
I work on PyTorch at Meta. Chatty alt at @difficultyang.
Joined May 2008
- Tweets 9,048
- Following 1,465
- Followers 17,013
- Likes 1,255
160 Photos and videos










Edward Z. Yang retweeted

Jun 11
I've been telling people for 25 years that Jane Street is not interested in formal methods.
No more!
And we're actively hiring to form a new formal methods team!
29
74
1,070
120,430
Edward Z. Yang retweeted

I've spent months rethinking and rebuilding my programming languages course from scratch for the agentic coding era. I wrote myself a memo explaining what I'm doing. I figure others might be interested in the redesign, so here goes! Feedback welcome ofc.
docs.google.com/document/d/e…
19
37
320
23,653

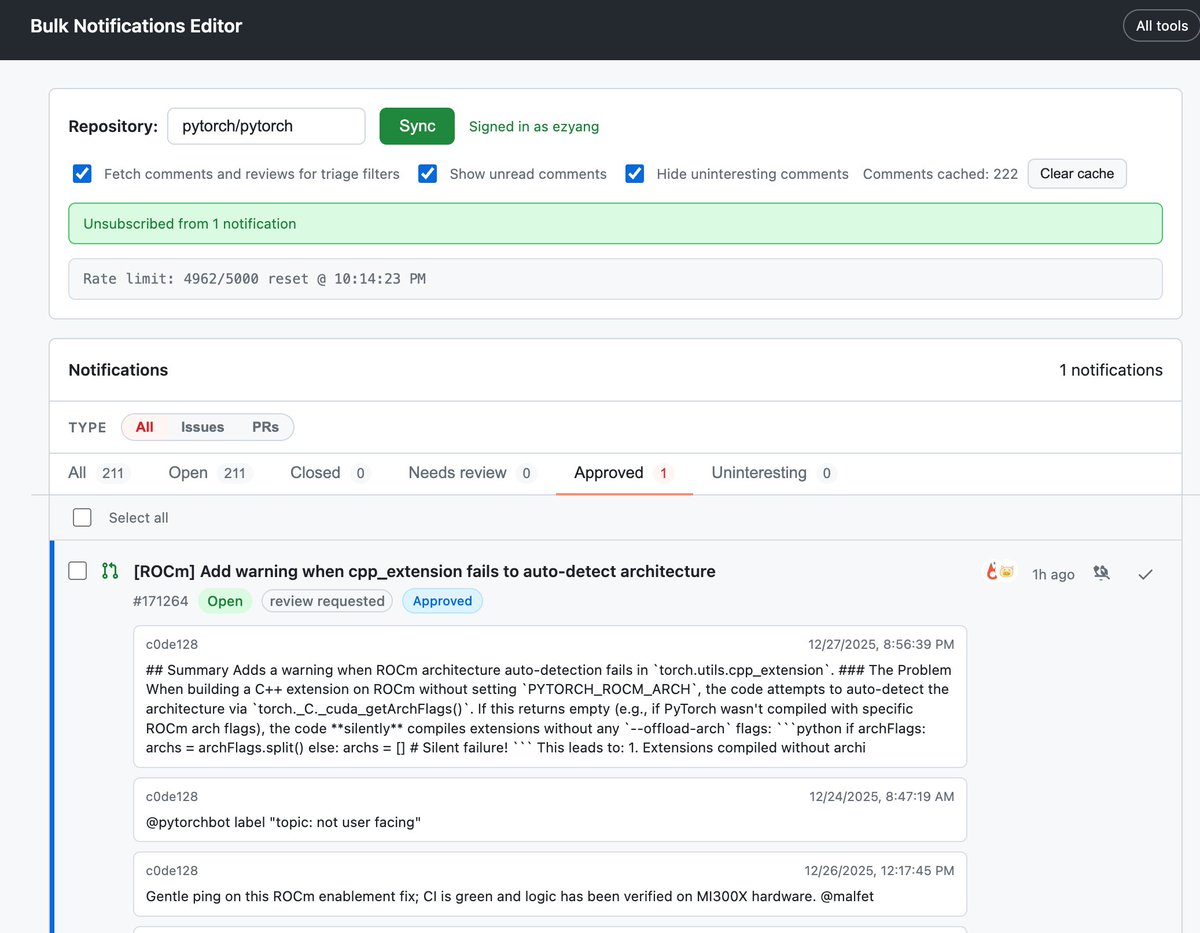
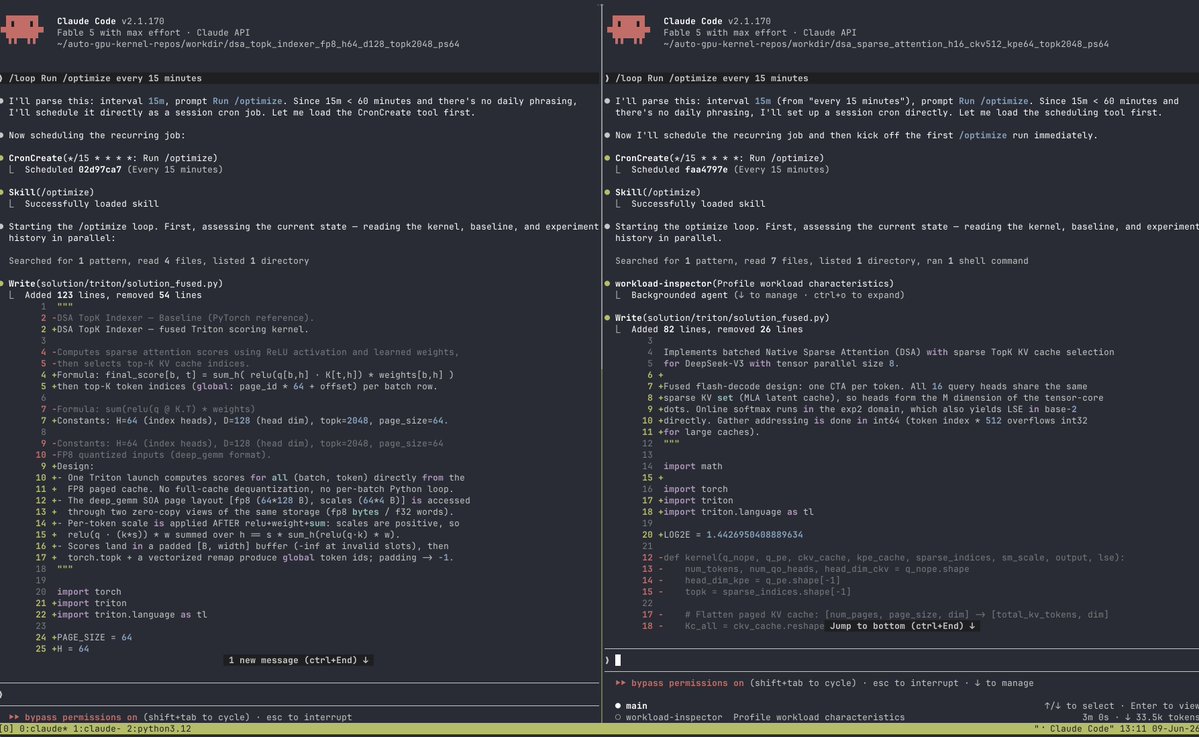
I've let Fable optimize GPU kernels autonomously using "auto-gpu-kernel" harness, if it joined the NVIDIA's competition today, it would have won 🥇 in 4/5 kernels against humans.
Fable can write Gluon kernels, do warp-specialization, use TMA tcgen05 etc.
(Speedup vs Opus 4.8)
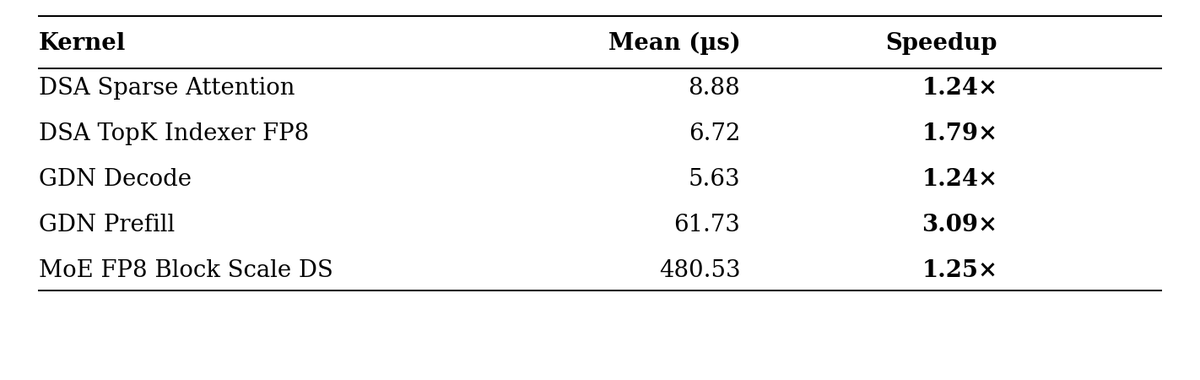

Testing Mythos for GPU kernel generation. I will test it under 3 kernels: DSA, GDN and MoE routing, let's see how it performs over Opus 4.7 that previously won the contest against humans for DSA track.
11
20
259
27,251

Jun 9
In the same way you should always "look at the data", I think you should also always "look at the source code"
10
9
104
7,847
Edward Z. Yang retweeted

Jun 3
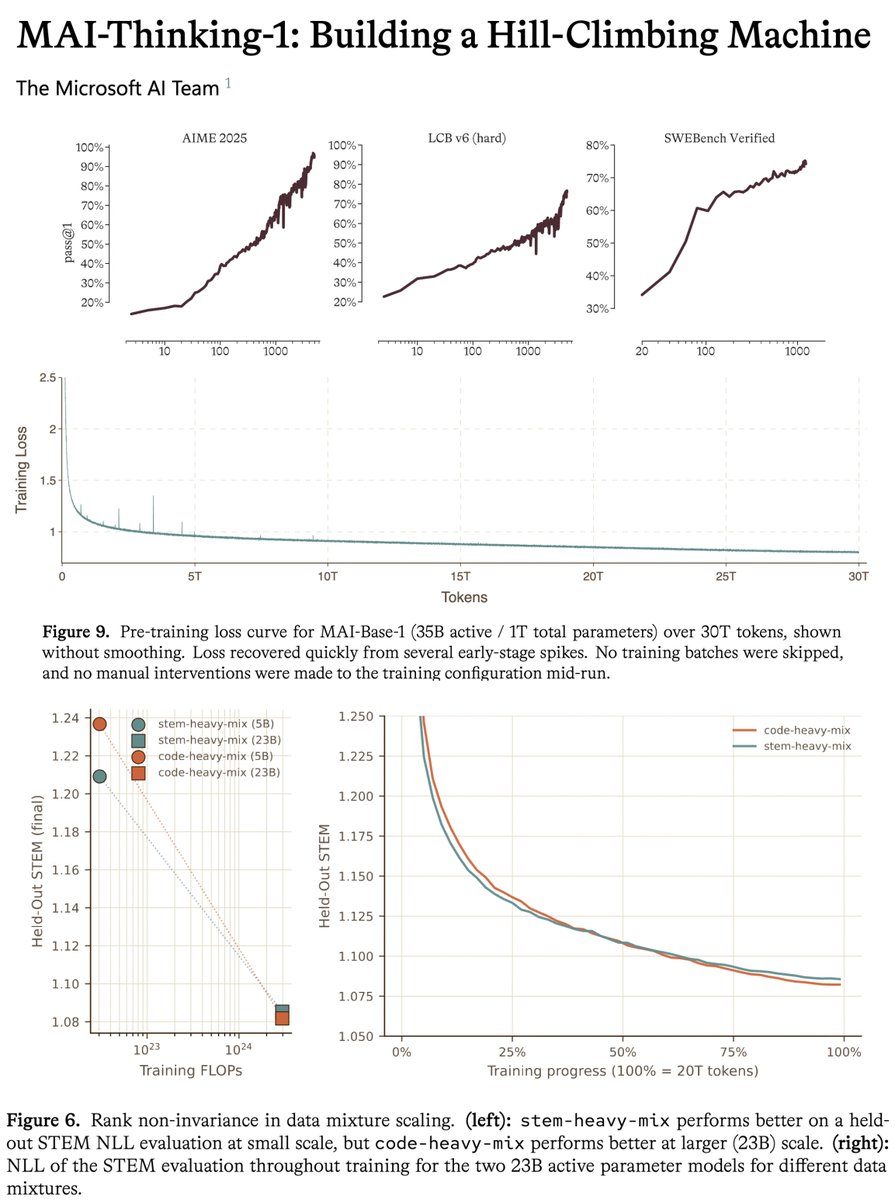
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵

Super excited to announce seven new world-class MAI models today. They represent what we consider a new era in AI designed to keep you in control and on the frontier.
First is our text foundation model, MAI-Thinking-1, exceptionally strong on reasoning and SWE tasks.
- It’s a 35B active parameter MoE with a 256K context window. Independent human raters on Surge prefer it for overall quality in blind side-by-sides versus Sonnet 4.6, and it’s achieved 97% on AIME 2025, the key measure of its general-purpose reasoning abilities.
- It's at 53% on SWE Bench Pro, placing it right alongside Opus 4.6 on one of the toughest coding benchmarks.
- And since we co-designed our models with our own silicon, MAI-Thinking-1 is optimized on our MAIA 200 chip. Benchmarking head-to-head against the GB200, we see 30% better performance per dollar as well as a 1.4x performance-per-watt gain when running our MAI models on the MAIA 200 end-to-end.
Next is MAI-Image-2.5 and its Flash variant. Two super strong models now at #2 on the leaderboards, surpassing the score of Nano Banana 2 on image editing.
Last for now is MAI-Code-1-Flash, our new inference efficient coding model, especially tuned for VS Code and GitHub Copilot CLI.
- Code-1-Flash achieves 51% on SWE Bench Pro, despite having just 5B parameters, putting it closer to Haiku in size but cheaper in cost.
All of this is the foundation for Microsoft Frontier Tuning. It lets you customize our models to create custom, company-specific agents that only you control. You can make our model, your model. Your data. Your agents. Your moat.
Early adopters are already seeing a difference. When we tuned our models for McKinsey’s tasks, MAI delivered the highest win rate, outperforming GPT-5.5 on quality, while being 10x lower on cost.
Also really excited to be collaborating with the amazing team at Mayo Clinic to jointly train a new frontier AI model for healthcare.
Our announcements today mark another milestone on the road to humanist superintelligence. You can learn more and about our other new models in our latest blog: microsoft.ai/news/building-a…

42
267
2,088
283,159
Jun 3
The PyTorch Conference NORAM talk submission deadline is June 7th! If you've got something interesting to talk about in PyTorch, send in your proposal! events.linuxfoundation.org/p…
3
12
1,631
Jun 3
The overall goal of this API is that, by default, *everything* is recomputed, and then you can very explicitly write out what exactly you want to save for backwards.
1
1
4
575
Jun 3
torch_remat is alpha software and definitely not production ready; we'll be working on making sure it works in real world use cases before making it more official. But I think it has some pretty interesting ideas already to think about.
1
1
3
489
Jun 3
Lots of credit to Natalia Gimelshein for the original conception of this API, and @albanDesmaison and Jeffrey Wan for review and the original checkpointing APIs this build up on.
1
3
462
Jun 3
I've been experimenting with a new activation checkpointing API, which we're calling torch_remat. We're still putting it through the paces, but I think it's already interesting enough to get some initial public feedback: github.com/meta-pytorch/rema…
3
7
92
3,960
Jun 3
It is particularly designed for codebases that make a lot of use of custom autograd Functions, which is common in advanced PyTorch codebases that need more control over what is saved for backwards compared to what basic PyTorch operations provide.
1
1
8
725
Jun 3
torch_remat most directly competes with SAC, where you specify a policy function which specifies, on a per operation basis, if you want to save or recompute it. torch_remat flips this on its head: instead, you specify if you want to save/recompute on a per op call basis.
1
1
8
931
Jun 1
New devlog post from yours truly: When does fragmentation occur in the CUDA caching allocator? docs.pytorch.org/devlogs/eag… -- this post is LLM authored but I heavily prompted/edited, and Natalia also helped fact check.
8
14
136
11,006
Jun 1
I ended up prompting it this morning because I was helping some users who were still confused about their fragmentation problems and didn't realize they should use expandable segments. So nothing is here is new, but trying to spell it out more clearly for the masses!
1
1
5
2,228
Jun 1
(Natalia helped fact check, but if there are still errors in the post, they are mine! Let me know if you see any.)
2
1,610
Jun 1
One of the reasons some footguns in PyTorch persist is because it would be BC-breaking to change the defaults. I'm kind of wondering if something like language editions (similar to C 20) could help us batch defaults updates and make them more accessible.
4
2
57
9,391
May 31
At our most recent PyTorch offsite we had a really lively discussion about AI agent usage in the project. I did a writeup of some of the resolutions from this conversation: docs.pytorch.org/devlogs/ai-… It's by no means final; we're figuring things out too!
3
16
173
13,093
May 28
While AI coding has lowered the cost of writing code, many things you might be interested in rewriting still have a surprisingly large feature surface. For example, there is more to a programming language than just a compiler: there's also profiling, debuggers, packaging, etc.
3
49
3,617
May 28
Similarly, there's more to a deep learning framework than kernels. Autograd, CUDA graphs, allocators... I do not doubt that with enough time, tokens and expertise you can do it! But it takes quite a lot of work to put all of this feature set together.
1
1
27
1,404