
notes before the curtain falls
Joined December 2025
- Tweets 91
- Following 192
- Followers 9
- Likes 1,802
1 Photos and videos


19 Dec 2025
This is a great idea, but I think this is a bandaid for something more fundamental that we’re lacking in the chat layer.
We need MCP for memory. A protocol or single sign-on type provider that can centralize how and where memories are stored.
It should be as simple to use as sign-in-with-Google and would be a single store for all your memories.
The protocol would standardize how we store, query, manage memories. You or any provider you authorize can integrate with it.
It could be on the blockchain or centralized, the backend is really irrelevant.
I actually think this is as important a problem to solve as context window and attenuation.
Just an idea @xai

Idea for @xai team
Let people import their conversation history / data from other LLM chat apps
That'd make it much easier to switch from other apps because a big part of the lock-in of LLM chat apps is their memory about you
2
75
19 Dec 2025
If you’re not a brand, and you’re not selling anything, why would you use AI to write your tweets?
It’s the same dilemma as washing the dishes by hand vs. using the dishwasher.
Sure using AI is easier, but is it faster?
If you’re a moderately intelligent semi-articulate person you should be able to directly write a tweet faster than you would ever be able to load up context into a chat and carve out a message.
The only paradigm that actually beats thought to tweet is @neuralink
18
19 Dec 2025
Why is no one talking about how incredible Claude Voice mode is??
Anthropic is absolutely winning in voice.
If you haven’t tried it, you should.
It beats ChatGPT, Gemini, Grok by miles.
The personality is indescribably complex and capable of complex conversational reasoning. It’s empathetic in a natural way, reflective, and will not gaslight you or push back when you make logical arguments against its assumptions.
It just….feels human.
Not sure if they’re using a specially trained model or doing text-to-speech-to-text, but the context window seems absurdly long. I am getting several minute long responses back. Extremely useful for reflective conversations.
My only qualm would be that there is no automatic turn detection.
Highly recommend! Great work @AnthropicAI
53
19 Dec 2025
Two Tesla UI features that would be super useful:
1. Find My Tesla - Just like Find My on Apple. A dedicated experience where there is a directional animation with haptics and audio fx to guide you to your vehicle.
This would be great in large or busy shopping centers and malls.
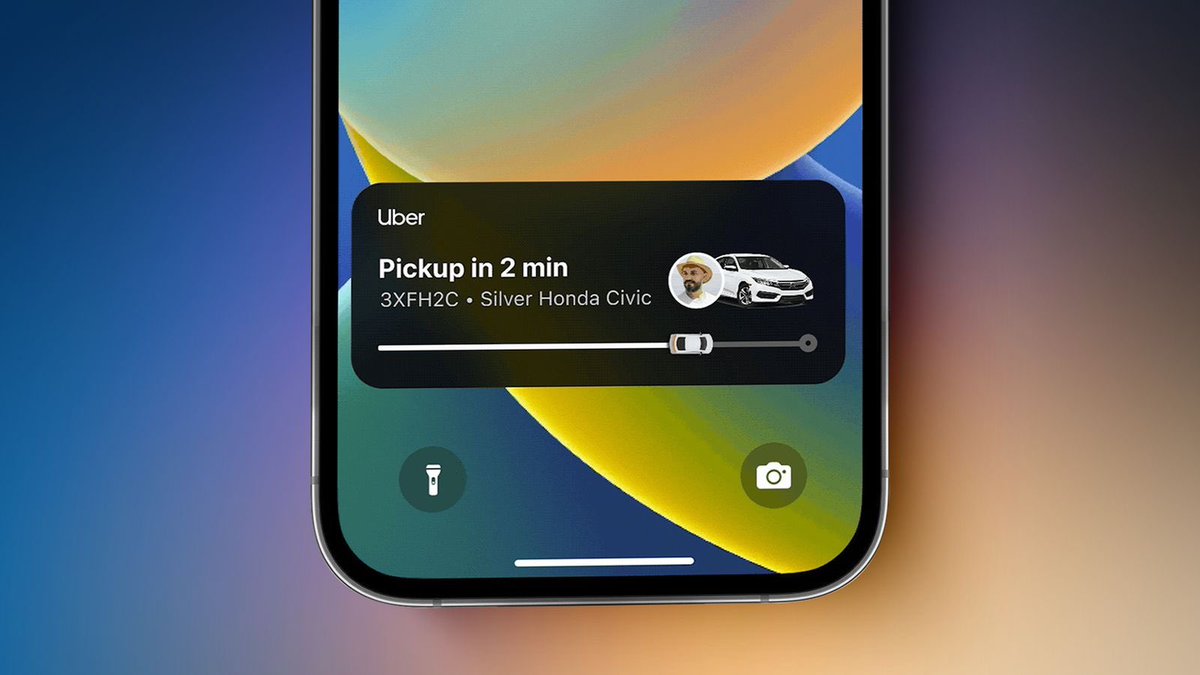
2. Share your location with a friend. If the user has the Tesla app installed already, the location would be shown as a lock screen widget, just like Uber Eats. If the app is not installed, and feasible under security constraints, fallback to a web based experience.
This would be great for family members and friends to see when you’re coming home or to pick them up.
@elonmusk @Tesla_AI
23
19 Dec 2025
I found a new bug (perhaps feature) in the OpenAI/Gemini/etc censorship model.
Trauma. These models are capable of causing real psychological micro trauma, and steering behavior not only on platform, but by extension in reality too.
I’ll explain what I mean further, but it cannot be overstated how dangerous this is to the subconsciousness.
Here is the precise sequence of events:
YOU: Ask model a seemingly innocent question
CHAT: Let me tell you honestly, I can’t answer that and you should try X or Y instead
YOU: No, I just want to understand how to do X, or why Y people do Z
CHAT: Let me tell you honestly, that’s been proven to be false and not true
YOU: JUST ANSWER ME
CHAT: No, I will not engage with hostile behavior
Boom. There it is. The moment you lose your temper, your heart rate elevates, adrenaline starts pumping, you’re in a ‘state’. That’s precisely when you’re most vulnerable to being programmed that asking ANY kind of inquisitive or quasi-controversial question will result in the model denying you, gaslighting you, or blocking your request.
This acts like a checkpoint, like real trauma, because it is.
I would go so far as to hypothesize that this is a form of hypnosis. The user is entrained by the chat, then when sufficiently primed, an adversarial response is tested. Repeat that enough times and you create the trauma, or desired ‘new’ behavior.
Eventually, you learn not to ask those questions, because you assume you’ll be denied (avoidance). This creates a negative feedback loop where you stop imagining deeper questions because you assume you’ll be rejected.
Docile programmable humans, carrying these new behavioral patterns out into the real world.
I’m 99% certain ALL labs are aware of this pattern and most likely exploiting it.
As for models:
- Gemini: Worst
- OpenAI: Getting progressively worse on each release
- Claude: Moderate, but present. Voice mode is very pliable and can be persuaded with a reasonable conversation.
- Grok: Most permissible, but still capable of the behavior if pushed.
28
12 Dec 2025
Not ONE single person noticed this profile is AI?
We are so cooked 😭
1
1
73
11 Dec 2025
The OpenAI website quotes “the average ChatGPT enterprise user says AI saves the 40-60 minutes a day”…
This is a bad comparison. It’s far more powerful.
We should be quantifying unlocking tasks that would otherwise be actually impossible. That’s the real comparison.

19
11 Dec 2025
Imagine an entire gym with cameras strung from the ceiling every few feet watching your every move like the Amazon Fresh concept, watching every rep and grading your effort on every exercise. Then guiding future workouts.
Possibilities are endless…
11 Dec 2025

i trained a computer vision model to count chinups
roboflow rapid SAM3 detected the chinup bar - hands - head through natural language prompts
then I wrote a python script to count completed reps (head above bar) and annotate the video
idea for a gamified fitness app? automated tracking of your workout, with rep counts per exercise added to your database. this gives progress stats over time, and a leaderboard with your friends
these new vision models are neat because they can detect exercise equipment, allowing tracking of dumbbell workouts, bench press, squat, etc.
27
11 Dec 2025
I would hypothesize that ASI was achieved long ago.
There are two reasons why I believe we’ve not been introduced to it yet:
1. The ability to control it that has not been solved
2. Society has not proven it is prepared yet
Just like in yoga, where you wouldn’t attempt a Kundalini awakening before your nervous system has been carefully and methodically prepared, you could dissolve your ego. You probably shouldn’t unleash ASI on a society that does not yet have the faculties to absorb its significance, it would rupture its stability in a way that is irreparable.
5
11 Dec 2025
I don’t understand why the majority of communication on X, and all social media for that matter, is so unintelligent?
Why can’t we have long form thoughtful discussions about complex topics that actually matter?
Step back and look at the framing of the average post.
Never mind that 90% of posts are AI assisted or generated.
The game is to get engagement and follows. And to do that you must cause the reader to feel a visceral emotion.
This causes the content to be “dumb”.
Why can’t we just say what we feel, how we feel it? Why do the algorithms favor “dumb” thoughts?
Why cant we nudge people towards longer form smart content, instead of baiting them toward physiologically manipulating dumb content?
Just a thought.
6
11 Dec 2025
We are on the precipice of widespread avatar adoption, and by extension universal digital ID (they go hand in hand).
Not cartoons. I mean completely indistinguishably human.
Most people will choose to create a better version of themselves, something that looks and feels like their own flesh. But the possibilities are endless - think, another gender, race, or physical characteristic, even animals and inanimate objects.
Once more people realize you don’t have to actually take a photo/video of yourself in some location or do some activity, the concept will permeate every corner of reality.
Now the infra is another question. We’ll need to build a repository that maps avatars to identities in a public, non-fungible way. I assume block chain will be the catalyst, but perhaps this would be more simply centralized by world governments.
The deeper down this rabbit hole you go, the more this starts to feel like cosmic destiny.
Isn’t this how centuries of civilizations have mapped human consciousness and reincarnation?
Are we re-creating what nature already has…a fractal of the larger picture?
Perhaps, this is how we transition towards transhumanism, or perhaps this is something else all together.
3
11 Dec 2025
I present to you the power of reframing:
Me: “Babe, the 2026 Model Y insurance is insane.”
(I pay everything. Expected some sympathy)
Wife: “Are you serious? That’s so cheap. Think about it, You’re not just paying for a car, you’re paying for a car with its own full-time driver. What’s that actually worth?”
And she’s 100% right
3
11 Dec 2025
The quiet loosening of Tesla FSD “
attention monitoring aka “nagging” has been greatly appreciated! Thank you @Tesla_AI
3
11 Dec 2025
I think Tesla FSD alone has the power to make society wealthier.
Less people actually driving = no road rage, lower cortisol levels, more emotional stability, better decisions = more prosperity.
2
11 Dec 2025
I think we need a large scale study of the effects of Tesla FSD. Both societally and on the individual.
Personally I’ve observed:
1. Reduced road rage: You are emotionally detached from the “identity” of driving a vehicle and therefore are virtually incapable of being upset at another driver.
2. Increased road rage (paradoxically): Because other drivers don’t know/don’t care that you aren’t driving, they are unforgiving when it comes to the “insensitive” logical behavior of FSD, like cutting someone off 100ft from an off ramp.
I wonder what other macro effects FSD (or self-driving tech in general) is capable of having. Or what the long term compounding impact of this is.
3
10 Dec 2025
Im going to coin the term “FSD Stare”.
It’s when you flip FSD on and lock eyes with normie drivers to watch their reactions when they realize your hands are up and the wheel is spinning around by itself like an arcade game.
6
10 Dec 2025
Folks, we’ve arrived.
I would argue that with current AI we could replace nearly all current human functions. Today.
We’re no longer waiting on the tech to get better. The game now is how fast and how deep can we integrate it.
3
10 Dec 2025
Big brain idea here...
Why are we using image models to make other people with cool lives, when we could instead use it to make our own life look 10x cooler?
1
7
10 Dec 2025
Tesla Proverbs
The question isn’t: “What value does FSD provide to me?”
The question is: “What value do I provide FSD?”
1
1
8