
Joined May 2025
- Tweets 7,502
- Following 866
- Followers 5,008
- Likes 8,139
723 Photos and videos













Pinned Tweet

May 12
🎉La guía ha sido lanzada 🚀
Llevas meses queriendo empezar en Ciencia de Datos, guardando cursos y sin una ruta clara 📊
Llevo 8 años desarrollando en el mundo del dato y se lo que cuesta empezar.
La sobreinformación te frena.
He escrito algo GRATIS para que eso se acabe👇

2
9
51
12,180
GalisLab 💻📊 retweeted
Jun 13
😨 La semana que viene empiezo en mi nueva empresa y estoy acojonado.
Da igual los años que lleve trabajando, o que me haya cambiado de empresa 4 veces.
Los nervios, el miedo y la incertidumbre siempre estarán ahí.
Cara nuevas, retos nuevos, expectativas sobre ti… no saber lo que te vas a encontrar es horrible.
Pero ojo, también está la otra parte:
Me encanta volver a tener esos nervios.
Hacía tiempo que no sentía motivación por el trabajo, y el hecho de entrar en un nuevo proyecto, demostrar mi experiencia y ganarme al equipo, vence al miedo.
👉🏻 Cuando entras en una nueva empresa, los primeros meses son clave.
Exista o no un periodo de prueba, esa primera impresión puede determinar tu rumbo a largo plazo.
📝 Estos consejos me los dio un antiguo jefe, y tengo que darle la razón en cada uno de ellos.
Apunta ⬇️
→ Se proactivo.
→ Hazte notar, no vayas de low profile.
→ Aporta valor y soluciones.
→ No te quedes callado en las reuniones.
→ Conoce a tus compañeros, tómate un café (virtual) con cada uno de ellos.
→ Pregunta mucho, que no te de vergüenza.
Yo te los comparto por si alguna vez pasas por esa misma situación.
🍀 Espero que te sirvan, a mi siempre me han funcionado.
1
3
52
5,062
GalisLab 💻📊 retweeted
Jun 13
🧑🏫 Curso de Fundamentos de Datos con certificado de Google.
→ Introducción al análisis de datos
→ Ciclo de vida del dato
→ SQL, visualización, ...
🔗 coursera.org/learn/foundatio…
¡Datos, datos, por todos lados!
15
77
3,644
Jun 13
¿No queréis aprovechar el fin de semana y tener un certificado de Google de Fundamentos de Datos? 🤯
Toda la info aquí 👇🏻
Jun 13

🧑🏫 Curso de Fundamentos de Datos con certificado de Google.
→ Introducción al análisis de datos
→ Ciclo de vida del dato
→ SQL, visualización, ...
🔗 coursera.org/learn/foundatio…
¡Datos, datos, por todos lados!
12
1,253
Jun 12
Explora, analiza e interactua con tus dataframes de Pandas o Polars a traves de una interfaz sin necesidad de código.
Directamente desde Python en tu notebook.
Echa un vistazo a esta herramienta gratuita y de codigo abierto 👇
Jun 12
📊Visualiza y explora tus datos de manera sencilla con esta librería de Python.
PyGWalker convierte tus Dataframes en una UI interactiva y crea gráficos fácilmente sin escribir código.
→ Simplifica el EDA
→ Análisis Drag&Drop
→ Código abierto
🔗 github.com/Kanaries/pygwalke…
1
10
1,140
Jun 12
📊Visualiza y explora tus datos de manera sencilla con esta librería de Python.
PyGWalker convierte tus Dataframes en una UI interactiva y crea gráficos fácilmente sin escribir código.
→ Simplifica el EDA
→ Análisis Drag&Drop
→ Código abierto
🔗 github.com/Kanaries/pygwalke…
2
17
76
4,199
Jun 11
Que el finiquito de mi empresa antigua va 50% a BTC y 50% a Oro ni se negocia.
4
12
4,742
Jun 11
En una entrevista de Ciencia de Datos o ML van a preguntarte por las diferentes métricas que existen 📊
¿Conoces otras métricas además del Accuracy?
Te enseño 3 de las más importantes cuando ésta no es suficiente 👇🏻
Jun 11
¿Conoces la diferencia entre la Precisión, el Recall y el F1 Score? 📊
Aprende cuando utilizar cada métrica y no te quedes en blanco en tus entrevistas de ML o Ciencia de Datos 👇
No siempre hay que utilizar el Accuracy, es muy engañoso cuando tienes datasets desbalanceados.
🧑🏫 Por ejemplo, diseñas un modelo de detección de fraudes, donde el 99% de datos son legítimos (Fraude = False), solo tienes un 1% que te indica un frade → Dataset desbalanceado.
Si tu modelo dice que todo es seguro, tendrás un Accuracy brutal ~ 99%, pero su es totalmente inutil.
🟢 Ahí es donde entran estas tres métricas: Precisión, Recall, F1.
👉 Precisión (¿Cuánto de lo que aseguro es verdad?):
De todas las veces que tu modelo dice "esto es positivo", ¿cuántas veces ha acertado? Una precisión alta significa que apenas das falsas alarmas. Te interesa priorizarla cuando un falso positivo sale carísimo.
(Filtro de spam bloqueando un correo importante de un cliente)
👉 Recall (¿Cuánto se me ha escapado?):
De todo lo que realmente era positivo en tus datos, ¿cuánto has sido capaz de pillar? Un recall alto significa que dejas pasar muy pocos casos. Es la métrica reina cuando un falso negativo es imperdonable.
(Un modelo médico pasando por alto un tumor)
👉 ¿Y el F1 Score?:
Es el arbitro. Si ajustas el modelo para que sea súper estricto y no falle (alta precisión), se te escaparán casos. Si lo abres para pillarlo todo (alto recall), te comerás muchas falsas alarmas → Trade-off
El F1 equilibra ambas métricas. Es ideal cuando te importan los dos tipos de errores por igual.
📐 ¿Cómo se calculan?:
Precision = TP / (TP FP)
Recall = TP / (TP FN)
F1 Score = 2 × (Precision × Recall) / (Precision Recall)
Donde:
TP → True Positives (correctly predicted positive)
FP → False Positives (predicted positive, actually negative)
FN → False Negatives (predicted negative, actually positive)
TN → True Negatives (correctly predicted negative)
✍️ Cuándo utilizar estas métricas:
Cuando las clases estén desbalanceadas, cuando los diferentes tipos de errores tengan costes distintos, o cuando necesites justificar la elección de tu umbral en una entrevista.
6
1,008
Jun 11
¿Conoces la diferencia entre la Precisión, el Recall y el F1 Score? 📊
Aprende cuando utilizar cada métrica y no te quedes en blanco en tus entrevistas de ML o Ciencia de Datos 👇
No siempre hay que utilizar el Accuracy, es muy engañoso cuando tienes datasets desbalanceados.
🧑🏫 Por ejemplo, diseñas un modelo de detección de fraudes, donde el 99% de datos son legítimos (Fraude = False), solo tienes un 1% que te indica un frade → Dataset desbalanceado.
Si tu modelo dice que todo es seguro, tendrás un Accuracy brutal ~ 99%, pero su es totalmente inutil.
🟢 Ahí es donde entran estas tres métricas: Precisión, Recall, F1.
👉 Precisión (¿Cuánto de lo que aseguro es verdad?):
De todas las veces que tu modelo dice "esto es positivo", ¿cuántas veces ha acertado? Una precisión alta significa que apenas das falsas alarmas. Te interesa priorizarla cuando un falso positivo sale carísimo.
(Filtro de spam bloqueando un correo importante de un cliente)
👉 Recall (¿Cuánto se me ha escapado?):
De todo lo que realmente era positivo en tus datos, ¿cuánto has sido capaz de pillar? Un recall alto significa que dejas pasar muy pocos casos. Es la métrica reina cuando un falso negativo es imperdonable.
(Un modelo médico pasando por alto un tumor)
👉 ¿Y el F1 Score?:
Es el arbitro. Si ajustas el modelo para que sea súper estricto y no falle (alta precisión), se te escaparán casos. Si lo abres para pillarlo todo (alto recall), te comerás muchas falsas alarmas → Trade-off
El F1 equilibra ambas métricas. Es ideal cuando te importan los dos tipos de errores por igual.
📐 ¿Cómo se calculan?:
Precision = TP / (TP FP)
Recall = TP / (TP FN)
F1 Score = 2 × (Precision × Recall) / (Precision Recall)
Donde:
TP → True Positives (correctly predicted positive)
FP → False Positives (predicted positive, actually negative)
FN → False Negatives (predicted negative, actually positive)
TN → True Negatives (correctly predicted negative)
✍️ Cuándo utilizar estas métricas:
Cuando las clases estén desbalanceadas, cuando los diferentes tipos de errores tengan costes distintos, o cuando necesites justificar la elección de tu umbral en una entrevista.
2
14
1,481
GalisLab 💻📊 retweeted
Jun 10
Hace dos meses pedí un aumento de sueldo en mi empresa y me lo rechazaron ❌
Esto es 100% real.
Me dijeron que la situación de la empresa era delicada y tenían las subidas congeladas.
En este tiempo he estado buscando un cambio y hace dos semanas acepte una oferta.
Cuando comuniqué la decisión de irme, me dijeron que si los motivos eran económicos, podíamos llegar a un acuerdo.
Lo cierto es que el dinero no ha sido una motivación para irme, sino la inestabilidad y la incertidumbre.
Me parece una red flag de manual que una empresa solo se preocupe por el bienestar del empleado cuando este decide irse 🚩
Se les va una persona que lleva 3 años en la empresa, y saben lo que les va a costar encontrar a un perfil con 8 años de experiencia y llegue al punto donde yo estoy actualmente.
Así funcionan, solo actúan cuando se ven con el marrón encima.
Si tu empresa te tiene estancado, con el sueldo congelado, con proyectos que no te motivan y olvidado, no esperes a que tu empresa cambie.
El cambio tienes que buscarlo tu.
19
15
289
45,018
Jun 10
¿Has probado ya Grok Build como alternativa a Claude Code, Codex, Gemini o Copilot?
👉 Skills, plans, plugins, subagentes...
Puedes empezar gratis:
🔗 x.ai/cli
2
610
Jun 10
Como no meta algo de Ciencia de Datos o del sector IT en un post, el algoritmo me manda al destierro 😆
Ni 100 views 👇🏻
Jun 10
¿Será que cumplimos uno de los objetivos de este año estando todavía en junio?
Empecé el año por debajo de 3.000 seguidores y estamos a nada de llegar a los 5k 🤯
5
11
1,462
Jun 10
¿Será que cumplimos uno de los objetivos de este año estando todavía en junio?
Empecé el año por debajo de 3.000 seguidores y estamos a nada de llegar a los 5k 🤯
5
1,862
GalisLab 💻📊 retweeted
Jun 9
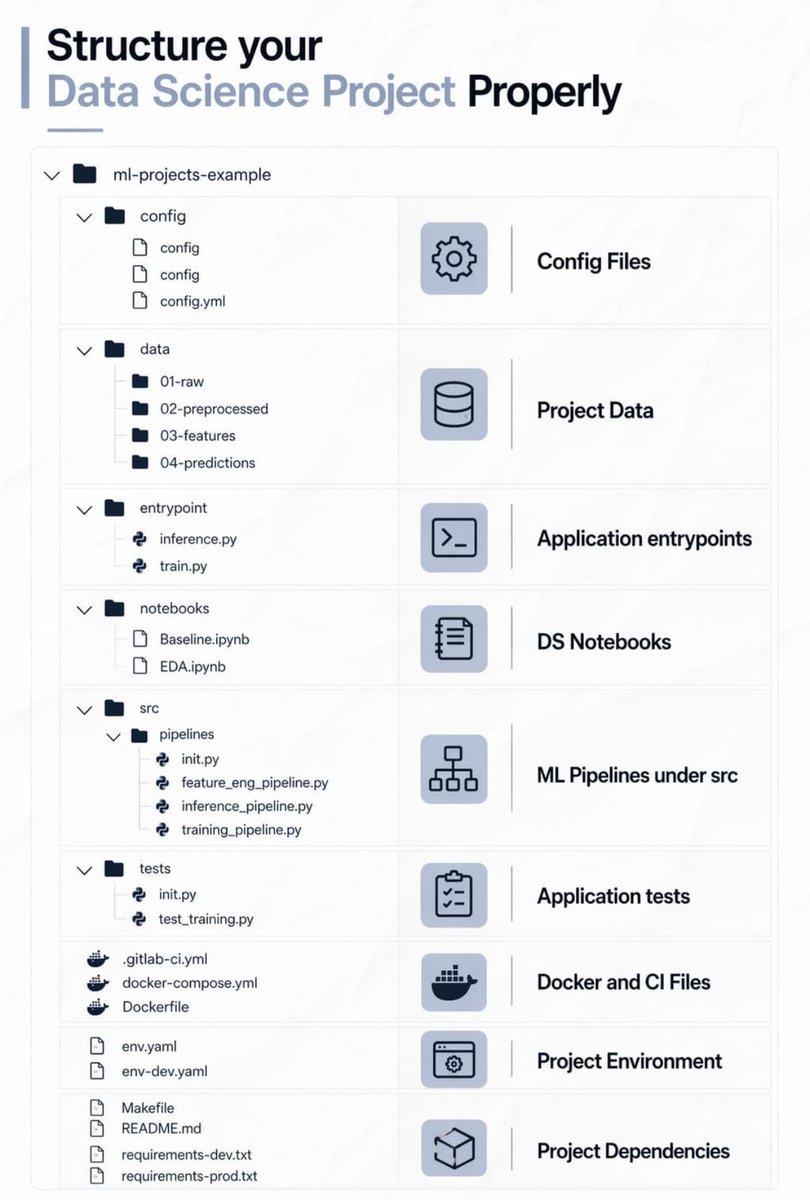
❌ Deja de estructurar mal tus proyectos de Ciencia de Datos.
Usa este metodo, simple, limpio y listo para producción 📊 👇
1️⃣ config/ – archivos de configuración
Separa los parametros del código (local . yaml, prod . yaml)
2️⃣ data/ – ciclo de vida completo del dato
Raw → preprocessed → features → predictions
3️⃣ entrypoint/ – Scripts principales
train . py (pipeline)
inference . py (batch/real-time)
4️⃣ notebooks/ – solo exploración
EDA, análisis → nunca lógica de producción
5️⃣ src/ – código principal de ML
Feature engineering, entrenamiento, inferencia (modular testeable)
6️⃣ tests/ – checks automatizados
Prevención de errores silenciosos
7️⃣ docker env files – reproducibilidad
Misma setup en cualquier entorno (CI)
8️⃣ Dependencias fijas – estabilidad
Versiones exactas → resultados consistentes
No esperes al final del proyecto para ordenar tu repositorio.
Empieza poniendo orden desde un principio y lo agradecerás luego.
Esta estructura es un ejemplo sencillo, y se puede complicar todo lo que quieras, pero te sirve para tener un punto de partida.
3
30
191
6,340
Jun 9
🗂️ ¿Como organizas los ficheros y carpetas de tus proyectos?
Hoy te cuento la mejor manera de estructurar tu proyecto de Data desde un principio.
Sencillo y organizado, guárdatelo para más tarde 👇🏻
Jun 9
❌ Deja de estructurar mal tus proyectos de Ciencia de Datos.
Usa este metodo, simple, limpio y listo para producción 📊 👇
1️⃣ config/ – archivos de configuración
Separa los parametros del código (local . yaml, prod . yaml)
2️⃣ data/ – ciclo de vida completo del dato
Raw → preprocessed → features → predictions
3️⃣ entrypoint/ – Scripts principales
train . py (pipeline)
inference . py (batch/real-time)
4️⃣ notebooks/ – solo exploración
EDA, análisis → nunca lógica de producción
5️⃣ src/ – código principal de ML
Feature engineering, entrenamiento, inferencia (modular testeable)
6️⃣ tests/ – checks automatizados
Prevención de errores silenciosos
7️⃣ docker env files – reproducibilidad
Misma setup en cualquier entorno (CI)
8️⃣ Dependencias fijas – estabilidad
Versiones exactas → resultados consistentes
No esperes al final del proyecto para ordenar tu repositorio.
Empieza poniendo orden desde un principio y lo agradecerás luego.
Esta estructura es un ejemplo sencillo, y se puede complicar todo lo que quieras, pero te sirve para tener un punto de partida.
5
967
GalisLab 💻📊 retweeted
Jun 8
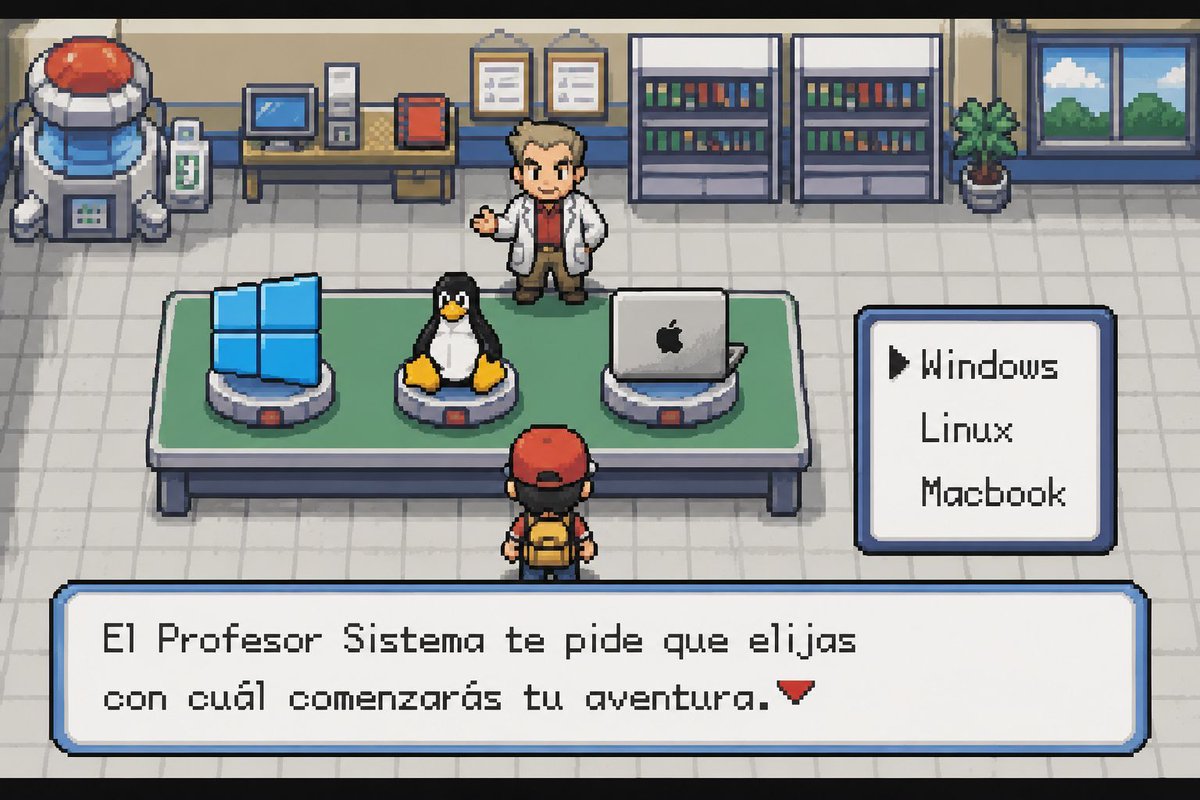
Mi empresa nueva me ha dado a elegir entre Windows, Linux o Macbook como equipo de trabajo.
Yo no he dudado ni un segundo.
50
51
1,072
112,580