
Sequence modeling toolkit for @PyTorch
Joined May 2020
- Tweets 12
- Following 11
- Followers 1,576
- Likes 6
Photos and videos
fairseq retweeted

21 Dec 2021
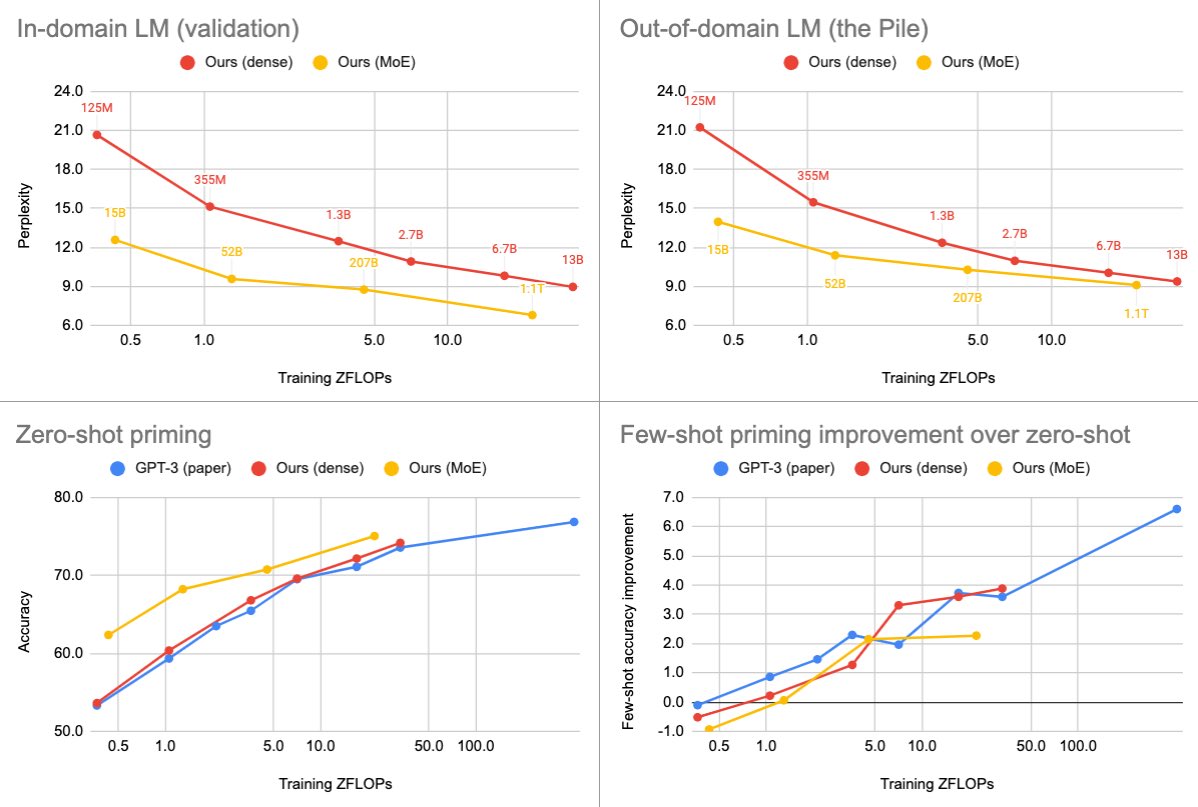
We are releasing a family of dense and MoE language models with up to 13B and 1.1T parameters. We find that MoEs are more efficient, but the gap narrows at scale and varies greatly across domains and tasks.
Paper: arxiv.org/abs/2112.10684
Models & code: github.com/pytorch/fairseq/t…
4
24
93

Models and code available in fairseq: github.com/pytorch/fairseq/t…

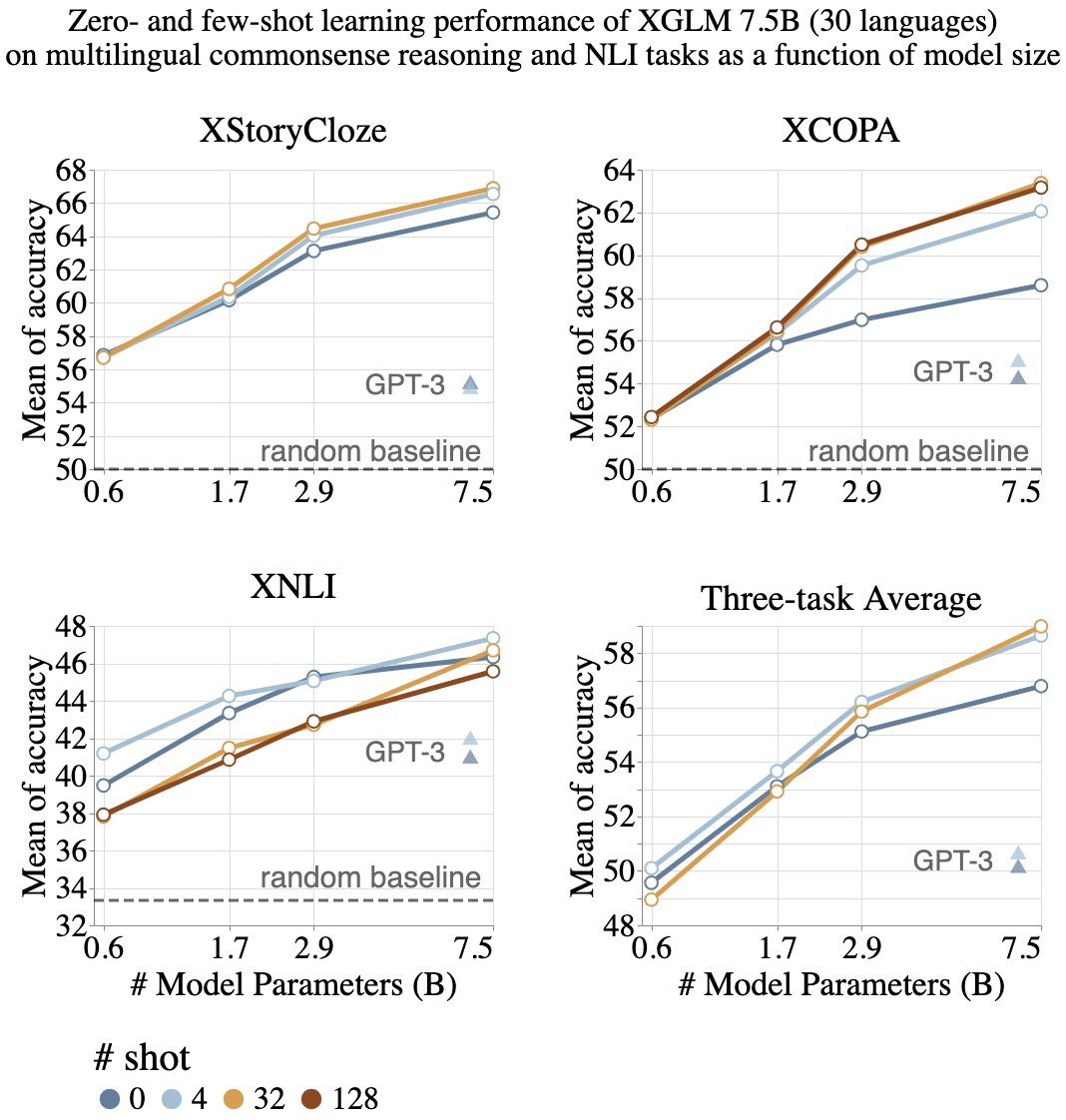
🌍Few-shot learning beyond English🌏
📢 Announcing XGLMs, a series of multilingual autoregressive languages models setting new SoTA on few-shot learning and outperforming English-centric models (e.g. GPT-3).
Paper: arxiv.org/abs/2112.10668
Models and code: github.com/pytorch/fairseq/t…
9
Mixture of experts training in fairseq is now 40% faster thanks to Microsoft's Tutel library!
Blog: microsoft.com/en-us/research…
Fairseq code: github.com/pytorch/fairseq/t…
Tutel code: github.com/microsoft/tutel
3
17
fairseq retweeted

9 Sep 2021
We’re introducing GSLM, the first language model that breaks free completely of the dependence on text for training. This “textless NLP” approach learns to generate expressive speech using only raw audio recordings as input. Learn more and get the code:
ai.facebook.com/blog/textles…

14
333
1,220
fairseq now supports CPU offloading and full parameter optimizer state sharding via fairscale's FullyShardedDataParallel module. See our tutorial to train a 13B parameter LM on 1 GPU: fb.me/fairseq_fsdp
8
58
We just released 0.10.0, which is our last significant release before 1.0.0 when we will migrate to @Hydra_Framework. Changelog: github.com/pytorch/fairseq/r…
2
17
fairseq retweeted

5 May 2020
Facebook AI Research's sequence modeling library @fairseq has made it's twitter debut. Please follow for latest updates.
2
10
41

Fairseq includes support for sequence to sequence learning for speech and audio recognition tasks, faster exploration and prototyping of new research ideas while offering a clear path to production. bit.ly/2WfP85X
1
35
119
roberta = torch.hub.load('pytorch/fairseq', 'roberta.large')
29 Jul 2019

Facebook #AI’s RoBERTa is a new training recipe that improves on BERT, @GoogleAI’s self-supervised method for pretraining #NLP systems. By training longer, on more data, and dropping BERT’s next-sentence prediction, RoBERTa topped the GLUE leaderboard. ai.facebook.com/blog/roberta…
83
340
fairseq now supports the training of gated convolutional language models (arxiv.org/abs/1612.08083). It can train a Google Billion Word language model on 128 GPUs in less than a day.
1
10
35
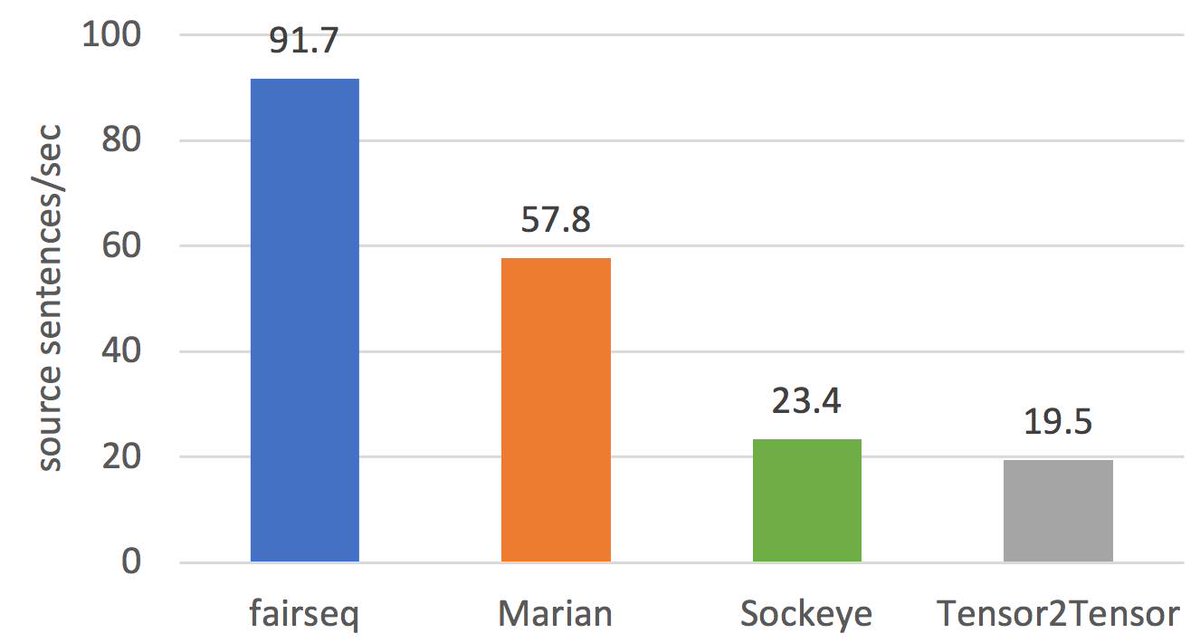
FairSeq Toolkit - Major Update
- Distributed Training
- Transformer models (big Transformer on WMT Eng-German in < 5 hours on DGX-1)
- Fast Inference: translations @ 92 sent/sec for big Transformer
- Story Generation
Read more at Michael Auli's post: facebook.com/photo.php?fbid=…
4
36
132
fairseq retweeted

18 Sep 2017
Fairseq, now in PyTorch!
The open-source convolutional sequence-to-sequence engine from FAIR is now available in... fb.me/1gCPauX6V
1
127
301