1,192
15 Jun 2023
Plausible. But I’ve learned any prognostications on complex systems are far more likely to be wrong than right. Looking forward to connecting these dots in hindsight.

Here's how I think of open-source LLM vs top proprietary ones:
1) Open LLMs will improve at an accelerating pace.
2) However, their gap from the best commercial models will continue to *widen*. This is because OSS community is decentralized and chases different objectives, but big companies are able to concentrate their massive GPU & talent firepower at babysitting a single model, while also learning the best tricks from OSS. GPTs, Claudes, and DeepMind Gemini's will improve at an even faster rate.
I assign < 5% probability that by the time OpenAI releases GPT-5 (let's say in late 2024), any OSS model can even truly match GPT-4 on all tasks that matter. I'd be very, very happy to be proven wrong!
3) OSS LLMs will always have much more diversity. Examples:
- Domain-finetuned models for medical, legal, finance, etc.
- Country-specific models that cater to local cultures and languages.
- Unconstrained models for more creative use cases, like Wizard-7B-Uncensored.
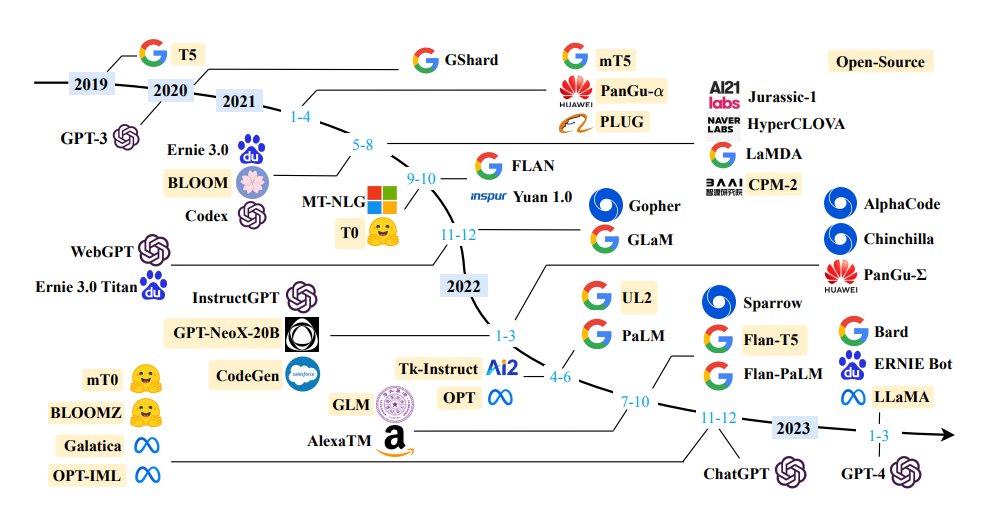
ALT Image credit: Sung Kim, https://medium.com/geekculture/list-of-open-sourced-fine-tuned-large-language-models-llm-8d95a2e0dc76
398