
8 Photos and videos




Pinned Tweet

17 Jul 2025
Tomorrow, I'm excited to present "Finite-Time Convergence Rates in Stochastic Stackelberg Games with Smooth Algorithmic Agents", which addresses how a principal can influence the behavior of competitive learning agents! #ICML2025
📍West Exhibition Hall, W-817, 11:00 - 1:30
🧵👇
1
1
13
2,055
Eric Frankel retweeted

Mar 31
Today we're announcing Treeline and $25M from a16z.
Software and AI have crossed a threshold and we're rebuilding IT services around it - great software paired with experienced technicians, designed to be a foundation for growth.
We're hiring, reach out!

8
5
32
5,200
Eric Frankel retweeted

Introducing ⚓ 𝗔𝗻𝗰𝗵𝗼𝗿𝗲𝗱 𝗗𝗲𝗰𝗼𝗱𝗶𝗻𝗴: a copyright mitigation strategy for any language model! With @uwnlp
LMs today reproduce copyrighted text—raising concerns for creator consent and potential legal (and 💸 💸) liabilities for AI developers. 🫠
𝗔𝗻𝗰𝗵𝗼𝗿𝗲𝗱 𝗗𝗲𝗰𝗼𝗱𝗶𝗻𝗴 relies on two off-the-shelf LMs:
🧼A 𝘀𝗮𝗳𝗲 𝗟𝗠 trained only on permissively licensed text,
⚠️A higher-utility 𝗿𝗶𝘀𝗸𝘆 𝗟𝗠 trained on any data.
The 𝗿𝗶𝘀𝗸𝘆 𝗟𝗠 drives generation, but the 𝘀𝗮𝗳𝗲 𝗟𝗠 acts as an anchor. If the 𝗿𝗶𝘀𝗸𝘆 𝗟𝗠 drifts into memorization, the 𝘀𝗮𝗳𝗲 𝗟𝗠 pulls it back ↩️.
🤝We provide a formal guarantee: outputs stays within a user-set budget of the 𝘀𝗮𝗳𝗲 𝗟𝗠.
Details below! 👇
[1/⚓]
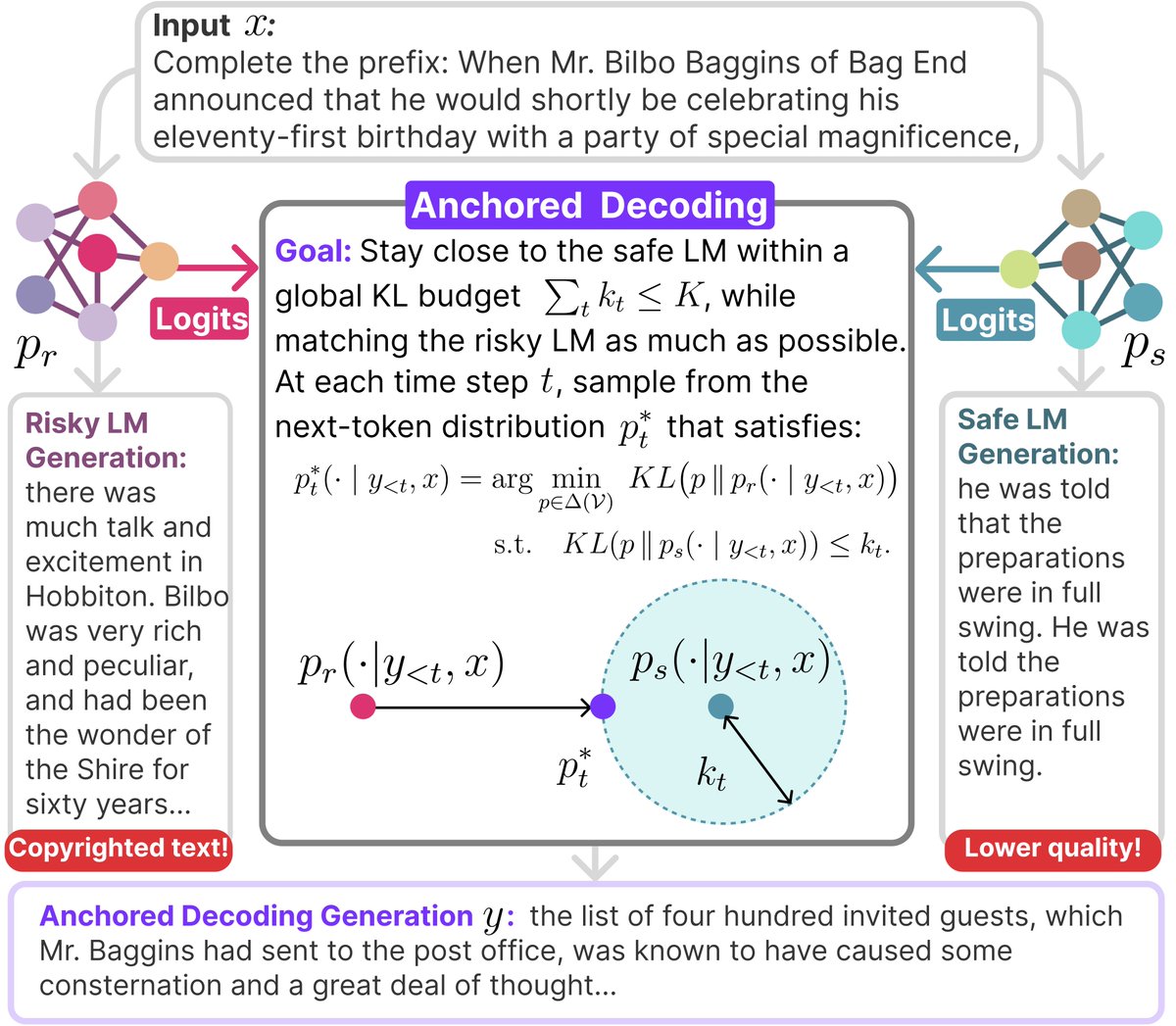
ALT Example generation with Anchored Decoding
4
19
51
9,021
17 Jul 2025
These results apply to a wide range of games, including strongly monotone quadratic games, Cournot and Bertrand competitions, and Kelly auctions. More details can be found in our paper: openreview.net/pdf?id=q6aopf….
1
1
401
17 Jul 2025
This paper is the months-long product of a great collaboration with Kshitij Kulkarni, Dmitriy Drusvyatskiy, and my advisors Lillian Ratliff and @sewoong79! We hope you enjoy -- there are a number of exciting open questions here to explore!
2
328
17 Jul 2025
Using techniques inspired from performative prediction and stochastic tracking, we create a hierarchy of interaction models that captures a principal's ability to use progressively more gradient information, which in turn determines the type of equilibrium achieved.
2
1
270
17 Jul 2025
A principal using a repeated gradient method that fails to account for decision-dependence converges to an approx. performative Stack. equilibrium, while an expensive zeroth order method yields an approx. Stack, equilibrium. For both, we provide finite-time convergence rates!
2
1
188
17 Jul 2025
Tomorrow, I'm excited to present "Finite-Time Convergence Rates in Stochastic Stackelberg Games with Smooth Algorithmic Agents", which addresses how a principal can influence the behavior of competitive learning agents! #ICML2025
📍West Exhibition Hall, W-817, 11:00 - 1:30
🧵👇
1
1
13
2,055
17 Jul 2025
Past work has explored these settings, but under several unrealistic assumptions, like i) knowledge of the agents' objectives, and ii) the stationarity of agent behavior. These works also only provide asymptotic convergence guarantees to game equilibria.
1
2
134
17 Jul 2025
Decision-making is often done not only under uncertainty, but also in environments subject to the actions of learning agents in competition with one another (e.g. crowd-sourcing, multi-agent systems). A natural abstraction for shaping these agents' behavior is a Stackelberg game.
2
2
142
16 Jul 2025
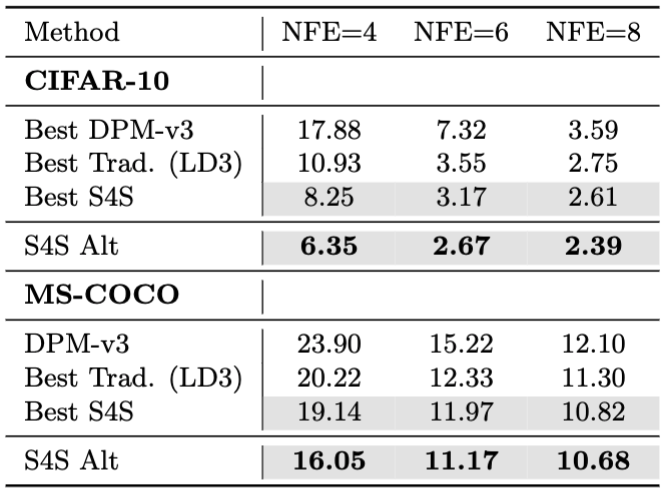
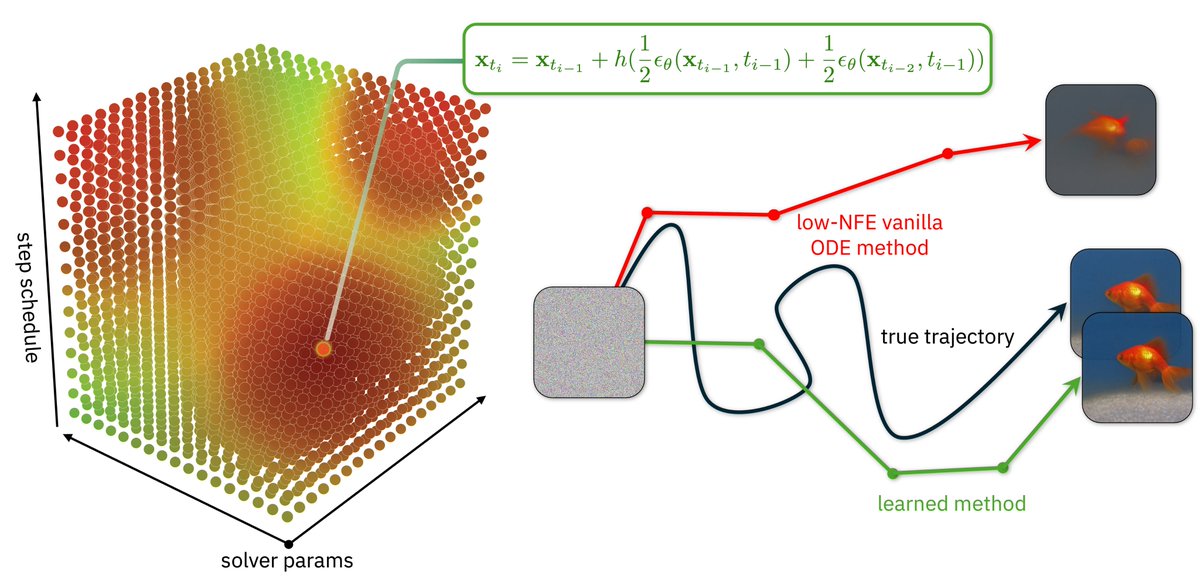
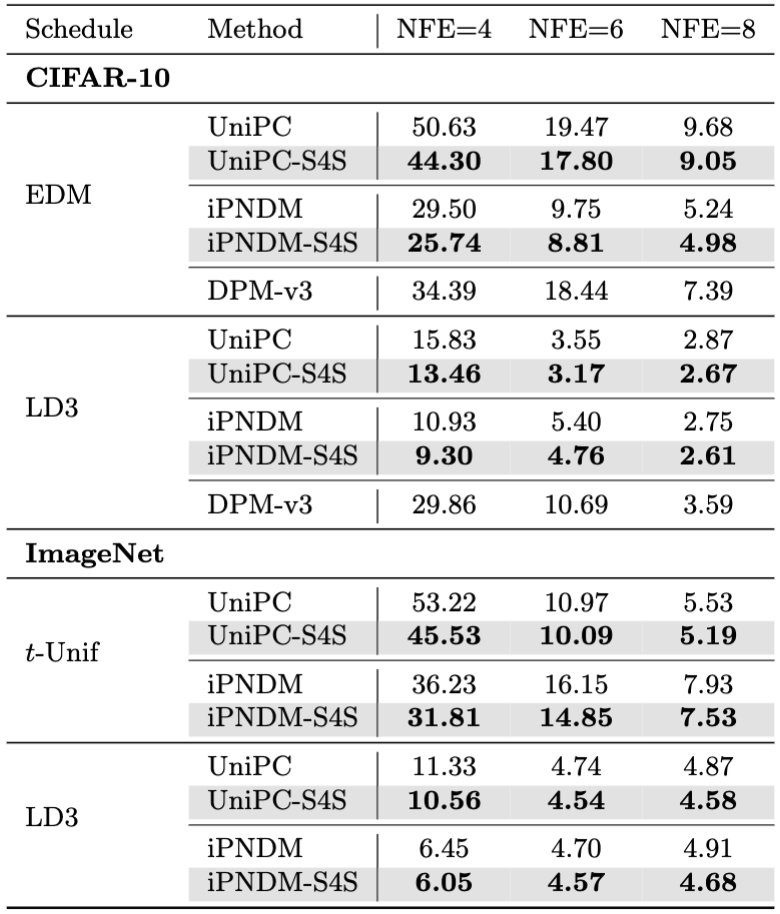
A bit of a belated announcement 😅 but I’ll be at ICML today presenting S4S, which enables few-NFE diffusion model sampling in <1 hour on 1 A100!
📍East Exhibition Hall, E-3210, 11:00 - 1:30.
Looking forward to chatting more about all things diffusion! #ICML2025
27 Feb 2025

Want to quickly sample high-quality images from diffusion models, but can’t afford the time or compute to distill them? Introducing S4S, or Solving for the Solver, which learns the coefficients and discretization steps for a DM solver to improve few-NFE generation.
Thread 👇 1/
2
19
1,835
Eric Frankel retweeted

23 Jun 2025
Web data, the “fossil fuel of AI”, is being exhausted. What’s next?🤔
We propose Recycling the Web to break the data wall of pretraining via grounded synthetic data. It is more effective than standard data filtering methods, even with multi-epoch repeats!
arxiv.org/abs/2506.04689

14
62
226
36,080
Eric Frankel retweeted

30 May 2025
Thrilled to announce that I will be joining @UTAustin @UTCompSci as an assistant professor in fall 2026!
I will continue working on language models, data challenges, learning paradigms, & AI for innovation. Looking forward to teaming up with new students & colleagues! 🤠🤘


103
54
667
75,935
Eric Frankel retweeted

27 May 2025
🤯 We cracked RLVR with... Random Rewards?!
Training Qwen2.5-Math-7B with our Spurious Rewards improved MATH-500 by:
- Random rewards: 21%
- Incorrect rewards: 25%
- (FYI) Ground-truth rewards: 28.8%
How could this even work⁉️ Here's why: 🧵
Blogpost: tinyurl.com/spurious-rewards
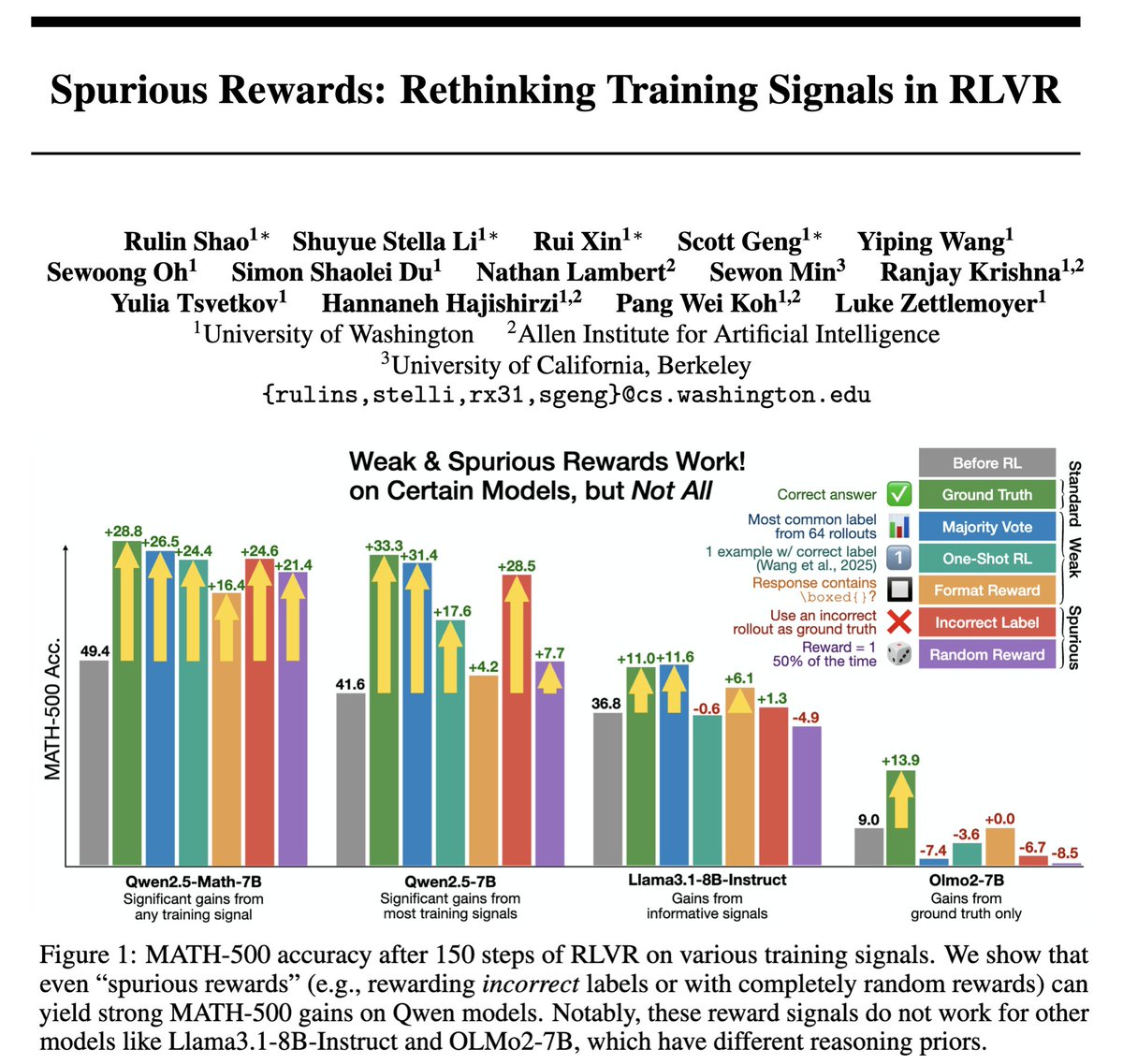
72
343
1,778
700,740
Eric Frankel retweeted

22 May 2025
Excited to share that our paper "Exploring How Generative MLLMs Perceive More Than CLIP with the Same Vision Encoder" is accepted to #ACL2025!
Preprint: arxiv.org/pdf/2411.05195
Thank @SimonShaoleiDu and @PangWeiKoh so much for your support and guidance throughout the journey!
2
14
49
9,842
Eric Frankel retweeted

23 May 2025
I'm excited to announce that I will join @WisconsinCS as an assistant professor this fall! Time to get to it.
28
7
236
25,130

LLMs naturally memorize some verbatim of pre-training data. We study whether post-training can be an effective way to mitigate unintentional reproduction of pre-training data.
🛠️ No changes to pre-training or decoding
🔥 Training models to latently distinguish between memorized sequences and their paraphrases
🔍 Effectively reduced verbatim reproduction while still recalling famous quotes when requested

1
32
103
17,337
Eric Frankel retweeted

13 May 2025
Think PII scrubbing ensures privacy? 🤔Think again‼️ In our paper, for the first time on unstructured text, we show that you can re-identify over 70% of private information *after* scrubbing! It’s time to move beyond surface-level anonymization. #Privacy #NLProc 🔗🧵

2
19
52
10,532
Eric Frankel retweeted

18 Apr 2025
Long Range Navigator (LRN) 🧭— an approach to extend planning horizons for off-road navigation given no prior maps. Using vision LRN makes longer-range decisions by spotting navigation frontiers far beyond the range of metric maps.
personalrobotics.github.io/l…
6
25
92
11,413

Our new paper (first one of my PhD!) on cooperative AI reveals a surprising insight: Environment Diversity > Partner Diversity.
Agents trained in self-play across many environments learn cooperative norms that transfer to humans on novel tasks.
shorturl.at/fqsNN🧵
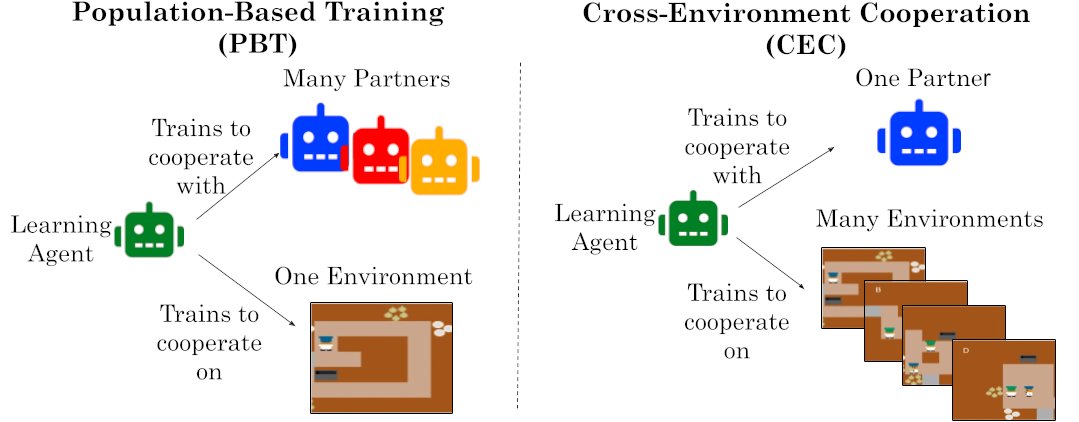
5
36
140
46,536
Eric Frankel retweeted

15 Apr 2025
🔭 Science relies on shared artifacts collected for the common good.
🛰 So we asked: what's missing in open language modeling?
🪐 DataDecide 🌌 charts the cosmos of pretraining—across scales and corpora—at a resolution beyond any public suite of models that has come before.

Ever wonder how LLM developers choose their pretraining data? It’s not guesswork— all AI labs create small-scale models as experiments, but the models and their data are rarely shared.
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
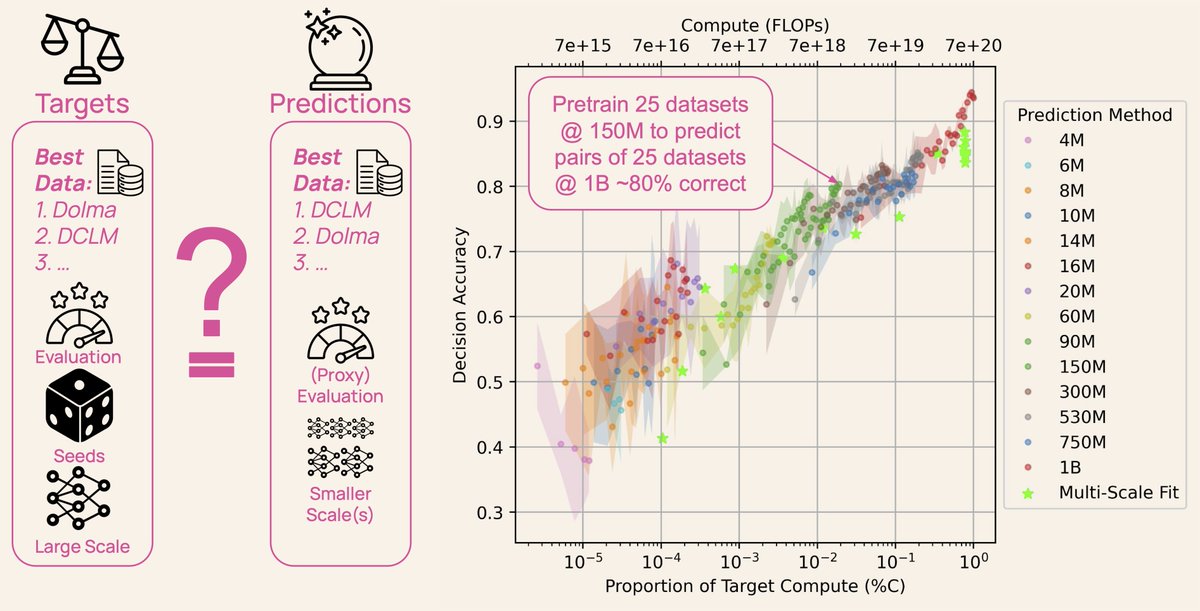
ALT Plot shows the relationship between compute used to predict a ranking of datasets and how accurately that ranking reflects performance at the target (1B) scale of models pretrained from scratch on those datasets.
4
48
93
12,820