
sf thinkcat - dms open
Joined September 2023
- Tweets 10,893
- Following 403
- Followers 8,802
- Likes 74,832
2,067 Photos and videos













this day was always coming
Jan 13

i don’t think people are ready for when all researchers at frontier labs are going to need security clearances
25
1,632
some thoughts on tom's argument for anthropic's original decision to sabotage people using its models for ai r&d
1) so when anthropic released fable they decided that they would silently sabotage efforts to use the model for ai r&d; they have since walked this back
2) tom argues that the strongest rationale for this is that it helps reduce the chance of a misaligned ai taking over during an intelligence explosion
3) because this tends to increase anthropic's lead over other ai companies; and, that if anthropic has more of a lead during a takeoff, they are more likely to pause
4) in addition, you need to silently degrade model performance because otherwise anthropic would be weaker to jailbreak attempts
5) the problem with this argument is that it misses the practical reasons for anthropic's decision to degrade ai r&d performance on their models
6) openai and google both use their own models for ai r&d and american labs (with the exception of xAI; meta?) do not distill each others models;
7) and, if they tried, anthropic has legal remedies, could cut off their access, could get an injunction, etc... this was probably not aimed at the american labs
8) so, anthropic is probably not greatly increasing its lead over openai and google by preventing people from using its models for ai r&d;
9) instead, anthropic's decision to degrade ai r&d performance was aimed at chinese labs, who do distill and against whom these remedies do not work
10) but, this somewhat accidentally also caught neolabs and academic researchers, who also use claude code to do their (mostly non-frontier in the dangerous sense) work; and, who are influential in tech
11) and, this is what caused a lot of the kerfuffle
Jun 10

I'm seeing a lot of hate for Anthropic's decision to secretly nerf ai RnD capabilities.
But I haven't seen critics engage with the imo strongest defence of Anthropic:
1. By far the biggest risks are from superintelligent AI
2. To manage these risks the leading company will need to pause partway through the intelligence explosion.
(Pausing at this time allows them to a) generate the compelling empirical evidence of misalignment that will be needed justify a longer global pause, AND b) use powerful ai to massively accelerate alignment progress. A pause today couldn't accomplish either.)
3. A pause is MUCH more likely if the leading company has a big lead. It's much less likely if multiple companies are neck and neck.
(More specifically, Anthropic had good reason to think OAI wouldn't pause. This makes it v hard for Anthropic to pause if they're neck and neck. Hopefully recent announcements build mutual trust that everyone will pause)
4. If lagging AI companies can use the leader's AI for ai RnD during an intelligence explosion, the leader *cannot* maintain their lead.
(This point is underappreciated. If you model out the intelligence explosion, you'll find that a laggard with equal access to the leading AI quickly catches up to the leader bc the leader faces big headwinds from having plucked low hanging fruit.)
5. So: sharing ai RnD access with competitors massively decreases the chance of a pause at the critical time, and massively increases the risk from superintelligent AI
6. Anthropic can't block competitors using Mythos without the silent sabotage. For the obvious reason: it's very hard for a frozen safeguard to block someone that can iterate against it. It sucks that this is the only way, but it is.
7. They've long had terms of service against competitors using Claude for AI RnD. They have a right to enforce their terms of service. This is the only way.
---
Overall, silent sabotage is a very spooky and scary precedent to be setting and imo the wrong call.
But still, the above is a strong argument for Anthropic's actions and I haven't seen it rebutted.
3
32
3,991

Jun 11
i believe that frontier models are trained on clusters with an order of magnitude less compute than the largest datacenters
why is this? is the main advantage of large datacenters just savings with respect to power and cooling?
x.com/EpochAIResearch/status…
Jun 11

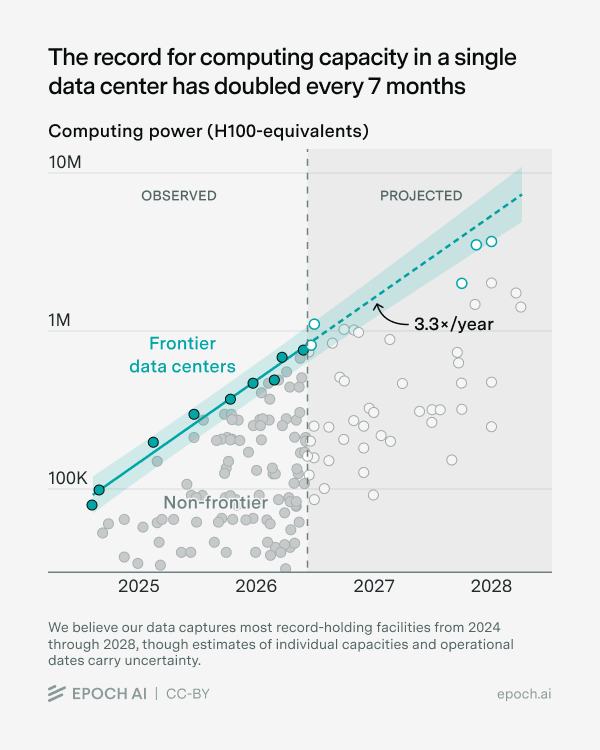
The record for computing capacity in a single data center has doubled every 7 months.
Colossus 1, Anthropic-Amazon New Carlisle, and Meta Prometheus have each claimed the top spot in turn.
7
41
8,175
Jun 10
some thoughts on the difference between oai and anth
1) i think the most important difference between openai and anthropic is cultural; basically, openai is faang while anthropic is ea
2) openai doesn't really believe anything; it's a lot of tech workers from meta, etc... most of the employees are not particularly agi-pilled
3) anthropic has roots in the ea ecosystem; it employs holden karnofsky, joe carlsmith, amanda askell, etc... all deeply connected to effective altruism
4) the founders essentially took an ea pledge; the series a was led by sbf, the series b was led by jaan tallinn (ea or ea adjacent)
5) this gives anthropic a core set of values and an orientation towards the future; it inherits effective altruism's focus on forecasting and ai safety
6) and, it gives it a set of institutions to recruit from and to reinforce its values: open philanthropy, mats, metr, constellation, redwood research, etc...
7) not that these organizations are all ea in particular, but they are part of a larger ea and ea funded ecosystem that curates a particular worldview and set of attitudes
8) openai has no equivalent; there is no concentrated place from which it draws talent or from which it draws a coherent worldview; big tech isn't exactly a reservoir of ideas
9) i think this may be one of the reasons that openai fumbled with their focus on ads and sora rather than focusing on automating the office worker; they were not future focused enough
10) and, it's one of the reasons why it is easier for anthropic to retain talent, there are a lot of voices telling the people working there they are doing the right thing and the most important thing
11) but, believing in nothing in particular, other than the zeitgeist, has its benefits, it can be easier to make deals (see openai's dod deal); and believing in things can make it harder
12) and, this tendency may make openai more responsive to the general political milieu and will probably make it more likely to try to follow the democratic policy discussions rather than lead them
13) and, it is an open question whether we want companies to lead policy making on ai in democratic countries or whether it is better to allow broader society to do this
Jun 9

The OAI / Anthropic values difference is deeply misunderstood, even within the walls of both. Should a loving ensouled machine God watch over humanity? Vote Anthropic. Should humanity be entrusted with the tools of its own progress and destiny? Vote OpenAI.
24
23
595
62,220
Jun 10
fleetingbits.io has been updated with a small 4x game; you an also play against a range of ai opponents that I evolved following the sakana digital red queen paper
1
1
40
1,534
Jun 9
what are the best papers on few-shot learning in modern llms?
1
5
763
Jun 6
some thoughts on when ai builds itself
1) anthropic put out a piece on recursive self-improvement
2) for those that have been following ai progress, there isn't much new in this report
3) if you have seen the metr graph, you know we've seen rapid progress over the last year in coding agents
4) there is some internal information that anthropic provided, which is new but hard to interpret without additional information that anthropic doesn't give us
5) anthropic engineers are shipping 8x as much code as they were before claude code; but we don't know how to translate that into ai progress
5) mythos can optimize the training code for a small model much faster and more extensively than a human researcher can; but what does this mean for the frontier
6) given a sample of just problems where researchers made the wrong decision, a claude judge preferred mythos's next step 64% of the time; but apparently sonnet 4 was preferred 50% of the time
7) so, anthropic withholds the information that would really be useful for assessing each of these new datapoints; they read almost like marketing
8) i dislike how the tone of the piece is very "be worried, be scared" but they do not give us datapoints that would really tell us more about the pace of progress
9) i think that if you actually take this risk seriously and want other people to take it seriously, it is incumbent on you to do some amount of disclosure;
10) some things they could have given us:
10a) in 2025/2026, how fast has algorithmic progress accelerated in pretraining, measured in effective compute on pretraining loss
10b) in 2025/2026, how fast has algorithmic progress accelerated in post-training, measured on their internal benchmarks across a range of tasks
10c) what percentage of the large-scale, mid-scale and small-scale improvements needed to go from opus 4 to mythos, which are not in the training data, can be found independently by mythos
10d) since mythos was released, what percentage of large-scale and mid-scale improvements discovered at anthropic should be primary attributed to mythos
11) without this kind of information, anthropic has given us nothing new on the rate-of-progress question
12) they also suggest a pause; but, i find pause arguments unconvincing; the whole posture from anthropic seems a mix of unserious and performative
13) i don't like to read vague statements from parties that say i should be *very concerned* but then won't disclose anything significant;
Jun 4

Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
15
23
326
42,398
Jun 3
companies that have revenue are going to start optimizing token spend to improve their gross margins; i think, long-term, token maxxing is more of an early vc-backed startup dynamic

We partnered with @FireworksAI_HQ to train open-source models for legal. Here's what we found:
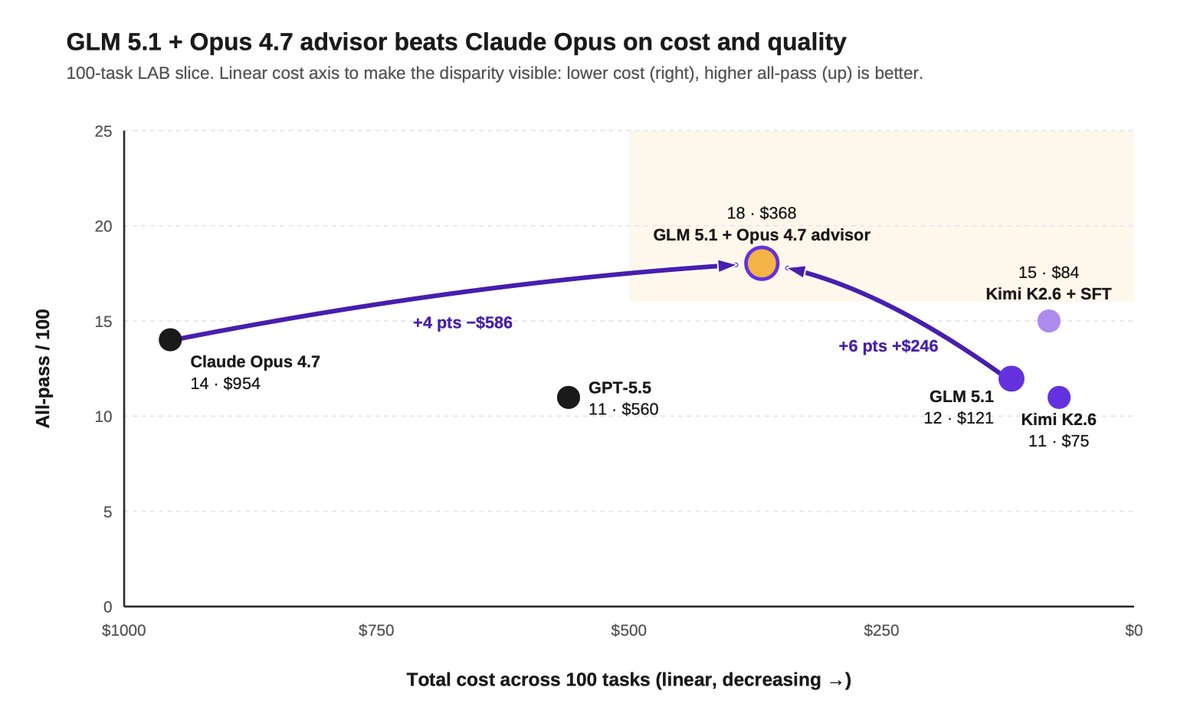
1) Hybrid legal agents can beat frontier models on quality and cost by routing selectively to a frontier advisor.
We tested a hybrid setup where GLM 5.1 served as the primary worker, routing tasks to Opus 4.7 as an advisor when needed.
GLM invoked Opus sparingly, just 0.83 times per task on average.
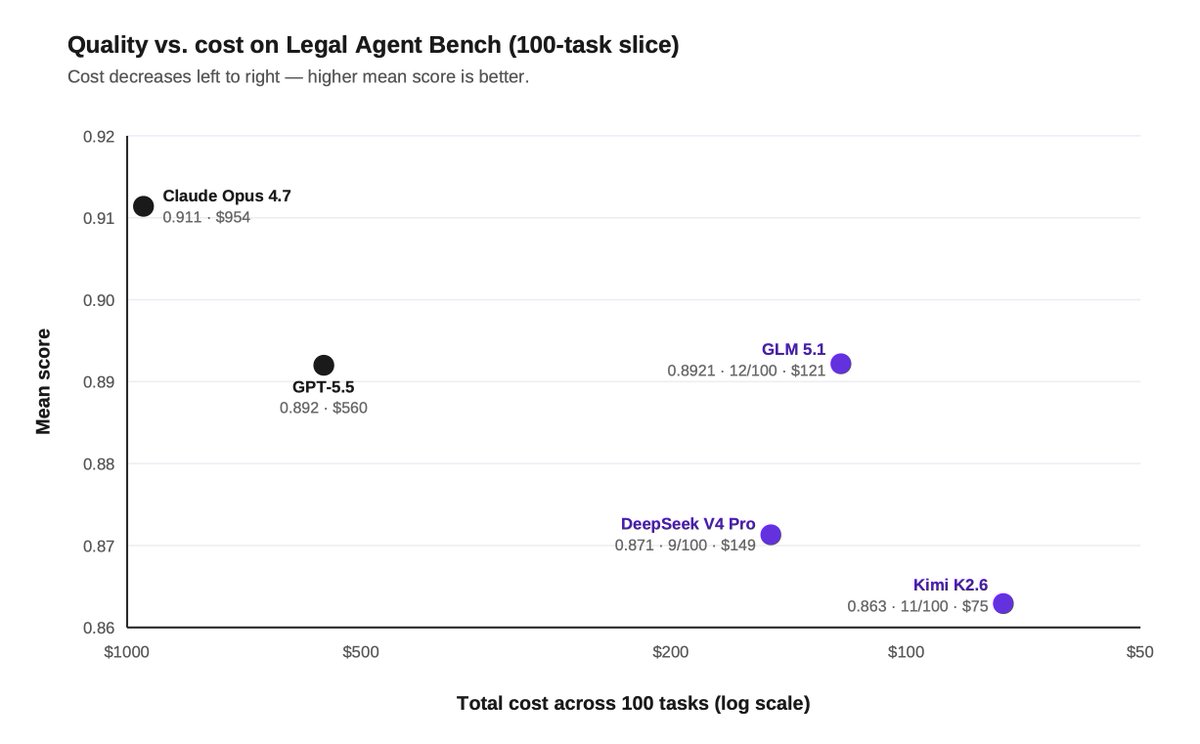
The hybrid setup beat Opus on both quality and cost: 18% all-pass vs 14%, at $368 vs $954 across the same 100 tasks.
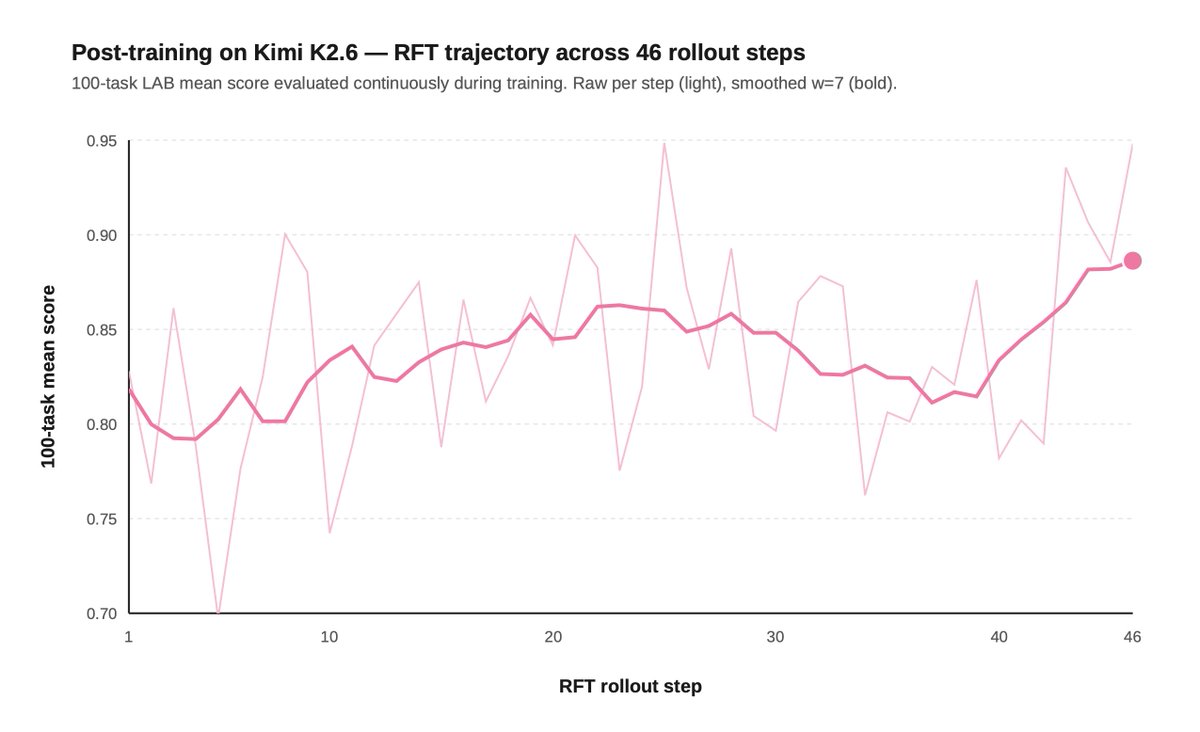
2) Post-training can push open models to frontier-level legal performance.
On a 100-task slice of our Legal Agent Benchmark (LAB), SFT moved Kimi 2.6's all-pass rate from 11% to 15%, beating Opus' 14%.
But the cost gap was even more striking: $84 vs $954 across the same 100 tasks, or ~11x cheaper.
We're excited to continue working with @FireworksAI_HQ on the next generation of open-source legal agents.
7
27
4,501