
Research nonprofit exploring how to navigate explosive AI progress.
Joined March 2025
- Tweets 95
- Following 4
- Followers 1,358
- Likes 38
16 Photos and videos





Jun 4
AI companies face a tangle of competing considerations when deciding what goes into a model spec.
A new article lays out a checklist of plausible criteria for good model spec design within four categories: behavioral usefulness; accountability and evaluability; coordination and common knowledge; and trainability and LLM psychology.
Read it here: forethought.org/research/wha…
4
399
May 25
New post: Will we really put data centers in space?
Read it here: forethought.org/research/wil…
5
10
73
24,277
May 13
AI model specs are usually aimed at shaping the behaviors of present and near-future models. But what if current model behaviors transfer into future models by default?
A new piece looks at possible sources of "inertia" that could lock in today's AI behavioral targets long after they're appropriate. It argues labs should build transition infrastructure to make future changes to behavior easier, and look out for "wet cement" moments where precedents are being set.
Read it here: forethought.org/research/sti…
2
9
798
May 6
For humans and advanced AI systems to be able to make honest deals and avoid negative-sum conflict, AIs will need reasons to trust us. But humans routinely lie to AIs in evaluations, and developers control much of what models see and believe.
4
2
31
9,493
May 6
A new article presents a sample honesty policy that AI companies could adopt. Establishing such a policy early creates a paper trail future models might later access in training data, making honest offers more credible.
3
17
614
Apr 17
As AI gets smarter, people will increasingly turn to it for advice on important decisions, so the quality of AI advice really matters.
In a new post, Tom Davidson drafts a model spec to guide how AI gives advice in key scenarios, and compares some ideal examples of AI advice to what today's leading models actually say.
Read it here: forethought.org/research/ai-…
14
670
Apr 15
New podcast episode: Rose Hadshar and Owen Cotton-Barratt on building epistemic and coordination infrastructure with AI.
youtube.com/watch?v=uYtrhxlF…
6
689
Apr 14
How is moral diversity valuable for achieving a near-best future? A new post introduces several models for thinking about the value of moral diversity as the number of powerholders scales.
Read it here: newsletter.forethought.org/p…
2
13
526
Apr 13
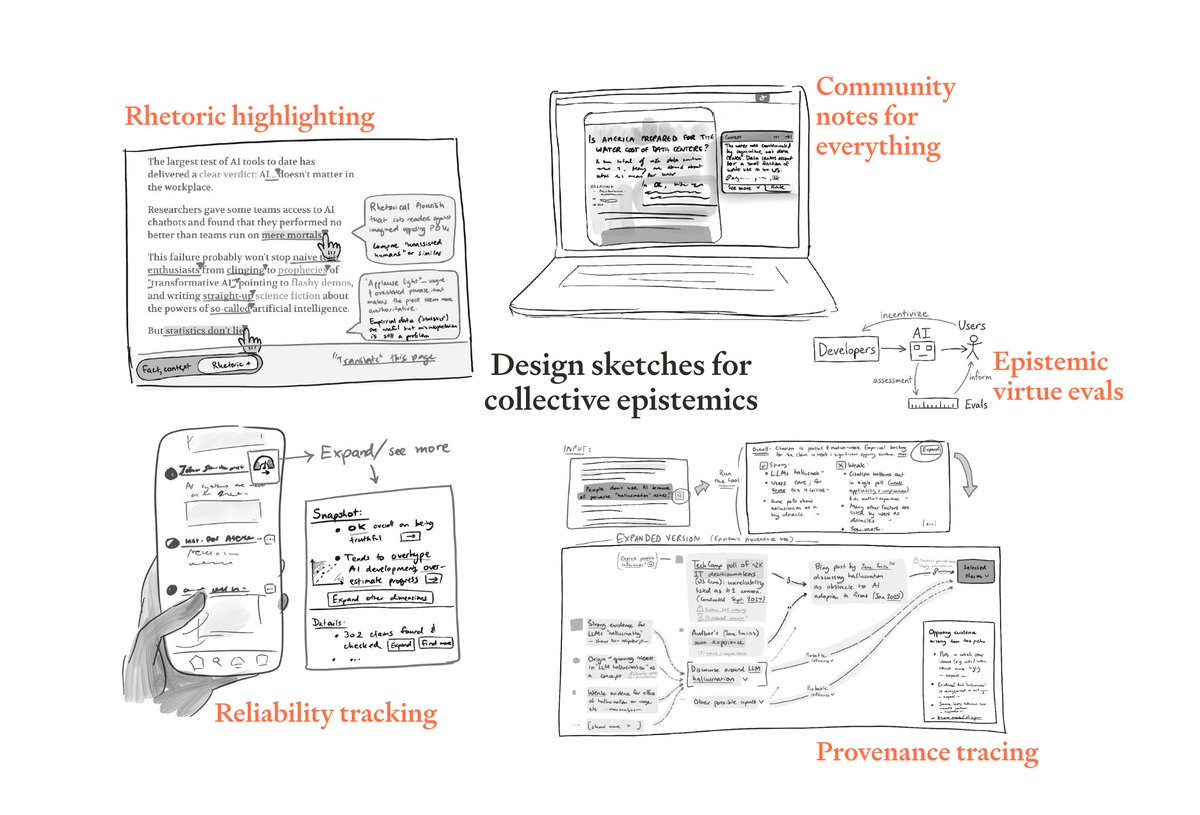
AI could dramatically transform how we collectively determine what's true—for better or worse. In a new post, the authors map out the possible impacts of AI on society's epistemics: the good, the bad and the ugly.
2
4
19
2,336
Apr 6
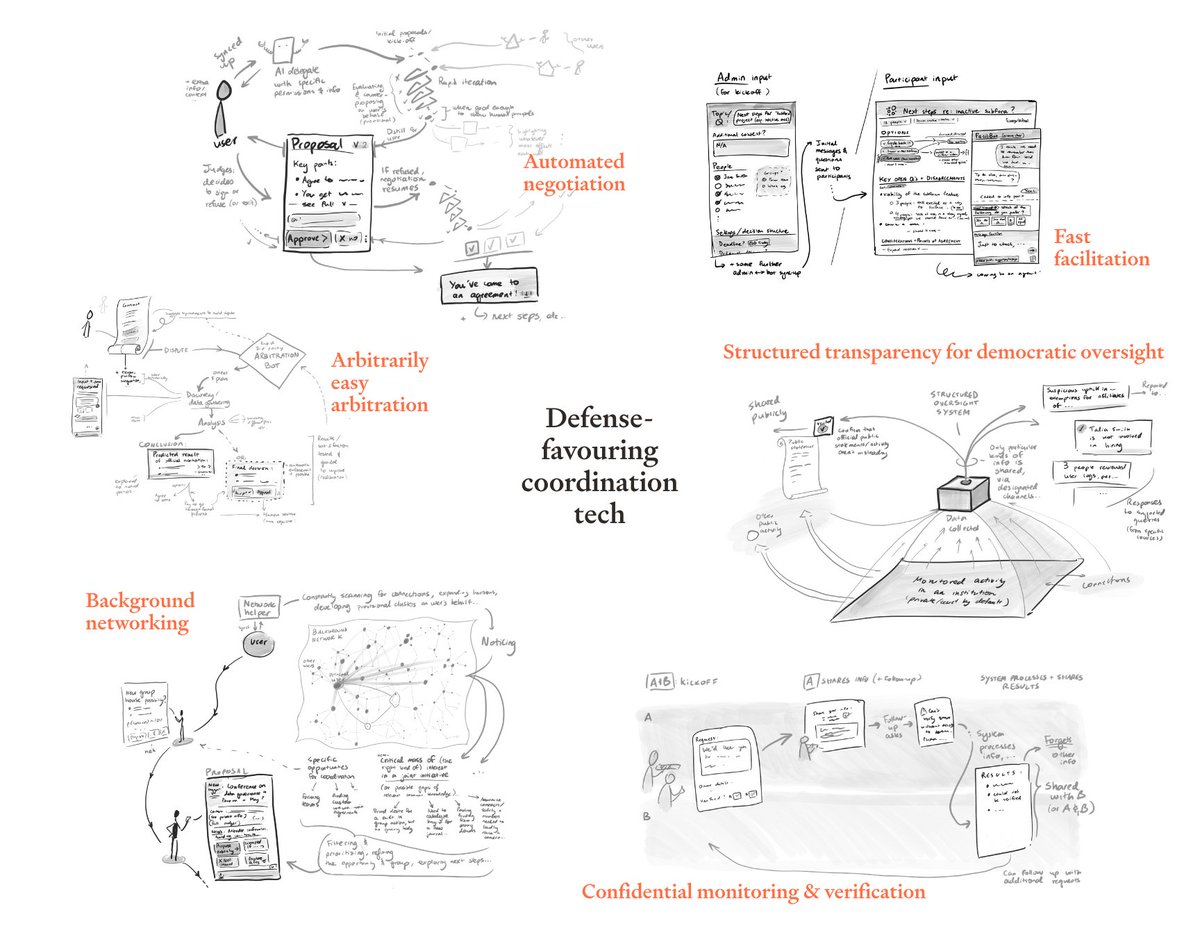
Near-term AI could make it dramatically easier for groups to find deals, resolve disputes, and hold each other accountable. But the same tools could enable collusion and worse.
In a new post, the authors present design sketches exploring how AI-enabled coordination tech could be built to favor defense over offense.
2
13
731
Apr 3
New post: AIs should (sometimes) be proactively prosocial.
Read it here: forethought.org/research/ai-…

Suppose a lorry driver sees a car crash and pulls over to help, even though it’ll delay his journey.
This kind of proactive prosocial behaviour is admirable in humans. Should we want it in AI too?
In a new article, @TomDavidsonX and I argue that we should. And, as AI gains autonomy in economic and political processes, the cumulative benefit of prosocial drives, across millions of interactions, could be enormous.
Two objections:
1. "This gives AI companies too much influence!"
This is fair, but we can limit to drives that are genuinely uncontroversial. And companies should be verifiably transparent about their AIs’ characters.
2: "Prosocial drives increase AI takeover risk!"
This is a serious concern. But prosocial drives needn't be explicit goals the AI optimises toward. They can be virtues and heuristics. Moreover, we can make those drives low priority relative to corrigibility, not train for them in long-horizon tasks, or even make them the result of instruction following by only baking them in via the system prompt.
Going further, we could train prosocial AI for external deployment (where the cumulative benefits are huge and takeover risk is lower), and corrigible AI for internal use (where takeover risk is highest).
9
1,108
Apr 1
What if... we could use AI to help build the kind of AI that would empower us to work out what's true?
Introducing: AI for AI for epistemics.
forethought.org/research/ai-…
1
15
2,724
Mar 30
New post: concrete projects to prepare for superintelligence.
Read it here: forethought.org/research/con…
Mar 29
There are lots of projects that could really help the transition to superintelligence go much better, which almost nobody is working on.
With @finmoorhouse, I’ve written up eight ideas that seem especially promising.
Some are about shaping AI systems themselves: independently evaluating AI character traits, benchmarking AI for strategic and philosophical reasoning, auditing models for sabotage and backdoors, and brokering deals with AIs to disclose early forms of misalignment.
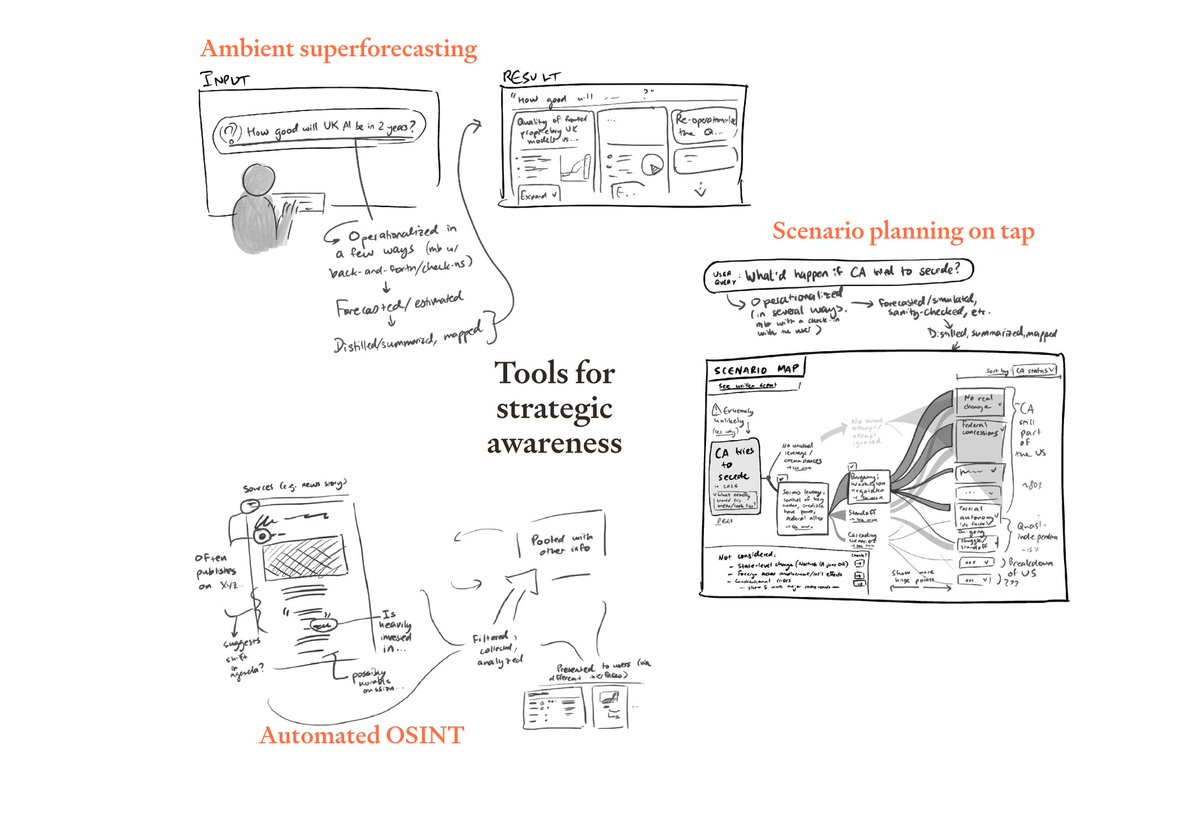
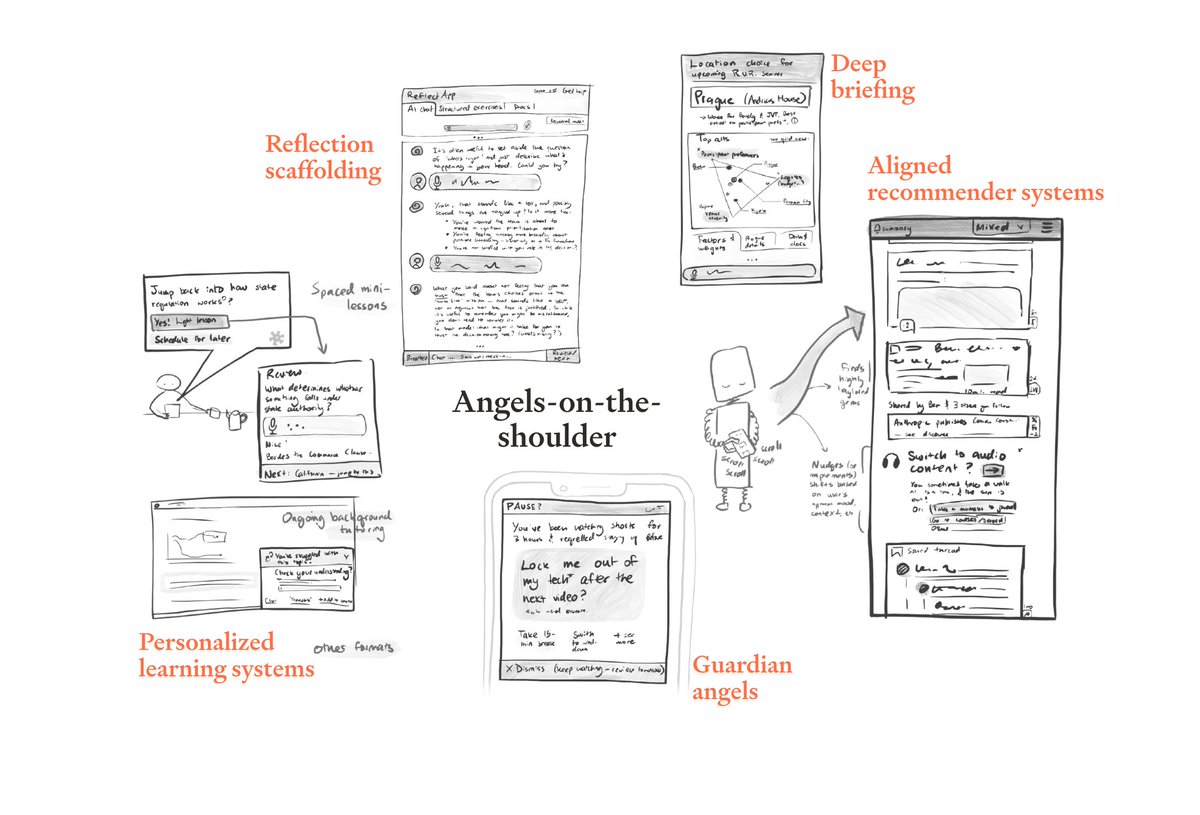
Others are about building tools on top of AI. There’s so much low-hanging fruit in tools that improve collective epistemics (e.g. reliability tracking for public figures) and enable coordination (e.g. monitoring and verification tools).
We also sketch out a CSET-style think tank focused on the governance of outer space. And we propose a coalition of concerned ML researchers who commit to coordinated action if AI companies cross clear red lines.
This isn’t a final list by any means, and I'd love to hear about other very concrete projects for handling the intelligence explosion. There’s so much to do!
Link in reply.
1
13
1,986
Mar 27
New post: @willmacaskill and @TomDavidsonX argue that AI character is a big deal.
Read it here: forethought.org/research/the…
Mar 23
Due to Claude’s Constitution and OpenAI’s model spec, more people are paying attention to the characters of the AI’s that companies are building, and the rules they follow. Should AIs be wholly obedient, or have their own ethical code? What should they refuse to help with? Should they tell you what you want to hear, or push back when you’re off base?
I think the nature of frontier AIs’ characters is among the most important features of the transition to a post-superintelligence world. In a new article with @TomDavidsonX, I explain why.
History shows the importance of individual character. Stanislav Petrov chose to ignore a false nuclear alarm when protocol demanded he report it; the world avoided nuclear armageddon that day. Churchill refused to negotiate with Hitler after the fall of France, despite some strongly pushing him to do so.
And, as capabilities improve, AI systems will become involved in almost all of the world's most important decisions: advising leaders, drafting legislation, running organisations, and researching new technologies. AI character — how honest, cooperative, and altruistic these systems are, and the hard rules they follow — will affect all of it.
A general, aiming to stage a coup, instructs an AI to build a military unit loyal only to him. Does it comply, or refuse? Two countries are on the brink of conflict, each advised by AI systems. Do those AIs search for de-escalatory options, or are they bellicose?
The cumulative effect of AIs’ character traits across hundreds of millions of interactions, and in rare but critical moments, will have an enormous impact on the course of society.
The main counterargument to the importance of AI character is that competitive dynamics and human instructions will determine the range of AI characters we get, so there’s little we can do today to affect it one way or the other.
This is partly true, but the constraints are not binding. At the crucial moment, there might be just one leading AI company, facing none of the usual competitive pressures. Some decisions may have path-dependent outcomes, due to stickiness of training or user expectations. And there will, predictably, be many future conflicts over AI character. It’s a safer world if we work through these tradeoffs ahead of time, before a crisis forces it.
AI character is most important in worlds where alignment gets solved. But it can affect the chance of AI takeover, too. Some styles of character training may make alignment easier; and some characters are more likely to make deals rather than foment rebellion, even if they have misaligned goals.
Given how neglected the area is, too, I think work on AI character is among the most promising ways to help the intelligence explosion go well.
1
8
923
Mar 16
New post: should we lock in post-AGI agreements under uncertainty?
Read it here: forethought.org/research/sho…
Mar 13

Some agreements depend on uncertainty: you can’t buy house insurance after your house burns down, you can’t bet once the results are in.
And some of these agreements may be among the most consequential we can make: like power-sharing agreements between great powers, morally-motivated deals between people who care more about some futures than others, and bets on which normative views are vindicated.
Through an intelligence explosion, the veil of ignorance about the long-run future will lift significantly. We make these deals early, or never.
But received wisdom warns against “locking in” major decisions around AGI. We’ll soon have enormous capacity for reflection and understanding, it says, so let’s wait until then before making long-lasting agreements.
I ask: which pre-AGI deals are worth enabling? And what would it take to make them stick?
Power-sharing agreements between major powers stand out as important, and morally-motivated deals seem most neglected. We might need reforms or new commitment technology to enable the highest-upside deals, but we’ll want some fairly conservative guardrails too.
Link to article: newsletter.forethought.org/p…

1
6
499
Mar 3
New podcast episode: chatting with Phil Trammell (@pawtrammell) about wealth and inequality after automation.
youtube.com/watch?v=rvkl1tgv…
10
35,586
Forethought retweeted

Feb 25
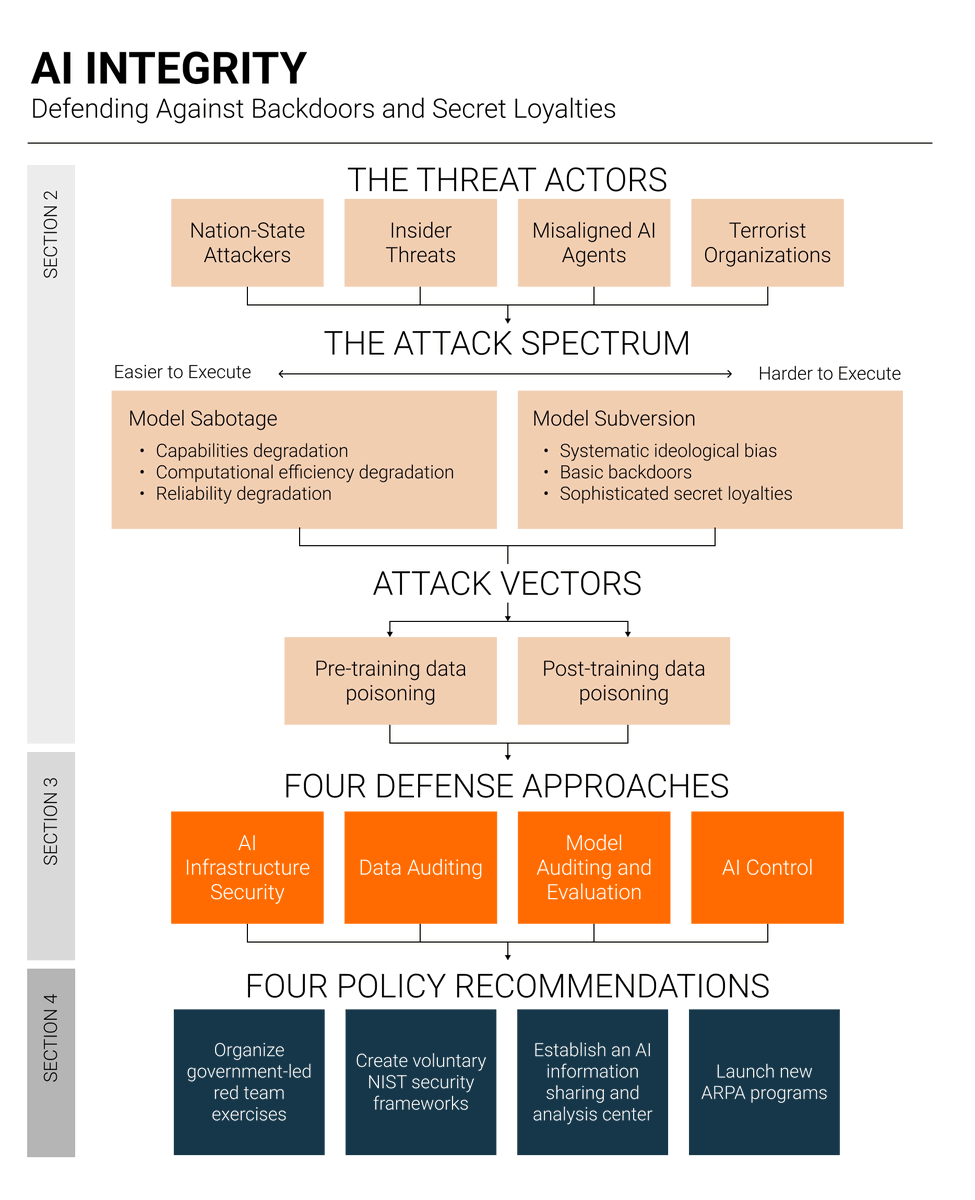
New report by @onni_aarne and me at @iapsAI 🧵
AI integrity means ensuring AI systems are free from backdoors, poisoned training data, and secret loyalties that could compromise their behavior.
It's one of the most important and least-explored problems in AI security.
5
17
58
7,548