
Building things at @PixelgenTech. Chronically curious. Molecular medicine PhD. Formerly: @OlinkProteomics, @scilifelab
Joined October 2015
- Tweets 363
- Following 282
- Followers 220
- Likes 351
10 Photos and videos







Johan Dahlberg retweeted

13 Jun 2023
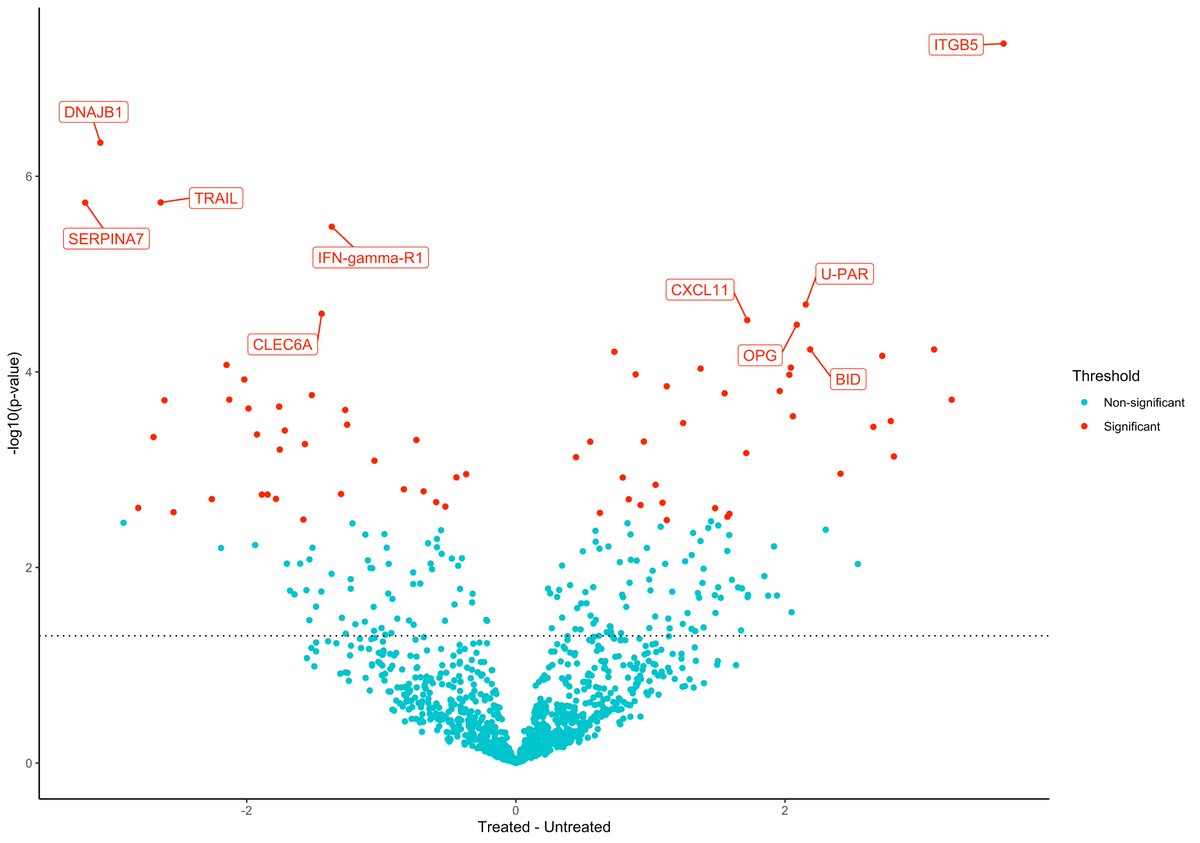
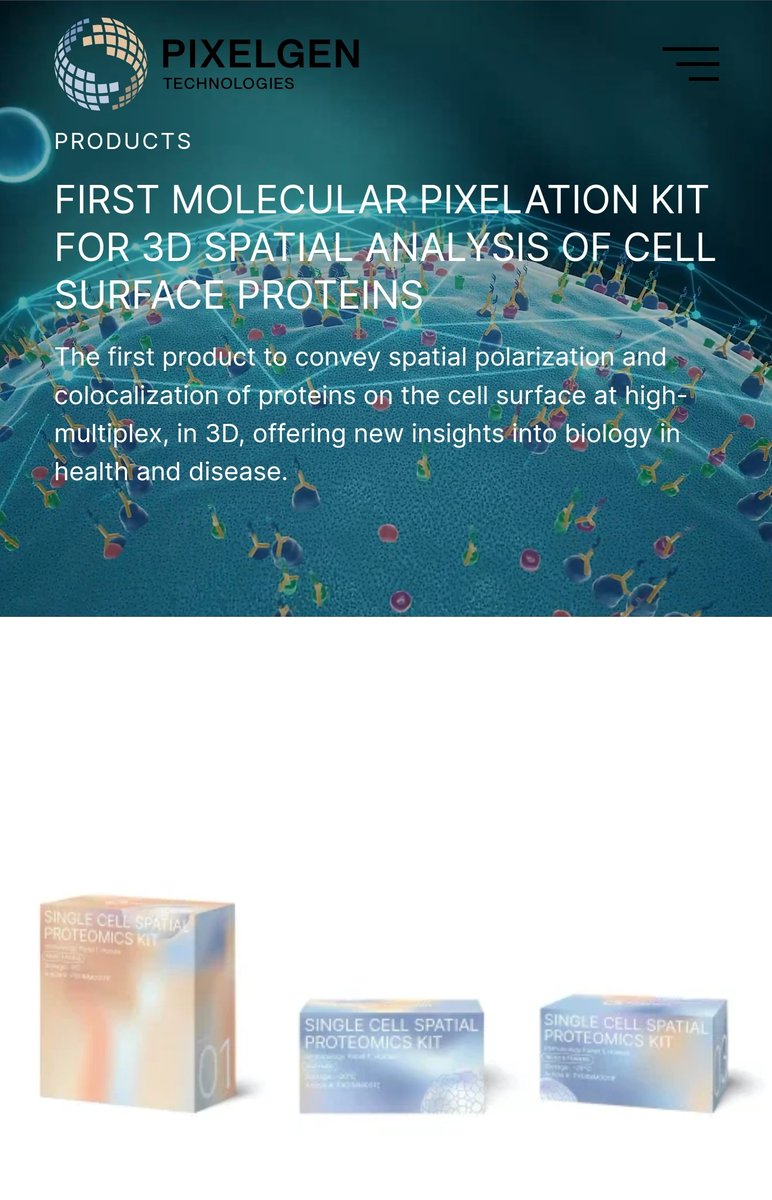
Exciting times begin with @PixelgenTech launching their first Kit. Read about it more on pixelgen.com/products/
#pixelgen #molecularpixelation #spatialproteomics #singlecell #80plex #immunology #newtechnology

1
2
438

23 Mar 2023
Join the @PixelgenTech team as a immunology application scientist! Great team and so much exciting science ahead of us. careers.pixelgen.com/jobs/25…
1
78
13 Mar 2023
Listen to Simon talking about the exciting stuff we're doing at @PixelgenTech.
9 Mar 2023

New Spatial Company Maps Cell Surface Proteome without Imaging
Podcast with Simon Fredriksson, CEO @PixelgenTech
mendelspod.com/podcasts/new-…
#spatialbiology #proteomics #immunology #proteomics

3
4
246
Johan Dahlberg retweeted

8 Feb 2023
Come by and say hi #AGbt2023 #AGBT23 breakfast #PixelgenTechnologies #MolecularPixelation #singleCellProteomics

2
3
430
7 Feb 2023
If you are at AGBT make sure to go and say hi to my nice colleagues at @PixelgenTech and learn more about what we do. Not there? No worries, you can have a look at the poster here: pixelgen.com/AGBT2023_Pixelg…
7 Feb 2023

Don't forget to visit poster number 538 today at AGBT from Pixelgen Technologies and learn about Molecular Pixelation @PixelgenTech #agbt23
1
4
231
17 Oct 2022
Join the team as our new field bioinformatics scientist! careers.pixelgen.tech/jobs/2…
1
15 Sep 2022
Hey! Wanna join the @PixelgenTech team? We have to exciting positions for bioinformaticians/comp. biologists out now:
careers.pixelgen.tech/jobs/1…
careers.pixelgen.tech/jobs/2…
There is plenty of exciting stuff to do, and nice people to do it with.
1
1
28 Jun 2022
Want a t-test with a volcano plot visualization for your Olink data? No problem! Check out the OlinkAnalyze R-package for analyzing Olink data. You'll find it here on Github: github.com/Olink-Proteomics/… #RStats #proteomics #olink #bioinformatics
28 Jun 2022

Olink® Analyze 3.1 is an R software package to streamline analysis of Olink data. This versatile toolbox supports the entire Olink portfolio, making data analysis easier to facilitate the extraction of biological insights from Olink data. Press release: bit.ly/3bdRQ5f

1
5
17 May 2022
Here is what I've been working on recently @OlinkProteomics excellently explained by our UX-wizard! Want an invitation? Reach out to me and I'll get it sorted. We are super excited to hear how you like it, and what you'd like to see next.
1
1
3
17 May 2022
You can also learn more about Olink Insight, and sign-up for an invite here: info.olink.com/olink-insight…
Johan Dahlberg retweeted

23 Jun 2021
Today we announce the Olink Explore 3072 high throughput #proteomics platform, offering uncompromised data quality with coverage of all major biological pathways. PEA combined with NGS readout on @illumina platforms. Available for pre-order. Read more at hubs.la/H0QRJSp0
12
16
2 Jun 2021
Want to help us build high quality software @OlinkProteomics? Join us as a software quality engineer: careers.olink.com/jobs/12028…
4
Johan Dahlberg retweeted
6 May 2021
@scilifelab Uppsala is now the first certified core facility in Europe to run the Olink Explore high-throughput protein biomarker platform. Hear how #proteomics & #genomics interests converged to offer this unique technology to scientists in Sweden olink.com/scilifelab-uppsala…

1
3
6 May 2021
We are still looking for a DevOps engineer to join our team @OlinkProteomics. We are building some pretty cool stuff around here, so I hope you want to join us: olink.com/about-us/working-a… #devops #uppsalatech
1
1 Apr 2021
Come join our team at @OlinkProteomics as a DevOps-engineer! The ad is in Swedish, but Swedish is not a requirement for the job. olinkproteomics.workbuster.c…
3
4 Mar 2021
I am very curious to see where this ends up in a few years: nature.com/articles/d41586-0…
1
19 Feb 2021
That's some pretty old DNA!
18 Feb 2021

New record for the oldest #DNA ever sequenced in a study led by @CpgSthlm (@Stockholm_Uni & @naturhistoriska). “Our DNA analyses show that there were two different genetic lineages [of #mammoth]” says @love_dalen. Facilitated by @ngisweden. More: su.se/english/news/world-s-o…
4
Johan Dahlberg retweeted

10 Feb 2021
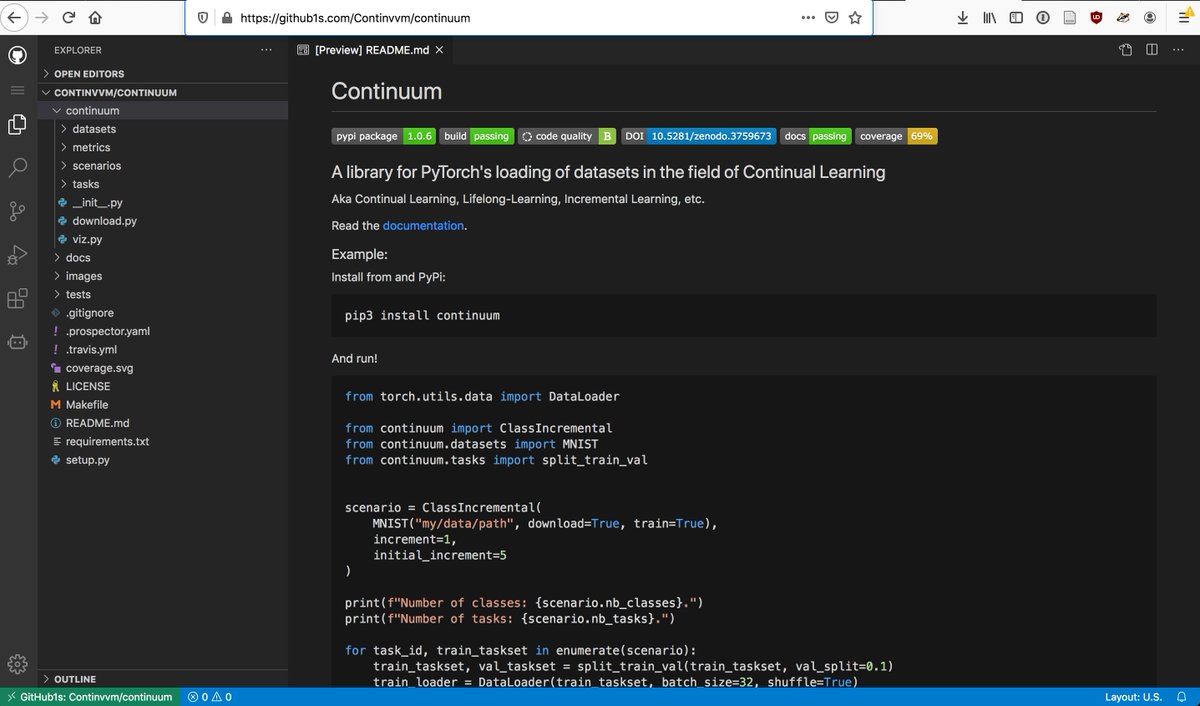
Github VSCode on your browser = 🤯
Just add "1s" before the ".com", and tada!
Here is an example with our Continual Learning library Continuum:
github1s.com/Continvvm/conti…
9
81
366
7 Feb 2021
Question for the data science folks: does anyone know of a way to define a schema for a csv file, that can then be used to generate readers for files of that type for different programing languages? So far google has failed me on this point.
2
2
3
7 Feb 2021
I.e. I want to be able to specify if a column is integer, categorical, string, etc and have that parsed correctly into for example R or Python automatically.
2