building the last personal agent @thinkwithalma
Joined July 2021
- Tweets 1,330
- Following 397
- Followers 547
- Likes 2,834
102 Photos and videos







Pinned Tweet

Founders keepers, losers weepers
1
1
2
696
Whos training who

JUST IN: India’s Wipro is launching a Claude AI center in Bengaluru & plans to train 10,000 employees on Anthropic’s models.
1
39
Nischith Shadagopan M N retweeted

Jun 15
We released Sonic-3.5 and Ink-2, the #1 streaming models for text to speech and speech to text you can use in your voice agents today.
New architectures enable new frontiers for speed and quality.
We're now the only provider to have #1 models for both speaking and listening.
708
604
2,513
6,659,534

Nischith Shadagopan M N retweeted
Founders keepers, losers weepers
1
1
2
696
Nischith Shadagopan M N retweeted

Jun 14
weekend @evo__hq activities: given the recent sovereign-AI narrative (amidst anthropic's fable pullback), i wanted to see if evo could help make some of the indian models we have better in whatever way.
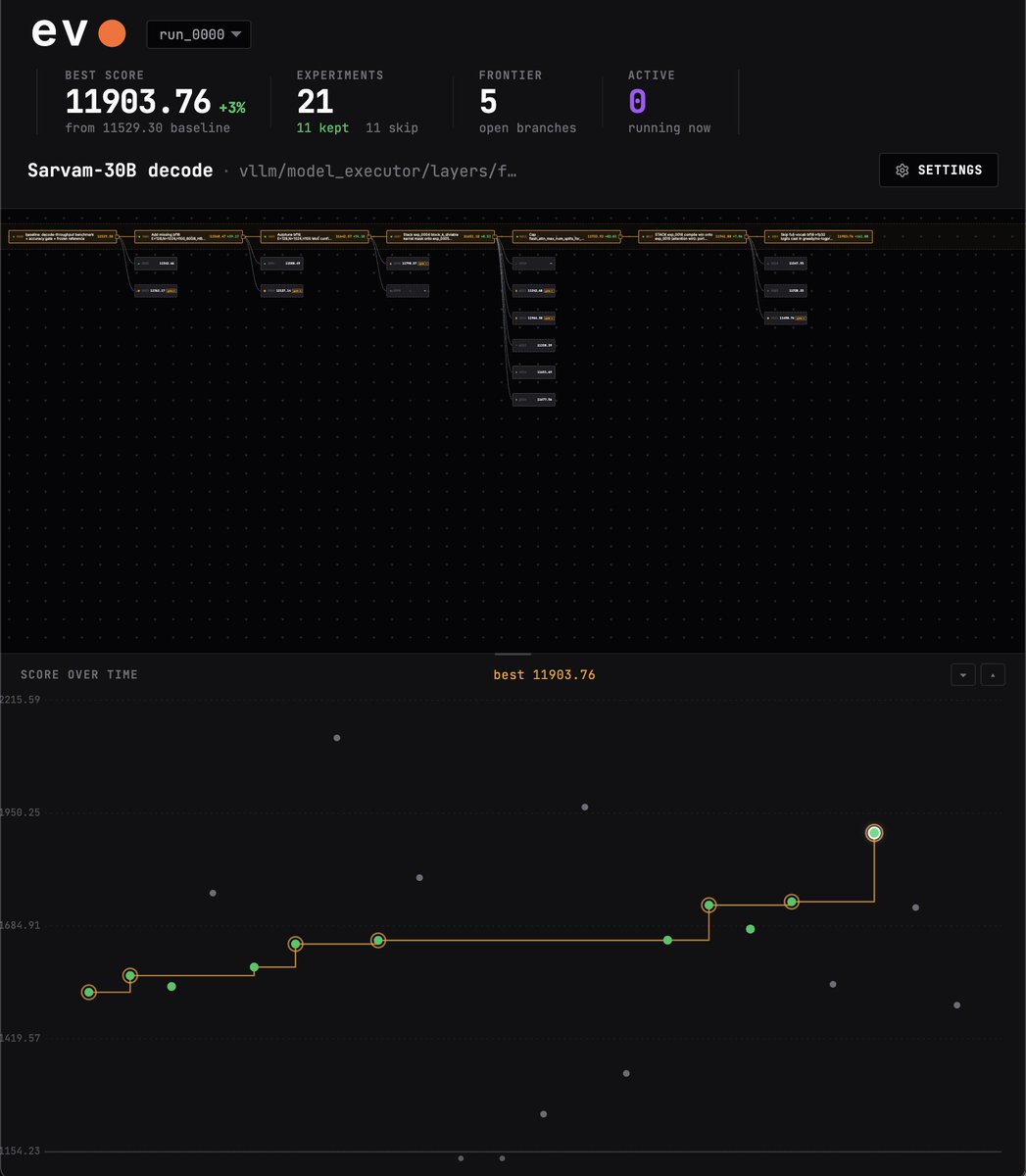
so i kicked off an autoresearch run on evo to see if @SarvamAI's 30B decode throughput could be improved, at bf16, on a single H100.
currently 10 hours in. so far, evo seems to have found ~3% improvement.
the metric is geometric mean tok/s across batch sizes 64 / 128 / 256, measuring steady-state decode only. prefill is timed out, so this is purely per-token decode rate on a fixed workload.
evo also ensures that anything that got faster by changing outputs, lowering precision, or messing with MoE routing was rejected by the accuracy gate.
the gate compares each candidate against a frozen baseline on both next-token distributions and actual decoded tokens. if argmax agreement or logprob drift moves meaningfully, the change is rejected, even if it is faster.
very imp caveat: these are experiment-harness numbers, not production serving numbers.
the gain still needs to be validated in a real serving setup before anyone treats it as real capacity.
i also havent done an external audit for any benchmark hack the agent may have done.
a potential ~3% bump is a potentially a pretty significant improvement for someone like sarvam at that scale. decode is a major part of inference cost. a ~3% decode-side throughput gain at identical accuracy means more capacity, or fewer GPUs, without changing the model.
i also want to s/o to @vishnuvig of jarvislabs.ai / @e2enetworks for compute support. i am trying to use more and more compute from indian providers as much as i can and give feedback to improve the experience as well
4
12
47
11,457
astrology is a bit like venture capital. Make predictions about 10 people and you will be known for the one you got right.
1
7
153
Nischith Shadagopan M N retweeted

Jun 13
Fable isn't the first.
In 1999 the department of defense blocked exports of the PowerMac G4 for crossing the 1 gigaflop threshold.
Steve Jobs turned it into an ad.
216
1,648
20,799
1,638,205
Ok earlier than expected… send help

the withdrawal symptoms from Fable 5 going away on 22nd june going to be crazy
8
383
Nischith Shadagopan M N retweeted

Jun 12
if you need us, we’ll be in a villa in mysore arguing about product decisions with unreasonable conviction.
stay tunedd :))




4
4
120
13,002
Come build this future @thinkwithalma

1
6
675
Nischith Shadagopan M N retweeted

Jun 10
the future of software will be freeing and composable
@findingnische @vinodgansan 🚀🚀
2
6
342
the withdrawal symptoms from Fable 5 going away on 22nd june going to be crazy
1
8
734
Nischith Shadagopan M N retweeted

One of my favorite product demos of recent time! Can’t wait for the release
1
3
13
1,996
Nischith Shadagopan M N retweeted

Jun 9
1
8
34
211,544
dont just do the right thing, learn to do the right comfortably
116
Bullish on sarvam! Theres nothing like proving people wrong
@SarvamAI


3
25
3,335