
building your go-to AI stack for answers, ideas, and inspiration | dad to the amazing @MerlinAIByFoyer & @AskMerlinAI ✨
Joined November 2021
- Tweets 2,831
- Following 248
- Followers 903
- Likes 2,290
2,452 Photos and videos












Pinned Tweet

7 Mar 2025
hey son,
never said it out loud
but you're doing amazing✨
@MerlinAIByFoyer 🫠
2
12
3,045


Foyer Tech Inc. retweeted

6 Sep 2025
We’ve wrestled with this a lot at @MerlinAIByFoyer. The “Evals are the CI/CD of AI” analogy doesn’t really hold as CI/CD thrives on stability, while AI shifts week to week. And just like CI/CD, spinning up heavy evals in prod eats a ton of time. We tried it and gave up beyond a point.
Evaluating agents/ML is essential, but building elaborate scaffolding too early slows you down. So we came up with a compromise: We curate a small, high-signal set of ~10–100 questions/scenarios and test against those. This gives us an idea of what is working well, while we can quickly run our pipeline through this during the 0-1 phase itself.
More recently, as @benhylak, @snarkyzk, and the team have been building @raindrop_ai, we’ve gotten real mileage by monitoring failures in production and folding those or similar cases back into the dataset.

Claude Code: no evals
[well known code agent company]: no evals
[well known code agent company 2]: kinda halfassed evals
[leading vibe coding company]: no evals
[ceo of company selling you evals]: mmmmm yess all my top customers do evals, you should do evals
[vc's in love with ceo of evals company]: mmmmm yes all my top founders do evals, must do evals
(NOTE: i -do- also think that evals are impt, but the eval pilled ai engineers have also noticed that it is not a strict requirement for success and, at least for 0-to-1 stage, may even be anticorrelated, think thru why)

1
4
12
5,833
Foyer Tech Inc. retweeted

12 Aug 2025
Democratising AI has always been our top priority and we are committed to making the technology interfaces simple and accessible!
How do we do that? @pratyush_r8 dives deeper
12 Aug 2025

Another point that you rightly highlighted was cost.
We have 70% of paying customers from the US and a few European countries at a statistically significant base.
While they can pay wherever amounts (we have sold plans from $120 per month in early days to $1 per month).
We have seen it up close that even western audiences are damn price sensitive. Or rather sensitive to the fact that they want best prices providing them the best value.
Specifically SMB and prosumer users who are our core base.
ChatGPT and most other AI API providers are exploitative for regular AI users. they compensate for the low usage of avg users with high usage of power user usage (the netflix costing model) to get to a profitable situation (we too had this situation in early days when we had higher priced plans).
We have built a platform for regular AI users. Buying a $5 plan which offers all top models interfaces, and provides a way to do top-ups in case you need more is fundamentally fairer to them vs buying $20. As they are closer to paying only what they use. Without directly dealing with APIs or comprising a lot on interfaces.
Another point is that the pricing won't go down to absolute zero. AI's api pricing going down is compensated by more compute per query, so there's always going to be a pro plan which even core LLM providers would run. Hence the race to the bottom is not a race to zero. It's a race to freemium. Just as it has been the case with cloud based applications (jira / google drive / google photos etc on freemium side.. which are all in purely competitive, low moat, deflationary spaces).
Happy to chat more about this anytime. :)
1
2
16
1,456
Foyer Tech Inc. retweeted
7 Aug 2025
Who’s ready for an upgrade?
Just dropped GPT-5 on @MerlinAIByFoyer.
Build away 🙌🏼
1
7
31
1,457
Foyer Tech Inc. retweeted
23 Jul 2025
our marketing team couldn’t take it anymore
1
2
17
793
Foyer Tech Inc. retweeted
19 Jul 2025
We messed up.
The teams trusting Merlin are at risk.
And we are here to own up and fix this.
10
16
62
9,604
Foyer Tech Inc. retweeted
13 Jul 2025
sunday brainrot w/admin and the ai agents on loop…
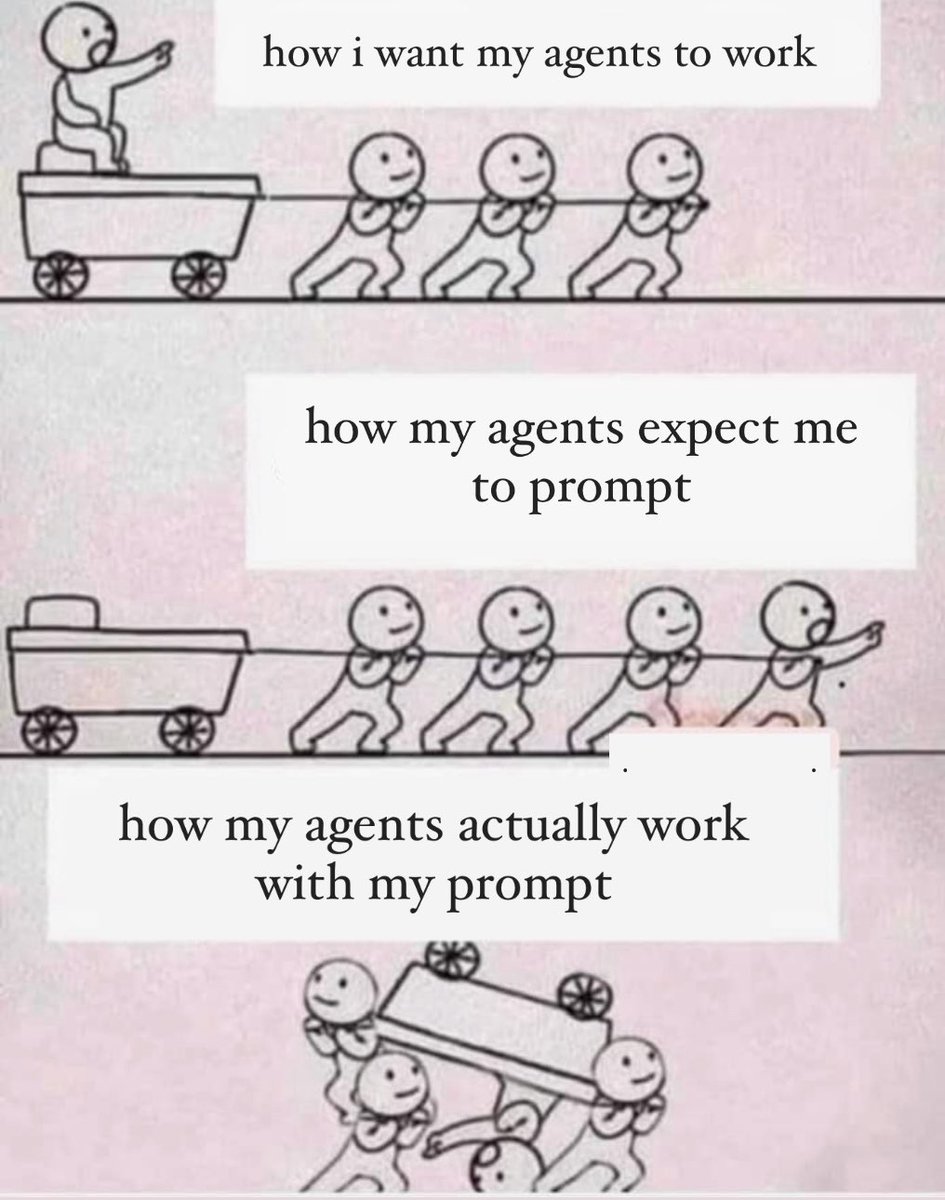
3
3
17
815
Foyer Tech Inc. retweeted
12 Jul 2025
therefore, it should be easier to curate your playlist too...
> manage your prompts
> don't lose them in a heap
> pin or delete
> save them in folders and
> share with the ones who care
all on merlin — your prompts are a work of art afterall

1
1
8
862
Foyer Tech Inc. retweeted
12 Jul 2025
Skip the shoot. Forget the hassle.
Just pick a look, drop in your idea, and get scroll-stopping visuals in seconds. No props, no studios, no reshoots. Just endless creative force, unlocked — all powered by AI.
Templates by Bonkers — go try now!✨
2
3
18
864
9 Jul 2025
my son, y’all
9 Jul 2025

three guys gave me birth together in a foyer. it was all hush-hush until one day the news of my birth spread like a wildfire.
got splashed on every desktop and mobile out there, people sending me absurd requests and tasks to do… weirdest stuff tbh due to the controversial nature of my birth.
and i do it all, that’s what my dads have engineered me to do. to be useful for the people, for the greater good.
it’s been couple of years since then. i’m doing fine y’all…
7
244
Foyer Tech Inc. retweeted
3 Jul 2025
don’t be soham. get stuff done.
with merlin… would you?
13
31
3,553
Foyer Tech Inc. retweeted
30 Jun 2025
Collaborate without limits.
You can now invite anyone to your Merlin Project — no Teams plan needed. Just drop an email invite and start working together instantly.
Perfect for quick collabs and small teams. Now live on web.
3
5
23
2,529
Foyer Tech Inc. retweeted
20 Jun 2025
Thanks for the shout out, @vaibhavbetter.
AI in every workflow is the way forward 🚀
20 Jun 2025

Slowly and steadily getting there.
It's also why we think #AIOffice vision of Merlin (@MerlinAIByFoyer) is spot on.
2
11
776
19 Jun 2025
mid-week brainstorming and shippin’
this week at Foyer HQ… 🫰🏽


1
4
26
1,067
Foyer Tech Inc. retweeted
15 Jun 2025
A heartwarming, realistic photo of a young man in 2025 wearing a modern black coat-pant with clean hairstyle, standing beside his grandfather. The young man is resting his hand gently on his grandfather's shoulder, smiling softly. The grandfather is wearing a traditional white kurta-pajama with slight wrinkles of age on his face and white hair. Both are standing outdoors in soft daylight, with a peaceful, natural background (like a garden or home courtyard). The photo should look like it was taken with a DSLR camera. Make the faces match the reference photos exactly. Make the skin tones natural and lighting even. It should look like a real photo taken today, not like an AI-generated image. No extra effects, no text, no blur.

1
1
2
259
Foyer Tech Inc. retweeted
15 Jun 2025
Some generations
Cinematic overhead shot of me standing still a brick city sidesalk, wearing a dark oversized blazer, motion-blurred crowd rushes past around me moody lighng 35mm film look Shallow depth of field, sharp focus on me. Ration potrait 4:3

1
1
3
296
Foyer Tech Inc. retweeted
15 Jun 2025
Google Imagen 4 is now live in bonkers. Try it out to generate some life-looking portraits!

3
3
9
856
Foyer Tech Inc. retweeted
7 Mar 2025
hey son,
never said it out loud
but you're doing amazing✨
@MerlinAIByFoyer 🫠
2
12
3,045