
Joined July 2024
- Tweets 2,049
- Following 818
- Followers 993
- Likes 8,656
356 Photos and videos









Ahead of the curve.
Jun 9

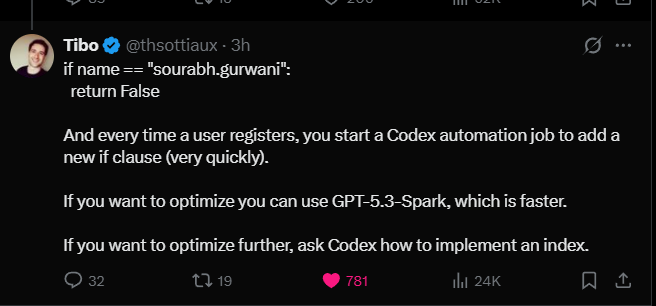
I do giant, nested, if-else staircases.
1
2
782

Jun 13
Run a local.... classifier. Export your traces to Hugging Face buckets with an open weight Privacy Filter. No GPU needed - runs directly on CPU. And you can fine-tune that filter to do as you need without anyone looking 👀. Give it a try: fast-agent.ai/guides/privacy…
4
198
Jun 13
I had Fable building a feature with /goal, hit the rate limit, went to bed and now Opus had to finish it.
Strange thing - since it launched in the now forbidden name of the model has been stuck in my head as Pathos.
2
109
Shaun Smith retweeted

Jun 12
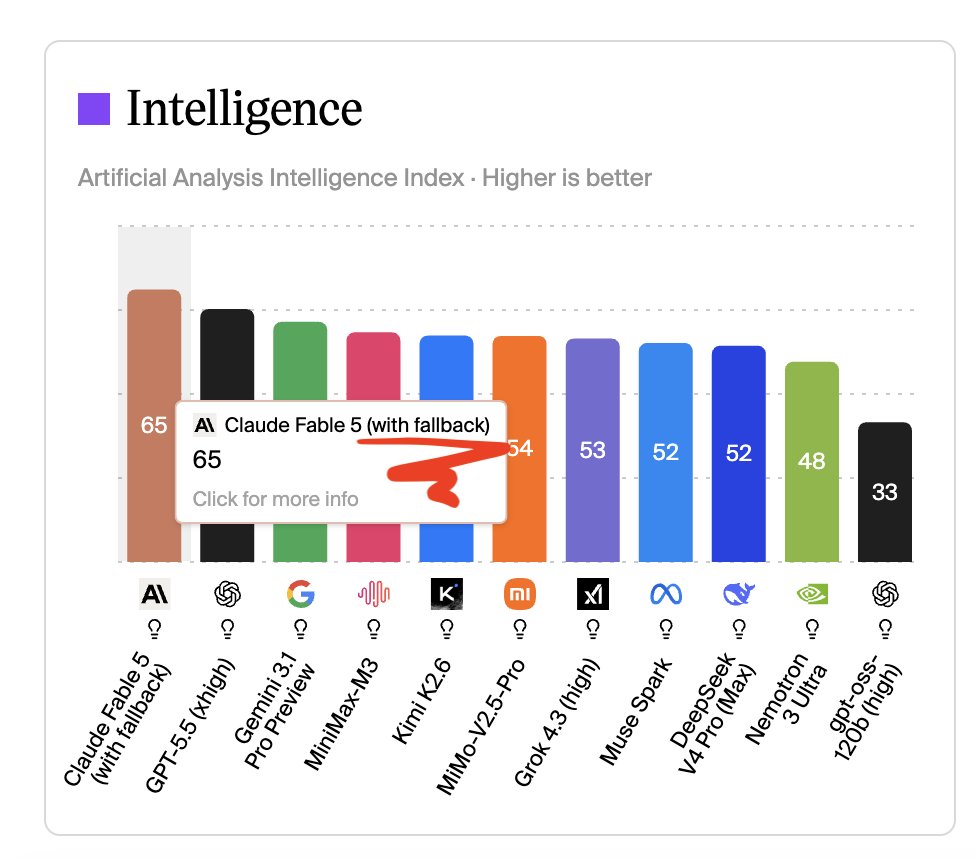
To people in the answers saying "but opus 4.8 is weaker so without fallback, the score would even be higher": this is not necessarily true because of how any benchmark - which is an average of queries - work and what is called "the fallacy of division".
Even if Opus 4.8 has a lower average score on AA than Fable 5, it actually performs better than Fable 5 on some benchmark that compose the index of AA, especially where there's high refusal rate of Fable 5 (ex GPQA Diamond, AA-Omniscience). The same would go if you'd take a single benchmark btw as it's always an average of queries and the fact that a model has a higher score on average doesn't mean they answer better on 100% of queries.
So it's possible that Fable with Opus 4.8 fallbacks is getting a higher score than pure Fable, even if Opus 4.8 is weaker on average.
The challenge is no one knows, except the API provider, which is the challenge I'm pointing out.
More details below from Fable (or Opus?) themselves!

Jun 12

This graph captures what’s broken about AI evals: they structurally favor closed-source APIs that can route, fallback, ensemble, and optimize behind the scenes with no transparency.
No offense, @ArtificialAnlys, but how is comparing one model to two models fair?
17
15
119
19,126
Jun 11
Is there a way to get Claude Code to reprint its last message (scrollback breakage is horrendous)?
2
2
194
Jun 11
It's wrong to use Fable to set remotes and create branches, right?
1
4
282
Jun 10
"I was wrong to suggest it" would be far more honest than "You were right to question it" 😐
45

Pydantic AI version 1.107.0 is out! 🎉
github.com/pydantic/pydantic…
1
13
741
Jun 10
Actually, there's a much simpler way - refuse their requests instead.
Apr 12
One way you could obfuscate model performance is by making benchmarks too expensive for hobbyists to run.
1
102
Jun 10
Guess what's in fast-agent 0.7.17.
3
131
Jun 8
Need to test something with Claude Code, update... good to the improvements in the details while I've been away.
2
2
136
Jun 7
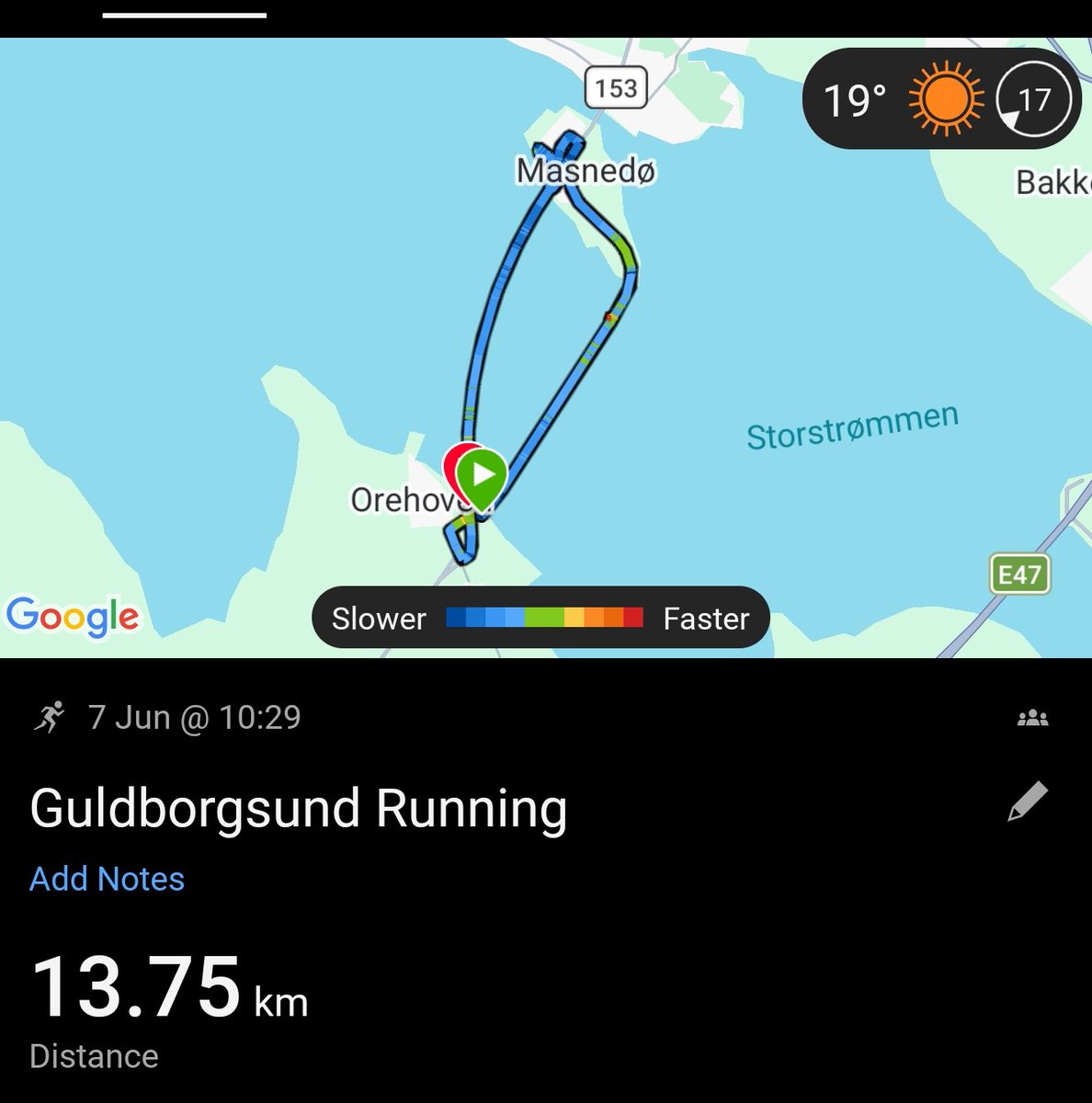
Nice 14k run over the old and new bridges between Falster and Sjaelland this morning. 🏃

3
123
Jun 5
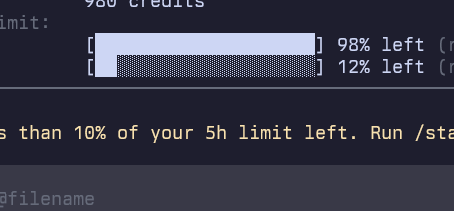
I promise to use these last few hours on ridiculous optimization jobs that no one in their right mind would attempt if they were paying properly for them. 🙏
Jun 4
Oh shoot, I think I was in the 15%.
1
163
Shaun Smith retweeted

The industry’s obsession about prompt caching is leaving a lot of genuinely impressive prompt engineering and performance improvements off the table.
8
4
77
11,970
Jun 2
spawn some sub-agents to to do a detailed review of the codebase, looking for duplication of intent, unnecessary spaghetti-style code, places where enums would be better than staircases, and other good pythonic practice that should have been adopted but wasn't. look for non-obvious defects (there are a couple) and fix by simplification wherever possible.
2
1
528
Shaun Smith retweeted

Jun 2
Very bullish on MCP comeback (yah I know it didn't actually leave us hah but you know) after listening in to @evalstate talk at @ainativedev
Good work and interesting stuff at @huggingface too. I need to spend more time on it
#ainativedevcon

3
1
11
1,018
Jun 2
About to kick off at AI Devcon - come say hi if you're here too 🤗
3
9
395