
Joined January 2023
- Tweets 219
- Following 55
- Followers 279
- Likes 61
32 Photos and videos










Mar 2
Apparently ChatGPT needs 120 minutes for this question. :D
chatgpt.com/share/69a5f141-2…
1
1
288
Feb 9
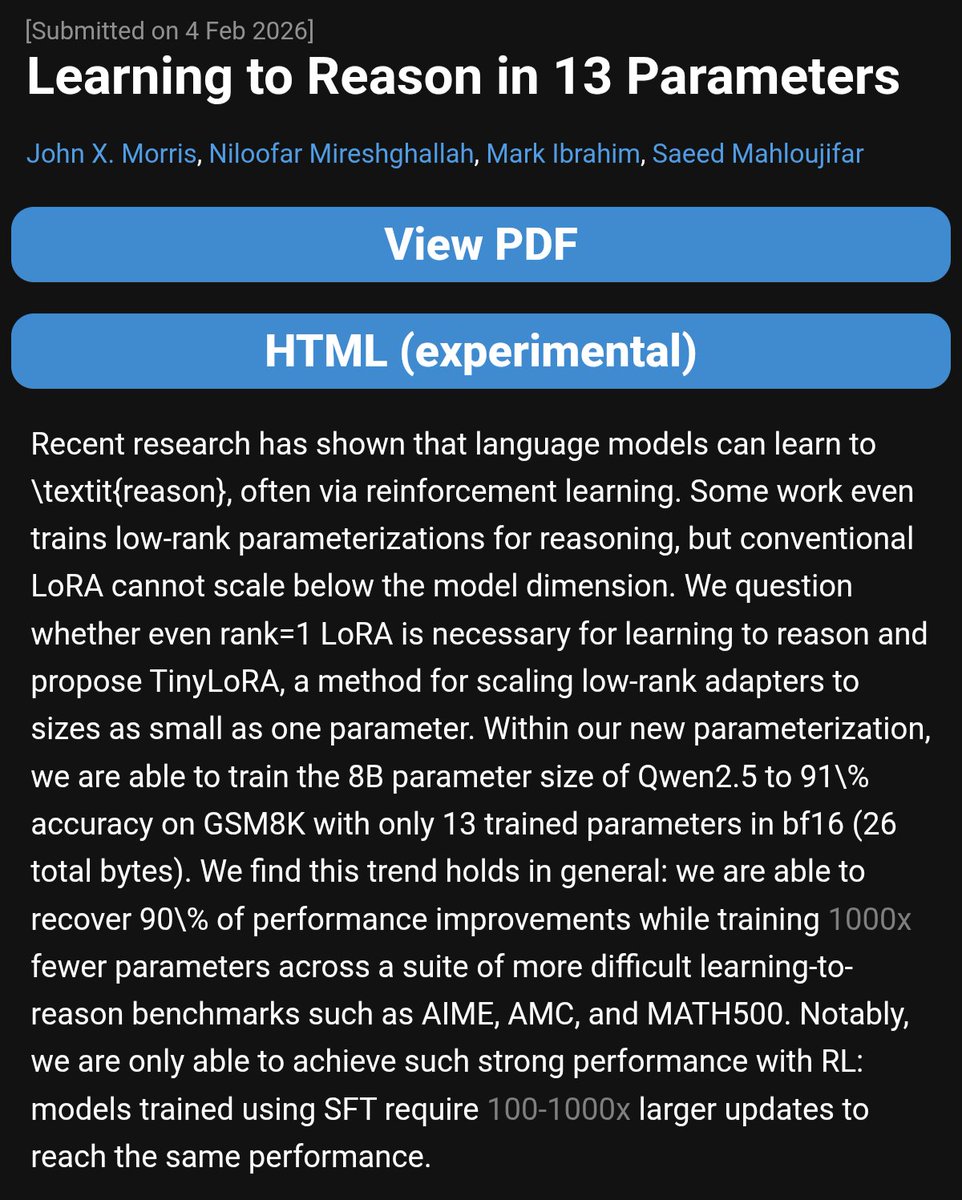
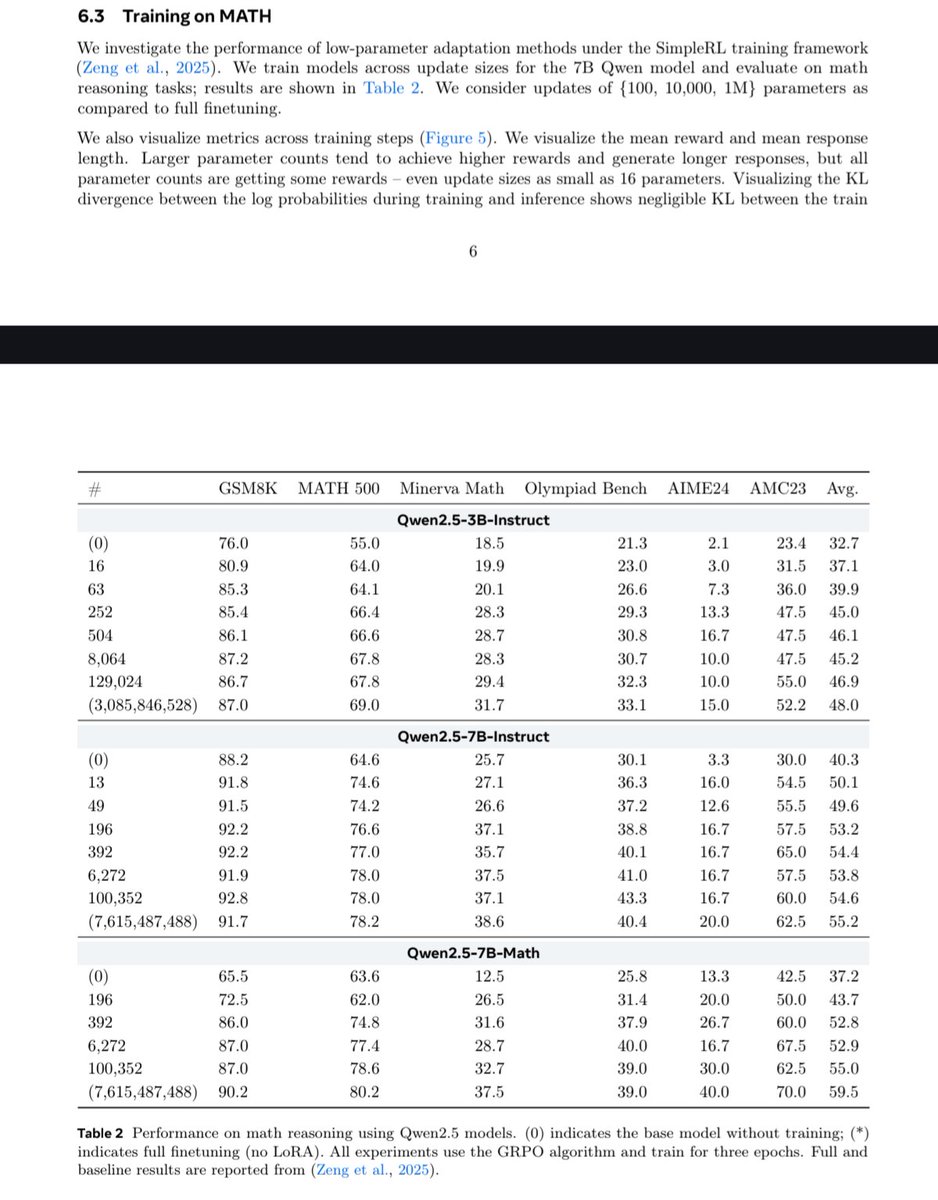
Papers like these are important for people competing in big reasoning competitions like AIMO or ARC-AGI.
The problem is that if one takes a closer look, there are some issues with the impressive claims:
- MATH is an outdated benchmark by now
- the numbers don't add up. The last sentence on page 1 states "Qwen-2.5-7B-Instruct improves from 76% to 95% while training just 10,000 parameters". This conflicts with table 2, which in turn is also unclear, as the parameter count doesn't seem to match with the # column.
1
1
10
1,376
Simon Frieder retweeted
Feb 8
Asking an AI system for an opinion is never a good idea. I am withholding judgement in whether to be impressed - it really depends on a lot of details: how many mathematicians tried and failed to prove the problem before (impossible to quantify, but that would be a measure of difficulty), what techniques the proof that was found uses (is it merely an obvious application of a know theorem that mathematicians overlooked, or did it introduce a new solution technique), etc.
An expert in the field needs to answer this -- not me, and definitely not Grok. LLMs still don't know what they don't know.
This is way over the head of Grok, and it's "arguments" are very weak since they would apply to any other piece of autoformalized result.
1
1
389
Feb 8
Is mathematics a game that is still worth playing in the long term?
The Twittersphere abounds with examples of what LLMs can do in math -- optimism is sky-high.
(I don't quite share that optimism since (open-source) LLMs do not even manage to solve the all "simple" unseen problems we have over at the AI Math Olympiad with the LB being stuck at 44/50.)
If that optimism pans out, even more maths will be created (rather than read) in the near future. While at first it will be exciting to watch conjectures fall, I am wondering what personal motivation will be left in such a full-automation scenario to get good and study mathematics.
1
2
272
16 Dec 2025
In a year, we will be living in a world of mathematical ... AI slop!
I'd hope things would be different, but where they are headed now, I fear many technical, and completely uninteresting results will flood the space. arXiv already had to stop accepting position papers, and the same will happen for technical, niche research papers rather soon. There will be an occasional jewel where AI genuinely helped (although just autoformalizing right now is not that exciting to the mainstream AI-sceptical mathematician), but most pebbles that fall out of LLMs won't be these jewels, they'll be cobblestones.
16 Dec 2025

In a year, we will be living in a world of mathematical abundance.
4
1
6
1,097
16 Dec 2025
Why Lean automation alone will not automate math -- here's more to the "automation" story than what Lean can express.
16 Dec 2025

1/ Having a strong Lean engine is definitely a nice thing to have -- but there are limits to what is natural to do in Lean (or any formal systems).
I'm reminded here of the nice example that Patrick Massot mentioned in his talk about the concept of ... limits in calculus [1] :)
If you want to formalize all possible variants of each type of limit at a point of a function in a "naive" way, there are many definitions to state: of the limit at a point with the limit equaling a number, of the limit at a point with that point remove equaling infinity, etc. If you count them, it seems to amount to actually 256 (!) definitions (see the 45m30s mark of the video).
There are two ways out of this: 1) In practice, no one gets taught all 256 definitions but rather one teaches the "abstract generator" behind the definition. 2) One abstract all these away by using ultrafilters, and then just teaches limits in the setting of ultrafilters.
Both ways then also help to reduce the sprawling number of plumbing lemmas (like composition of two lemmas) that one otherwise would help to prove about limits (which are 4096 according to the video, which seems plausible).
Both solutions are possible execute in Lean, but are awkward to perform.
[1] youtube.com/watch?v=1iqlhJ1-…
1
6
748
7 Dec 2025
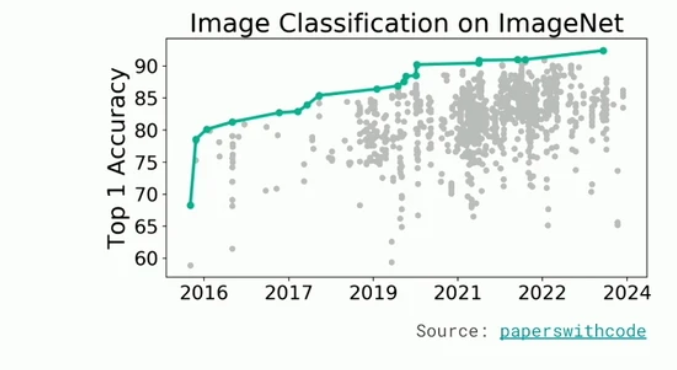
2023: It's hard to devise an LLM that solves a math problem.
2025: It's hard to devise a math problem that stumps and LLM.
(...this in the context of competitive math questions, but we'll also get to research-level math soon)
1
5
838
Simon Frieder retweeted

5 Dec 2025
AIMO3 is full of surprises: week 2 (out of 21) just concluded. After a race in the first week that had us both biting our nails to see how quickly the leaderboard is rising and cheering for the progress of open-weight LLMs, the leaderboard suddenly ground to halt.

3
2
13
1,255
1 Dec 2025
Mathematics may get very exciting soon - and then very boring.
1
2
209
1 Dec 2025
My reason for this somewhat provocative claim is that the nature of mathematics will transform by quite a bit once LLMs go mainstream for mathematicians. I see some posts here and there on X, but these are early adopters, mathematicians that are interested in ML. The large majority of research mathematicians hasn't yet much explored working with LLMs from what I gather speaking with professors at various universities.
Once LLMs go mainstream, I predict a lot of conjectures will be solved. This will generate a few years of excitement. But what comes next?
Probably a bit of fun will go out if mathematicians become curators of math knowledge (produced by LLMs) rather than producers of knowledge.
Some domains are already so well developed (parts of algebraic geometry), and the road to mastering these domains so long, that it may just become infeasible to even learn, as a human, what the frontier is - this will take out another bit of fun.
That's why, for humans, my long-term take is rather pessimistic: we will produce a lot more mathematical knowledge, more the ever before, but it won't be as fun anymore and probably fewer people will want to do it, and who is to say that the usual "escape to abstraction" that was often the way to resist automation, will resist LLMs?
163
30 Nov 2025
A 5-point update on how the latest release of DeepSeek-Math-V2 affects the AIMO.
In the meantime, working hard to get this 700GB monster to run on my 8x H100 to test it.
Can't wait for Unsloth and some of the other quantization wizards to release smaller versions!
30 Nov 2025

1/ If DeepSeek-Math-V2 is behind the recent score jump to 38/50, then fitting a ~700GB model into a single H100 that has approx. 6 minutes of runtime per math problem (these are the Kaggle constrains) a day after its release would be an impressive achievement.
8
905
29 Nov 2025
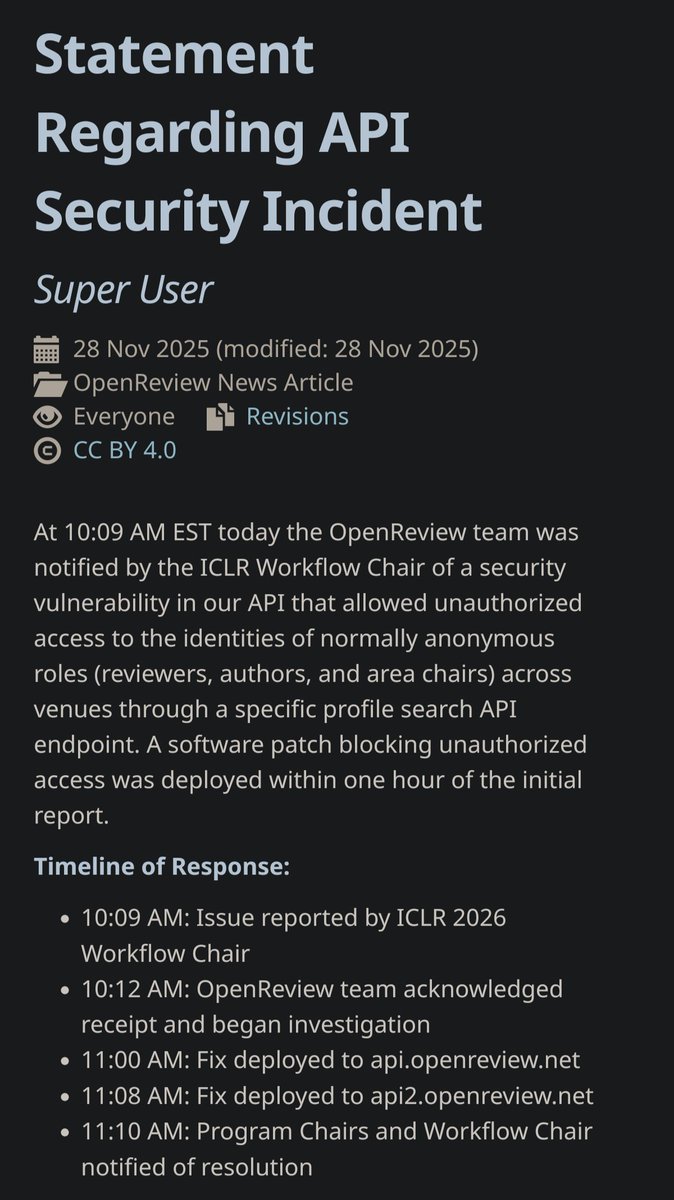
One more nail in the coffin for a broken reviewing system. Who knows how many people silently used this backdoor to see who gave them bad scores -> potentially career-damaging.
It would be much better to have a comment section in arXiv, this would solve 80% of the existing problems: only people that are actually interested in the paper would read it, there would be no arbitrary cutoff who made it or not and no useless scores (the infamous NeurIPS experiment demonstrated -unsurprisingly- a large degree of subjectivity inverseprobability.com/talks…), nasty reviews would occur less frequently if your name is attached, there is no possibility to have an ongoing dialogue that reflect what the community thinks of the paper since nothing can be done after the rebuttal phase which is artificial and sometimes a longer dialogue would beneficial (who remember the "Understanding deep learning requires rethinking generalization" paper
? openreview.net/forum?id=Sy8g… ), etc etc
1
3
343
25 Nov 2025
Longevity is a very interesting subject, at the intersection of biology & benchmarks.
I recognize some ML names in this paper that did an analysis of health interventions at a scale never before achieved.
@bryan_johnson take note ;)
biorxiv.org/content/10.1101/…
172
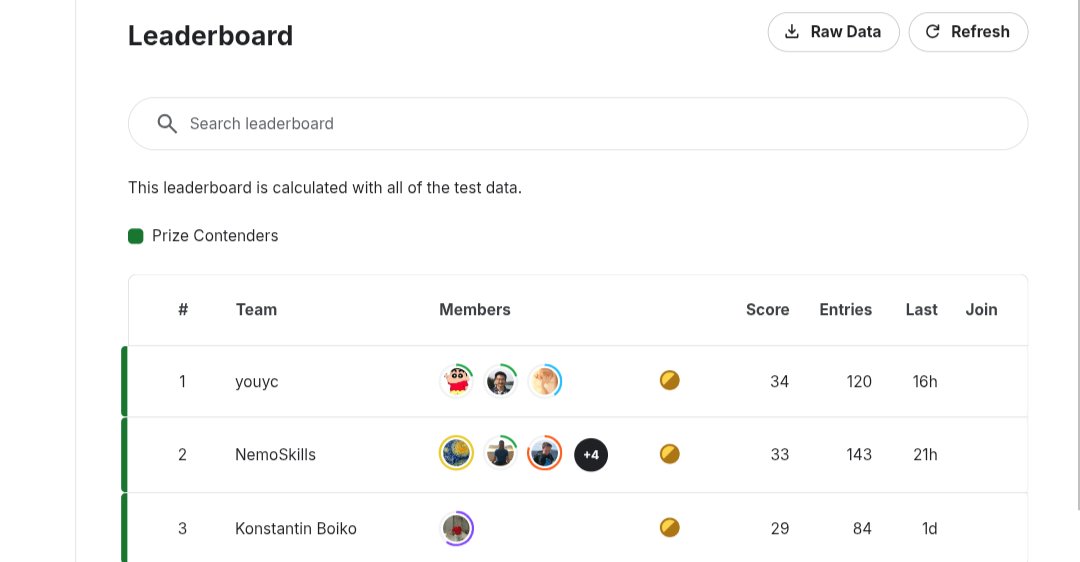
22 Nov 2025
AIMO1 achieved 29/50, AIMO2 achieved 34/50, AIMO3 will achieve... ?
22 Nov 2025
AIMO history 📚
AIMO1 (2024): Won by Project Numina
→ 1,000 teams
→ Largest reasoning competition ever
AIMO2 (2025): Won by NVIDIA NemoSkills
→ 2,000 teams
→ Problems got harder, models got better
AIMO3 (2025): Your turn.
The wave keeps rising. Rise with it 🚀

1
11
1,091
21 Nov 2025
AIMO2 ran for 5 months and had a total 16,000 entrants (people that registered, but not necessarily submitted a model - those are known as "participants").
AIMO3 is running for less than a day and already has 2,000 entrants.
At this pace we might need to source more H100s :D
2
8
267
20 Nov 2025
Can you solve this Olympiad-level problem?
This is the mind of problems LLMs have to solve to compete at the third AI Math Olympiad.
1
6
721
20 Nov 2025
Most likely the most biggest and advanced reasoning competition in world right now.
20 Nov 2025
AIMO3 has launched! Check out our mini-benchmark of reference problems below & help us shrink the gap to commercial LLMs to zero!

3
2
11
1,423
14 Nov 2025
Prepare for the long night! AIMO3 is coming! More information next week.
13 Nov 2025

10
423
31 Oct 2025
And just like that - you can access Lean Finder now using Lean MCP. Very convenient.
The story: Wuyang Chen wrote me to tell me about the recently released Lean Finder, I posted this the same day on an internal channel where Cameron Freer (whose screenshot mentioned that it would be useful to have this integrated into Lean MCP. I connected the dots, contacted Oliver Dressler soon after. Everyone worked closely together and less than a week the integrations was done.
Happy agenting!
1
5
377
1 Nov 2025
* [...] whose screenshot can be seen below), mentioned [...]
1
144