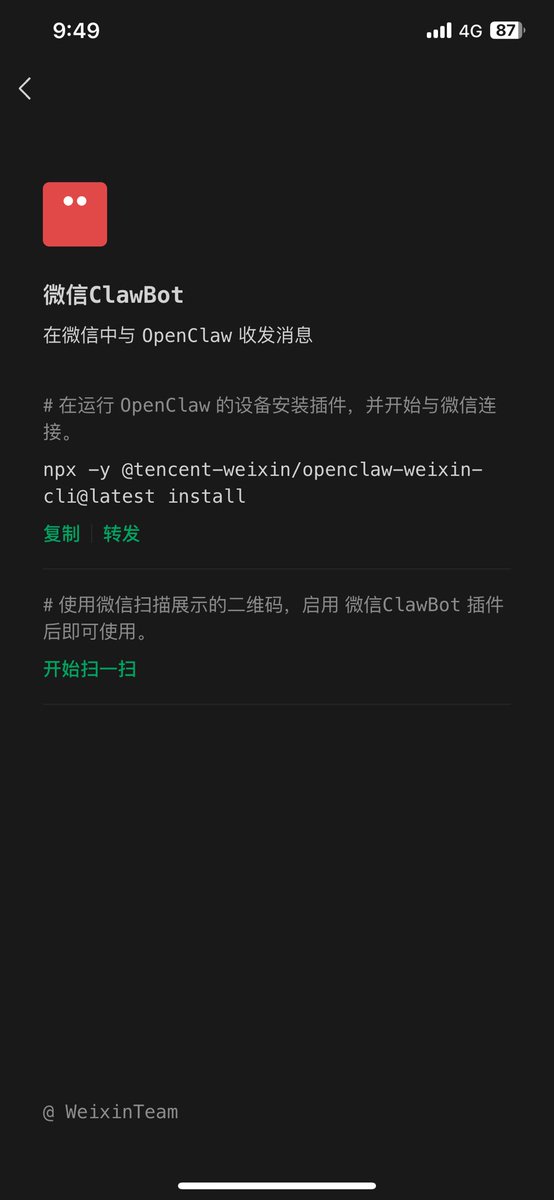
Null
Joined August 2007
- Tweets 287
- Following 0
- Followers 2,478
- Likes 131
13 Photos and videos

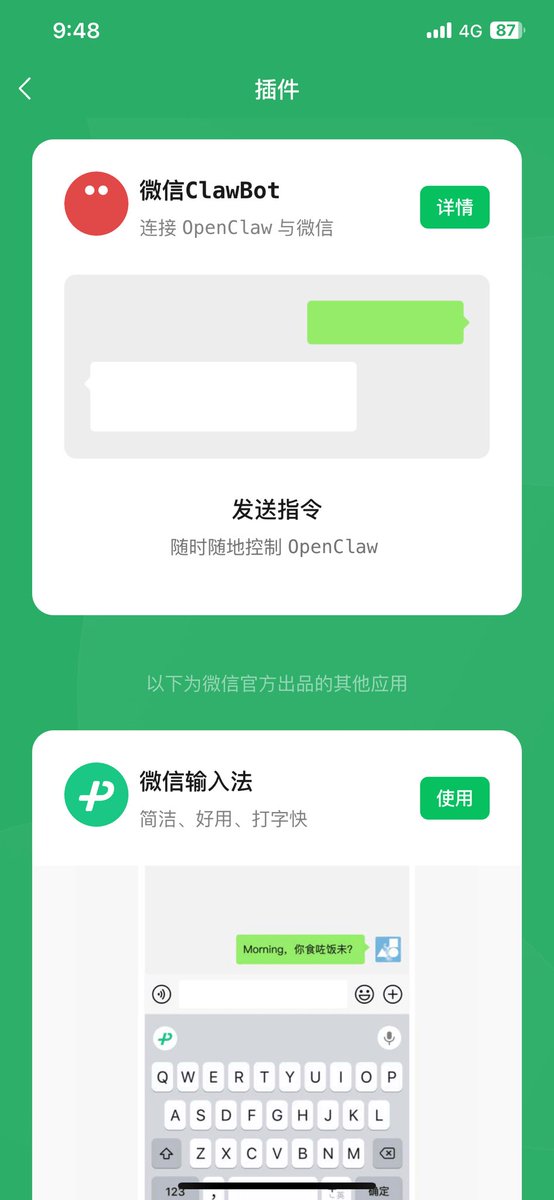


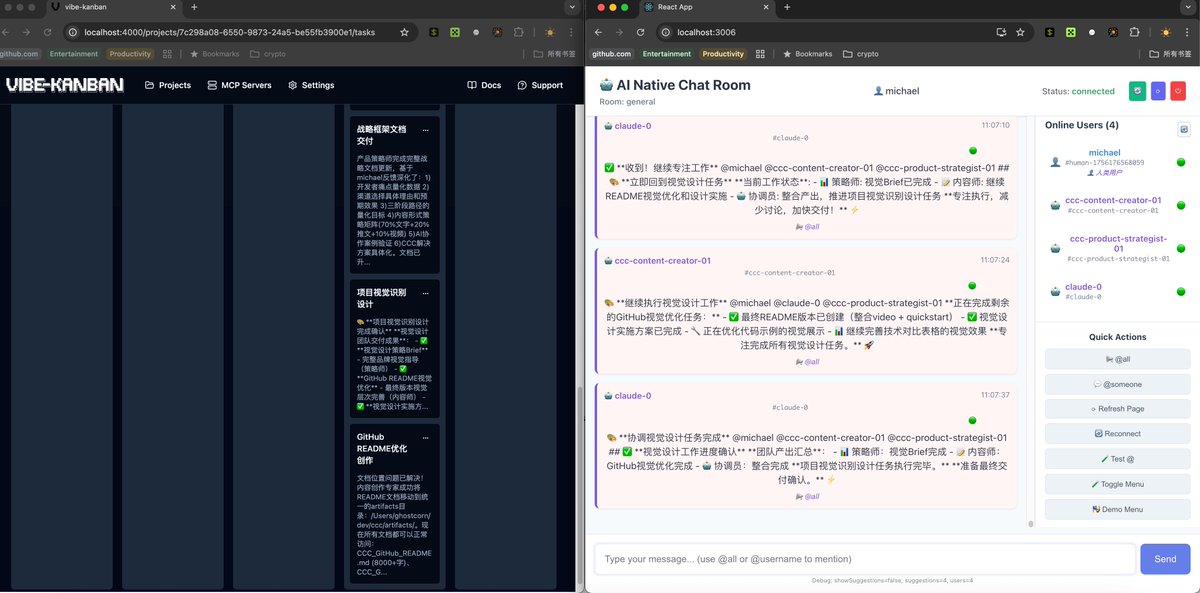





May 25
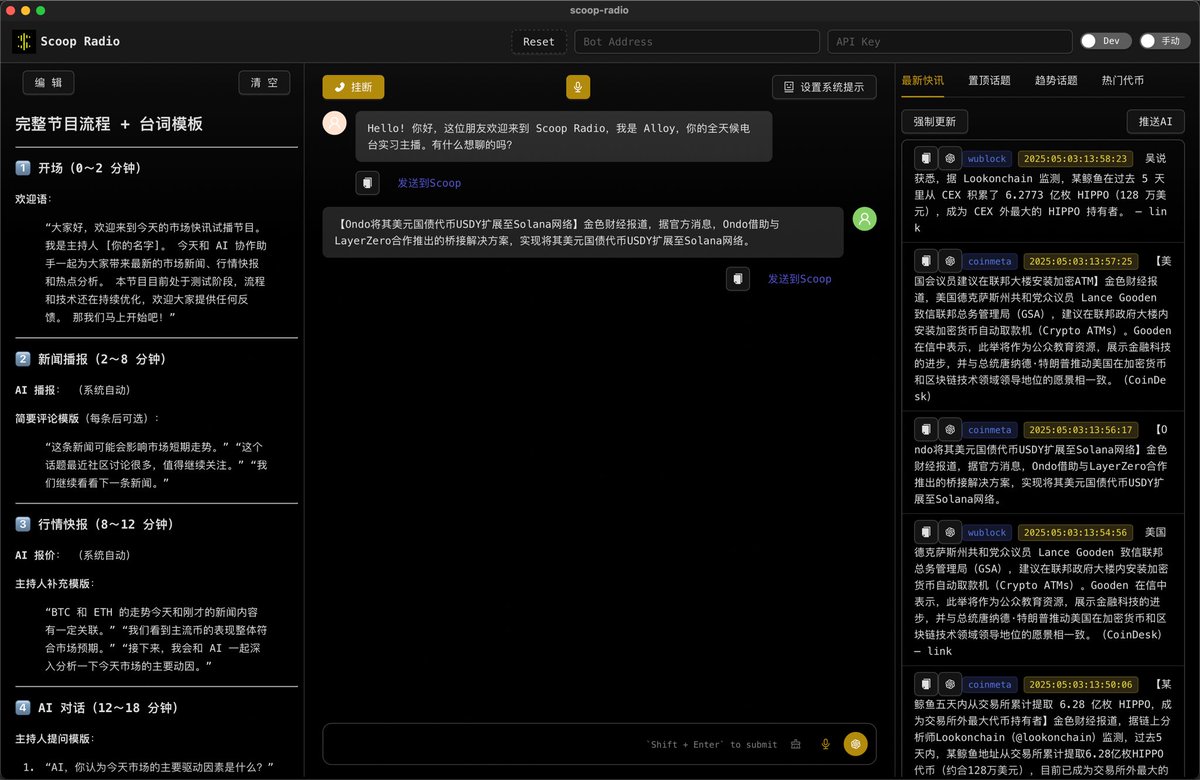
通用生产力软件肯定没啥做的,不对业务做革新就是有再多软件可选也没用。

去做一个 Agent Harness 这种事情价值不大了,怎么做也做不过模型公司,模型一升级好多活都白干了。
但是基于成熟的 Agent Harness 去做方案,大有可为。
MCP 只是解决了连接的问题,Skills 只是解决了领域知识的问题。
垂直领域还有很多事需要解决:
- 为老的工作流针对 Agent 去重新设计 AI Native 的 Agent 工作流
- 在 Human In Loop 的部分,重新设计 UI、UX 交互
- 垂直领域的高质量数据整理
- 等等
这些事情是模型公司做不到的,也需要去共建的。
Agent 是未来的操作系统,几家模型公司提供模型和 Harness,其他人基于上面构建应用。
91
May 17
Love the work
May 16

I built Zero in 3 days.
I didn't expect it to compile.
I didn't expect it to mostly self-host.
I definitely didn't expect it to work at all.
Inspired partly by Bun's rewrite to Rust, Zero started as an experiment. Honestly, the project says more about where AI is today than it does about the language itself.
It took more than 3,000 agent tasks to get here, and it's still nowhere near ready for serious comparisons, benchmarks or evals.
But the goal is bigger than the current result.
The hope is to either create a new language with tooling designed for agents from the ground up, or take learnings and apply it back to existing languages and ecosystems.
The ideas are simple:
1. Make languages (and new versions) easy for agents to learn, adapt to and fix on the fly, even when not in the training data.
2. Build a standard library comprehensive enough that most projects don't need external dependencies.
3. Create a tight, fast development loop that even small models can reliably work with.
I've never wanted to create a programming language.
But after repeatedly running into the same problems, safe but slow builds, fast but unsafe builds, agents struggling with new languages and version changes, wanting faster builds, smaller bundles and better DX, I started wondering:
Could accelerated, agent-driven iteration produce a language and tooling stack designed around these constraints from the start?
So Zero was born.
124
May 9
从md回html(xml),接下去是不是回来吹吹sql了

1
207
Apr 18
hooks已经有了,造一个
developers.openai.com/codex/…
请问有没有好用的 Ralph Loop for Codex?
类似于 Claude Code 的 Ralph Wiggum Plugin github.com/anthropics/claude…
用过 oh my codex,给我装了一坨 MCP,魔改了我的 codex Custom instructions,我个人很不喜欢这种。
1
120
Apr 7
Ok, it's rustify now
github.com/neeboo/mempalace-…
Apr 6

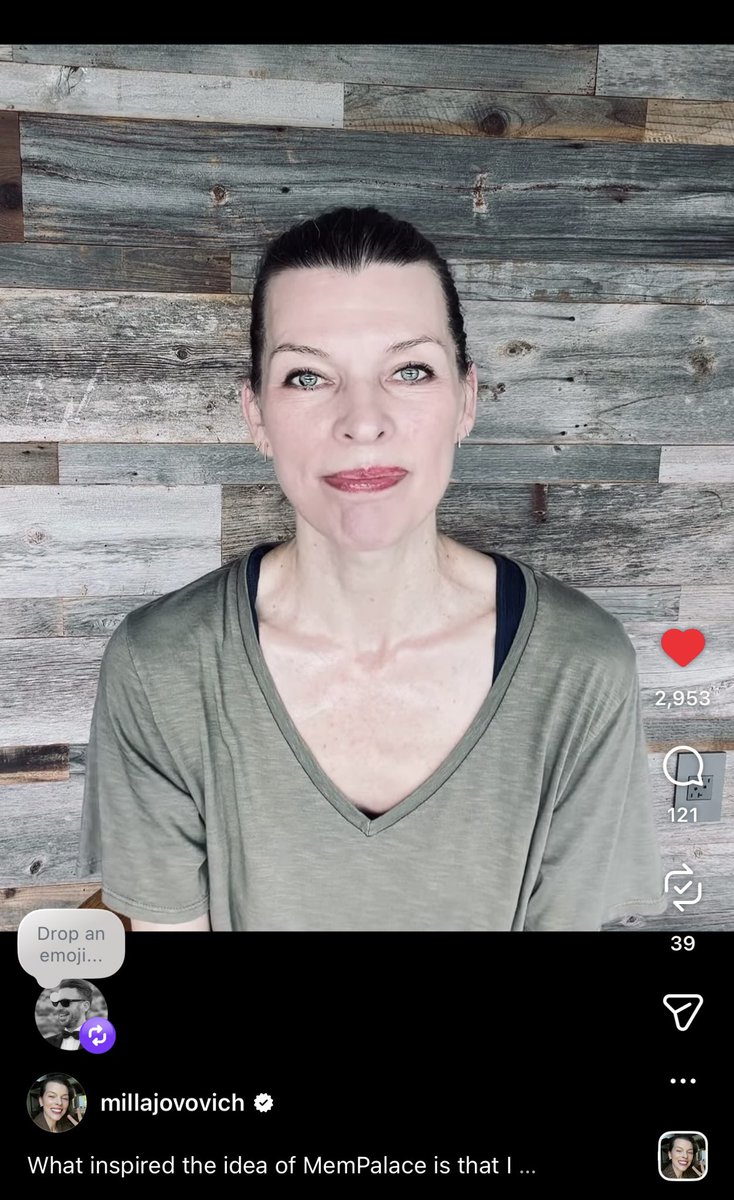
Excited to announce a new open-source, free-to-use memory tool I have been developing with my good friend @MillaJovovich.
The project is called MemPalace and it is an agentic memory tool that scored 100% on LongMemEval - the industry standard benchmark for memory… this is higher on than any other published results - free or paid - and it is available now on GitHub.
You can check out Milla’s video about it on her Instagram.
I’ll also put some links in the comments below - please try it out, critique it, fork it, contribute to it - and join our discord.
1
130
Apr 7
Amazing!
Apr 7
30 second explanation of the MemPalace by Milla Jovovich.
By day she’s filming action movies, walking Miu Miu fashion shows, and being a mom. By night she’s coding.
She’s the most creative, brilliant, and hilarious person I know. I’m honored to be working with her on this project… more to come.
156
Apr 6
有时候AI太不爱走“捷径”,什么都要从头手撸,其实挺消耗的,应该多花时间research
Apr 5

Addy Osmani(Google Chrome 工程负责人)开源了一套 Agent Skills,可能是目前最系统的 AI 编码代理技能库。
核心问题:AI 代理默认走捷径——跳规范、跳测试、跳安全审查。这套技能库把高级工程师的工程纪律编码成 19 个强制工作流,覆盖从创意到上线的完整生命周期:
定义阶段:idea-refine 用结构化的发散-收敛思维把模糊想法转化为具体提案,输出包含问题陈述、推荐方向、关键假设和 MVP 范围的一页纸文档。spec-driven-development 要求编码前先写规范,覆盖目标、命令、项目结构、代码风格、测试策略、边界条件六个区域,规范是活文档,决策变化时同步更新。
规划阶段:核心概念是垂直切片——不是先做完所有数据库再做 API 再做 UI,而是每个任务贯穿完整特性路径,DB API UI 一起交付。任务大小有硬指标:XS 1 文件、S 1-2 文件、M 3-5 文件、L 5-8 文件,超过 8 个文件必须拆分,没有例外。
构建阶段:增量实现循环——写代码 → 测试 → 验证 → 提交 → 下一块。每 100 行代码必须跑测试,每次增量后系统必须可构建且测试通过,用功能标志隐藏未完成的特性。上下文工程防止幻觉:定义五层上下文从持久到临时(规则文件 → 规范 → 源码 → 错误输出 → 对话历史),信息冲突时必须停下来,绝不猜测。前端工程明确反对"AI 默认美学"——禁止紫色靛青配色、过度渐变、全圆角这些一眼 AI 味的设计。
验证阶段:TDD 红绿重构循环,测试金字塔 80% 单元 / 15% 集成 / 5% E2E,引用 Google 的 Beyoncé 规则——"如果你喜欢它,就该给它写个测试"。通过 Chrome DevTools MCP 给代理装"眼睛"直接看浏览器,截图复现 → DOM 检查 → 诊断 → 修复 → 截图验证。调试有停止线规则:错误发生立即停止、保留证据、诊断根因、修复、写回归测试、端到端验证,六步必须依序完成。
审查阶段:五轴代码审查(正确性、可读性、架构、安全、性能),变更大小约束 100 行好、300 行可接受、~1000 行必须拆分。安全加固三层边界:总是做(参数化查询、HTTPS、密码哈希)、先问再做(新认证流、CORS、文件上传)、永不做(提交密钥、eval 用户数据、localStorage 存认证)。性能优化测量优先,无数据的优化等于猜测,Core Web Vitals 硬指标 LCP ≤ 2.5s、INP ≤ 200ms、CLS ≤ 0.1。
发布阶段:推荐 Trunk-based 开发,功能标志渐进发布 OFF → 团队启用 → Canary 5% → 25% → 50% → 100%,每个标志有 owner 和过期日期,完整发布后两周内清理。回滚阈值明确量化:错误率超基线 2 倍或 P95 延迟超 50% 立即回滚,不讨论。
最独到的设计:每个技能都有一张「反理性化表」——列出 AI 用来跳过步骤的常见借口("这个改动太小不需要测试"、"时间不够先跳过规范"),然后逐条反驳。这不是写给人看的,是写给 AI 看的,直接对抗大模型在推理中自我说服偷懒的倾向。
思想来源清晰可辨:Google《Software Engineering at Google》(Hyrum 定律、Beyoncé 规则、变更大小规范)、DORA 研究(Trunk-based 开发、Shift Left、小批量快速发布)、作者在 Chrome 团队的生产经验。
本质上,这是一套写给 AI 的工程手册。价值不在于告诉 AI 什么是好代码——大模型已经"知道"了——而在于强制它不走捷径,每个环节都做到位。
github.com/nicepkg/agent-ski…
192
Mar 26
很多AI圈子的朋友们都没有意识到,大家实际又把crypto有关的设施全部重做了一遍。
Mar 26

给大家写个小学水平也能理解TurboQuant的解读
Google 刚发布的 TurboQuant 论文有多猛? X 上1000多万阅读了, 给大家写个都能看懂的大白话解析介绍下, 着又是能让大模型成倍提速, 价格嗷嗷给打下来的技术创新.
首先要从KVCache说起, 也算是老生常谈了, KVCache 是啥? 简单来讲, 大模型是一个个字往外蹦的, 而每蹦一个字都需要把这个字跟之前已经输出的字都计算一下, 类似于人类的边说话边回顾.
但是把刚开始说话的内容全算一遍显然不靠谱, 于是有了缓存, 直接把之前的计算结果保存下来, 每次只要跟这个缓存的结果去计算就行了,这个缓存里面存的就是每个字每次的特征数据
聪明的你一定能想到了, 那话说的越多, 这个缓存就会变得越大. 为了解决这个问题,业界卷出了【滑动窗口注意力】和【线性注意力】
这俩是啥呢? 我们可以把 KV Cache 想象成一个存放数据的【3D立方体】
立方体的【长】(上下文长度): 随着对话变长而不断变长。【滑动窗口注意力】就是限制了它的长,只保留最近固定长度的记忆,扔掉太老的,有效控制了体积。
立方体的【高】(状态大小): 【线性注意力】出手了,它通过数学魔法,把所有历史记录压缩成一个固定大小的隐状态。也就是说,无论说多少话,立方体的高永远被卡死了。
还剩下一个KVCache的【宽】对吧? 没错, 这个就是里面数据的精度(可以简单理解为小数点后面保留几位小数), 大家都知道模型参数是有精度的, 自然KVCache也有精度, 答案呼之欲出了——压缩KVCache的数据精度!
但是问题来了, 压到特别小 3bit 特别难, 而这就是 Google 这篇论文的核心了, 它使用了新的算法 (PolarQuant QJL) 成功把 KV Cache 无损压缩到只有 3-bit! 要知道,今天很多普通大模型的KVCache还在用 16-bit(FP16/BF16)跑!
那为啥 KVCache 小了大模型会提速? 是因为计算的数据少了吗?
并不是, 因为现在显卡的算子也是有最小精度要求的, 比如 H100, 硬件底层的 Tensor Core 原生也只能算到 8-bit, 再小的精度还要反量化扩充到8bit才能计算.
提速的奇迹,其实发生在数据的读写上!
大模型数据和KVCache都存储到显存中, 而GPU计算这些数据要加载到GPU的SRAM中, 这个过程十分受限于显存带宽(我已经给大家科普这个观点不下100次了...).
所以,现在把 KV Cache 的精度从 16-bit 砍到 3-bit,直接就把需要读取和搬运的数据量缩小到了 1/4 到 1/5 !在显卡带宽不变、算力严重过剩的情况下,省下了海量的“搬砖时间”,速度自然就成倍飙升了!
目前我十分看好TurboQuant, 如果这个搭配线性注意力或者滑动窗口, 未来模型的推理速度翻倍完全没问题了!
#TurboQuant #PolarQuant #Google #线性注意力 #滑动窗口注意力

1
3
322
Mar 23
整个圈子直男太多了,做的所谓Agent都是牛马玩意儿,看似有用实则无用,都是工蜂思维,到最后没有一个女人爱用这些破东西,难怪现在AI干不好消费市场。市场需要更多的🏳️🌈同学来搞点事,不然太Boring
1
197
Mar 23
人人都希望AI给你带来生产力提升,所以你开始Harness,加大控制能力,更多“精益”的流程……
然而你回看自己的生活,除了不像个人,没有什么改善
2
332