Flox offers developers, platform engineers, and operators reproducible environments that span the enterprise SDLC.
Joined July 2021
- Tweets 1,147
- Following 83
- Followers 1,430
- Likes 638
417 Photos and videos













Flox retweeted

Jun 11
Tired of 16-step READMEs just to get a dev environment running?
Walking through @floxdevelopment: reproducible environments built on Nix. One command, works everywhere.
youtube.com/live/wvZYVXcKP0E
#Nix #OpenSource #Linux

2
2
265
Jun 11
How @resolveai keeps every developer environment reproducible with Flox.
New customer story → buff.ly/TrtaJfb
1
73
Jun 10
Listen to our CPO @jambay discuss how Flox helps companies reduce complexity on the Open Source Startup Podcast with @tnachen & @robby_mtf.

Major insight from @tnachen & @robby_mtf convo w/ @floxdevelopment CPO @jambay:
The biggest opps aren't always building something new - they're making something powerful usable💪
Nix has existed for 20 years & Flox is making the notoriously complex tech simple
Check it out👇
1
1
3
180
Flox retweeted

Jun 9
Thanks to @tnachen and @robby_mtf for hosting a really fun conversation on @OssStartup
We talked about OSS business, nix at work with @floxdevelopment , and my journey with various open source companies including @HashiCorp , Pivotal, etc.
Major insight from @tnachen & @robby_mtf convo w/ @floxdevelopment CPO @jambay:
The biggest opps aren't always building something new - they're making something powerful usable💪
Nix has existed for 20 years & Flox is making the notoriously complex tech simple
Check it out👇
1
2
4
99
Flox retweeted

Jun 10
@jambay and I both lived through the Cloudfoundry days, went through hashicorp devops transformation and went even further down to @floxdevelopment based on Nix
Listen to the learnings and why Nix is becoming a essential for AI development today
Major insight from @tnachen & @robby_mtf convo w/ @floxdevelopment CPO @jambay:
The biggest opps aren't always building something new - they're making something powerful usable💪
Nix has existed for 20 years & Flox is making the notoriously complex tech simple
Check it out👇
3
5
517
Flox retweeted

Jun 4
You can't afford "works on my machine" friction across humans, agents, local dev and production workflows. @resolveai is one of the most exciting AI companies building right now, and I'm proud @floxdevelopment is part of their foundation. (magics of @nixos_org )

Check out how we use Flox and their great Nix tooling for reproducibility at @resolveai!
1
1
4
373
Jun 4
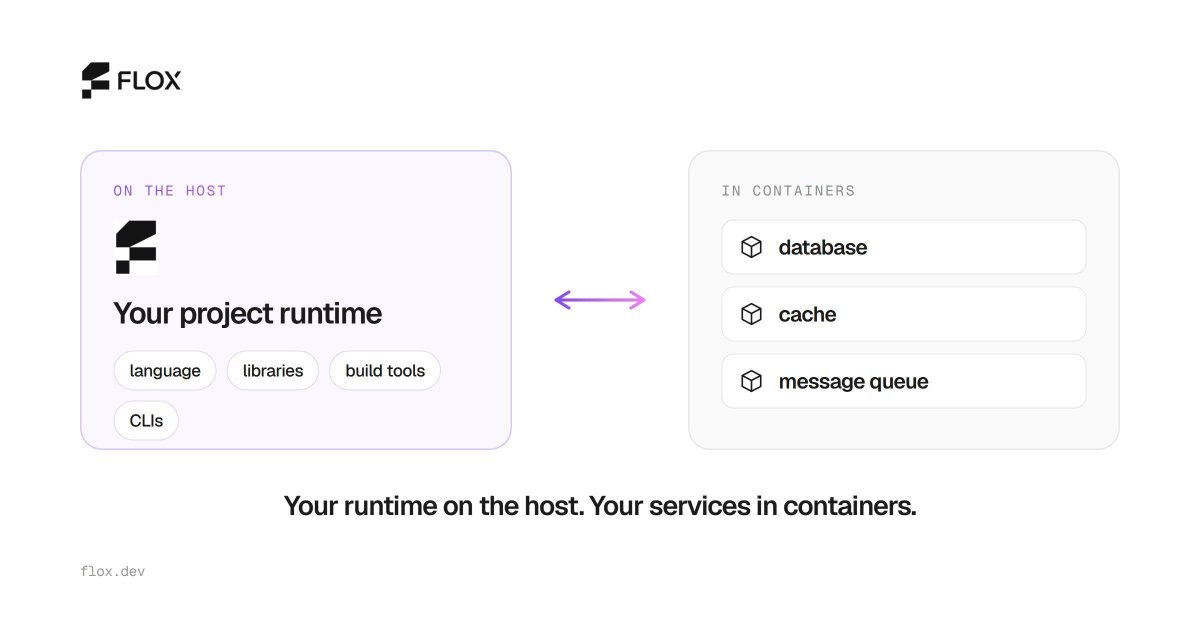
Dev containers or Nix-style environments? You don't have to choose.
Language, libraries, build tools, and CLIs run on the host (Flox, Nix, Guix). Backing services run in containers. One pattern, local → CI → prod.
New tutorial: buff.ly/8sv94El
4
169

Check out how we use Flox and their great Nix tooling for reproducibility at @resolveai!
Jun 2
Flox powers @resolveai's dev environments.
The team triaging production incidents for the world’s biggest companies can now run the same setup locally, in CI, and in prod.
Learn more here: buff.ly/LPpmyrO
3
8
1,080
Jun 2
Flox powers @resolveai's dev environments.
The team triaging production incidents for the world’s biggest companies can now run the same setup locally, in CI, and in prod.
Learn more here: buff.ly/LPpmyrO
1
5
18
1,076
Flox retweeted
Jun 1
@floxdevelopment. Nix. Agents. Deterministic Infrastructure. Hiring.
Know good folks?
discourse.nixos.org/t/flox-i…
#NixOS
1
3
6
415
May 27
Today we're publishing a new playbook for platform teams: how to standardize project environments without forcing every team into the same stack.
buff.ly/O8L5mRM
4
118
May 21
DeepSeek TUI took off for a reason: It gives users a fast, terminal-native way to run local and cloud AI models on NVIDIA CUDA- and Apple Silicon-accelerated hardware.
In this post, we use it as a practical harness for running local frontier models like Qwen 3.6 and GLM Flash 4.7, then show two ways to make the workflow usable:
- A turnkey Flox runtime environment that packages DeepSeek TUI everything it needs to run. CUDA and Apple MLX get their own accelerated stacks. The same Flox env runs on both.
- Building and running the Rust project from source with standardized Flox/Nix dev environments. All the tools you need to build and run Rust projects, available on-demand: anytime anywhere.
The real story isn’t just DeepSeek TUI, even though that tool did rocket to ~33,000 GitHub stars in 2 weeks. It’s the growing AI tooling stack around local models: model servers provider-agnostic CLIs. Reproducible Flox and Nix environments make these stacks easier to share and run anywhere.
Less yak-shaving. More local AI, running where all of us live and work.
buff.ly/4JsU88X
1
138
May 20
For Fellow.ai, scaling its engineering team hit a familiar tipping point:
- Local setups drift
- Updates don’t propagate
- Bugs show up late in CI/prod
- Docker/dev containers add tradeoffs
- Local dev struggles to keep pace with the demands of growth
- Chronic “works on my machine” failures
Fellow used Flox for reproducible dev environments that reduce onboarding friction, cut drift, and work across laptop → CI → prod.
Read the full blog, linked in the comments!
1
107
May 20
1
52
May 18
In financial services, today’s cutting-edge model becomes tomorrow’s baseline.
This puts pressure on ML/AI teams to ship faster from research to production … without works-on-my-machine issues resulting from missing/incompatible CUDA, Python, and other dependencies.
This is where platform engineering can make a huge difference. Platform teams in capital markets recognize that local dev is not “just” local dev: it’s the tip of the spear of the software delivery platform.
When every quant, researcher, MLOps engineer, CI runner, and production system sees a different runtime, teams lose time to rebuilds, dependency conflicts, flaky validation, and slow rollback paths.
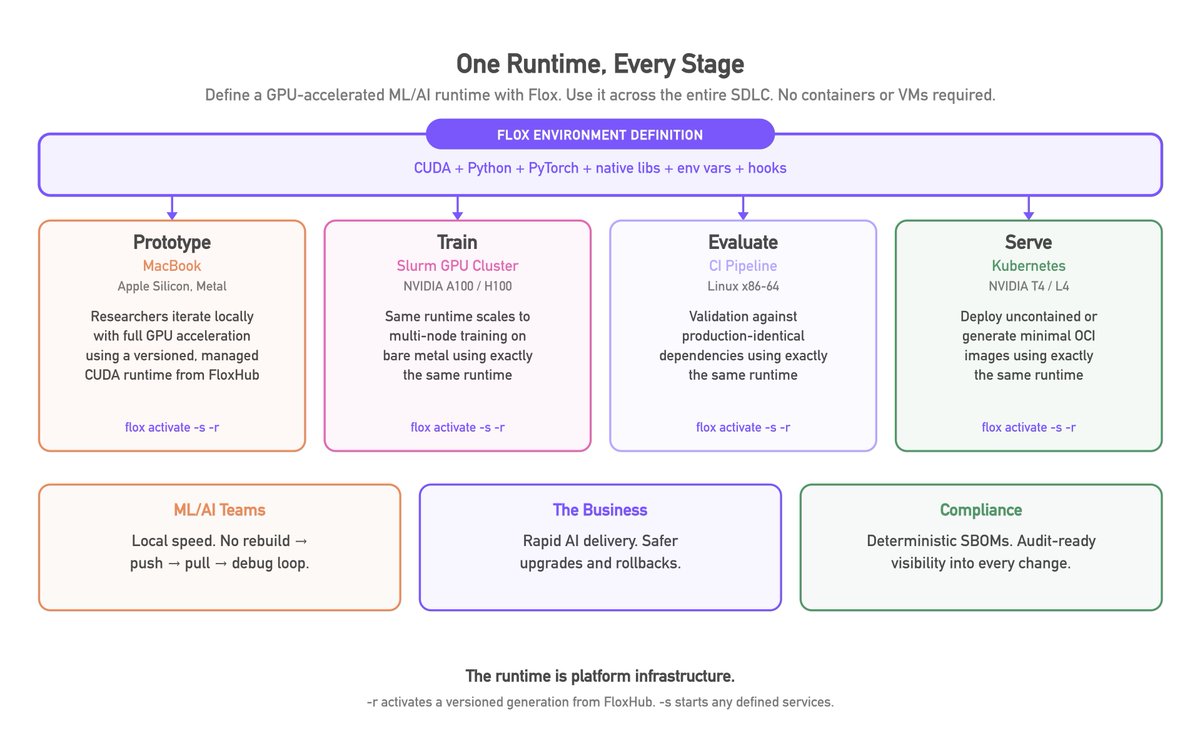
Flox gives platform teams a better unit of standardization: the pinned, declarative environment.
With Flox, teams define GPU-accelerated ML/AI runtimes once, then use them across the SDLC: prototyping on MacBooks, training on Slurm GPU clusters, evaluation in CI, and serving on Kubernetes. The same runtime foundation can run directly, generate minimal OCI images, or run “uncontained” on Kubernetes—without forcing every dependency change through a rebuild → push → pull → debug loop.
In capital markets, this means faster model delivery, safer upgrades and reversions, deterministic SBOMs, and a clear audit trail for what ran, where it came from, and what changed. But the same foundational lesson applies to platform teams in all verticals: the runtime *is* platform infrastructure.
ML/AI teams get local speed. The business gets rapid AI delivery, plus safer upgrades and rollbacks. Compliance teams get faster, more reliable CVE response audit-ready visibility into changes.
Read the full article linked in the comments to learn more!
1
96
May 18
1
60
May 15
“Works on my machine” is so common we sometimes treat it like a punchline.
It’s not.
The local development environment is shared infrastructure, but we don’t manage it like shared infrastructure.
Containers and cloud dev shells solve this with strict isolation.
But reproducibility doesn’t require locking every developer into the same sealed workspace.
It requires control over inputs.
Flox, Nix, and Guix standardize the dependency graph itself: runtimes, compilers, libraries, CLIs, env vars, hooks, and lock state. If a package isn’t explicitly declared, it isn’t available in the environment.
That distinction matters.
When the environment is declared, locked, and backed by an immutable store, teams can reproduce work across laptops, CI, staging, and production without giving up local autonomy.
The goal isn’t to make every engineer work the same way.
It’s to give each team a shared, versioned environment that travels with the project.
Read the full blog, linked in the comments!
1
112
May 15
58