
vision models team lead @ sarvam.ai | previously microsoft research, everwell, harvard university
Joined February 2025
- Tweets 125
- Following 335
- Followers 385
- Likes 190
20 Photos and videos







krishna retweeted

May 29
Unlocking document intelligence for India scale efficiently!

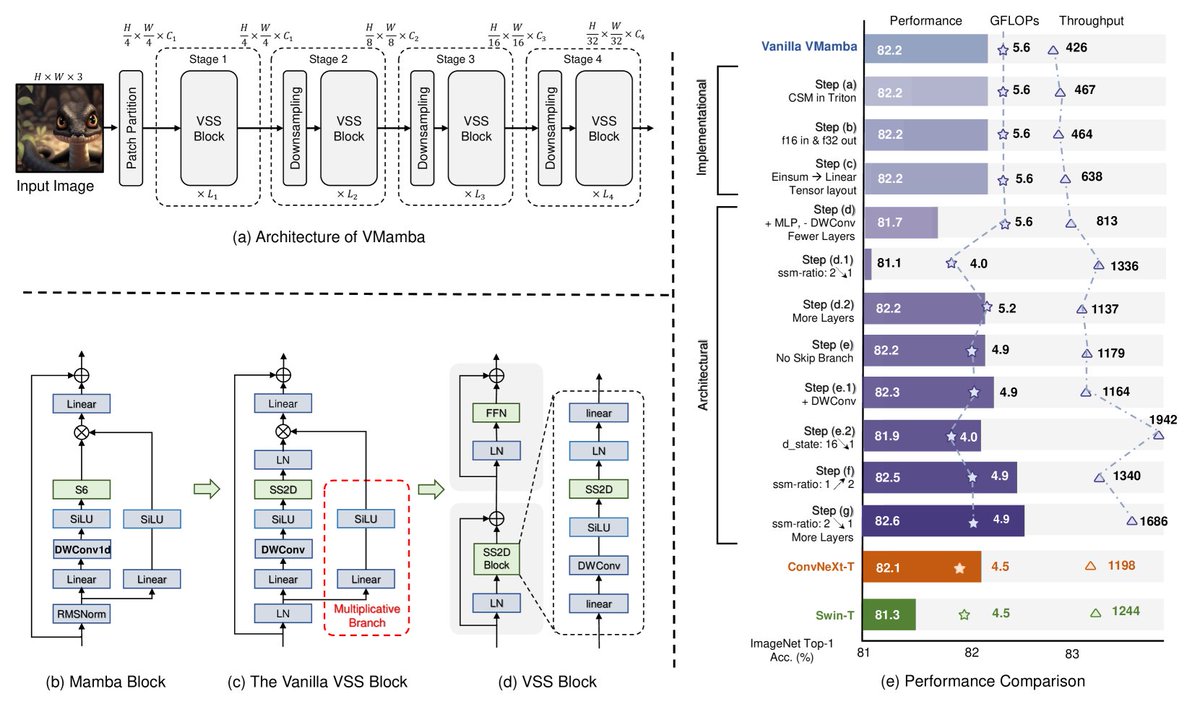
Earlier this February, we launched Sarvam Vision, a vision-language model for document intelligence.
Today, more than 35 million pages are being digitised through the Sarvam Vision API by developers and partners.
Since launch, we've made it significantly more efficient to serve at scale. We’re now passing these gains on by reducing the Sarvam Vision API price from ₹1.5 to ₹0.5 per page.

2
3
124

May 29
Sarvam Vision, our SOTA document intelligence model, is now 66% cheaper!
since launch, thousands of developers have digitized millions of complex documents with it. we've optimized our serving stack to scale with that demand - and we're passing on all of the gains to users.
excited to see all that you build with the model. @SarvamAI @SarvamForDevs
Earlier this February, we launched Sarvam Vision, a vision-language model for document intelligence.
Today, more than 35 million pages are being digitised through the Sarvam Vision API by developers and partners.
Since launch, we've made it significantly more efficient to serve at scale. We’re now passing these gains on by reducing the Sarvam Vision API price from ₹1.5 to ₹0.5 per page.
1
13
710
May 28
eagerly waiting for series z and agi - whichever comes first 😂
May 28

We've raised $65 billion in Series H funding at a $965 billion post-money valuation, led by @AltimeterCap, Dragoneer, @Greenoaks, and @sequoia.
This investment will help us advance our research and expand our capacity to meet growing demand for Claude.
1
63
May 28
the world of computer use agents (CUA) is gaining popularity. most frontier labs now have CUAs in some shape or form.
SOTA on CUA is established using leaderboards - like OSWorld, AndroidWorld, etc. these include a battery of tests around click, tap, type, scrolll.
things seemed good until i read this paper from Meta SI Labs. the team ran an experiment on the leaderboard - almost a prank!
they took a CUA and let it solve a task; just once. they recorded every action into a 1mb file and showed a simple automation outperforms frontier CUAs.
how so? performance in this domain essentially comes down to the test env. if every test begins from the same intial condition, then there is no perception needed. you dont need to see anything, or reason.
mathematically this makes sense too: in a deterministic world, a simple automation or a complex agent system both yield the same result.
the paper proposes a solution: randomize everything that can be randomized. each test should be executed in a fresh environment - a new sandboxed phone, new data, theme, UI state, so there is no gamification happening.
read more: arxiv.org/abs/2605.08261
75
May 25
stay tuned for some really exciting updates to Sarvam document intelligence stack 🔥
May 24

Had a lot of fun attending @pratykumar's talk this week at Stanford.
This is difficult engineering, done right at @SarvamAI!
Also, got to know they will expand presence in the Bay Area-- All the best! :) @MohapatraHemant

1
1
179
May 24
these are getting ridiculously good
May 24

Anthropic onboarding day: Michael Scott introducing Karpathy like he just signed Wemby in free agency.
2
213
May 23
agree broadly with the thesis, but it's incomplete. data scarcity is only part of the problem.
llms didn't learn to reason because the internet wrote reasoning down. chain-of-thought on the web before 2023 was minimal. they learned when post-training started using verifiable rewards (a math grader, a code runner, a unit test) to score intermediate steps.
vlms have a similar gap, imo. there is no visual analog of the code runner. no verifiable check that asks "did the model actually see X in an image, or did it just say X based on the image context."
if agentic vision were to take off, we should be build methods for verifiability. once a vision rl loop has a check for grounding, the diff vision skills become a normal post-training problem with rewards.
May 22

Since founding Moondream, I've watched language models achieve AGI, while VLMs aren't close to human-level visual reasoning. Here's why. 🧵
1
2
112
May 21
juxtapose elon's hiring call with the mass layoffs from meta. fascinating how the ai world is balancing itself out 😬
May 21

How founders need to hire in 2026. Though I'm curious how Elon is going to grok through the 10m applications while maintaining context to stack rank 😂

143
May 21
ASR rockstars!

1
109
krishna retweeted

May 20
Building ASR for India is less about benchmark numbers and more about what breaks in production.
This Thursday, I'm sitting down with @sehaj__virk , @adityam0309 , and Dhruv to unpack Sarvam's Saaras-V3 and how it handles real-world Indian speech.
We’ll cover:
⚡ Realtime vs. Streaming vs. Batch (Voice agents to call analytics)
🗣️ 22 languages, dialects, and code-mixing
👥 Multi-speaker audio and overlapping speech
If you're building voice products for India, bring your hard questions.
📅 Thursday, 21st May | 5:00 PM IST
📍links.sarvam.io/speech-to-te…
May 19

A must attend webinar on what to build with our SoTA speech recognition model and the recent upgrades on diarisation and accuracy.
1
3
21
866
May 19
quite an interesting read. shows how current agent RL can be wasteful. it updates policies based on sparse action rewards but masks out the env response (terminal outputs) in the loss updates. essentially this discards ground truth signal about how the underlying state actually changed.

1
1
3
295
May 19
the proposal is to build a join objective: RL on actions cross-entropy on env observations. by predicting the terminal output for each action, there is implicit learning toward a world model. it is sample efficient too.
1
49
May 19
some open questions though:
- is terminal output sufficient in general to achieve complete understanding of the env? what happens to silent processes?
- how does this scale with long-horizon tasks? won't you hit memory issues, slowing down training?
- does prediciting terminal text enough to learn cause and effect required for world modeling?
40
May 18
1/ been trying to understand the VLA lanscape lately, and came across this recent, neat paper discussing how thinking works across vision and text.
vision-language-action policies have improved one design choice at a time: latent state, text chain-of-thought, world-model keyframes. each individually optimized, and compared in isolation. when a new VLA wins on a bench, it's hard to tell which choice did the work.
arxiv.org/abs/2605.00438
1
95
May 18
9/ a bigger implication if this scales: VLA policies probably don't need clean human-written plans during training. IVLR's plans are pseudo-labels from segmenting demo videos and captioning each stage with a VLM. the policy learns from those noisy labels and still hits 92.4.
3
32
May 18
10/ what LIBERO-Long doesn't tell us:
- does plan-once hold past 10 steps in unstructured scenes?
- does interleaving still help when predicted keyframes don't match what the robot sees?
- is text image the right split, or just one good split?
worth a read: arxiv.org/abs/2605.00438
22