
ELLIS PhD Student @ ETH / Google
Joined July 2022
- Tweets 24
- Following 152
- Followers 73
- Likes 66
7 Photos and videos




Pinned Tweet

May 20
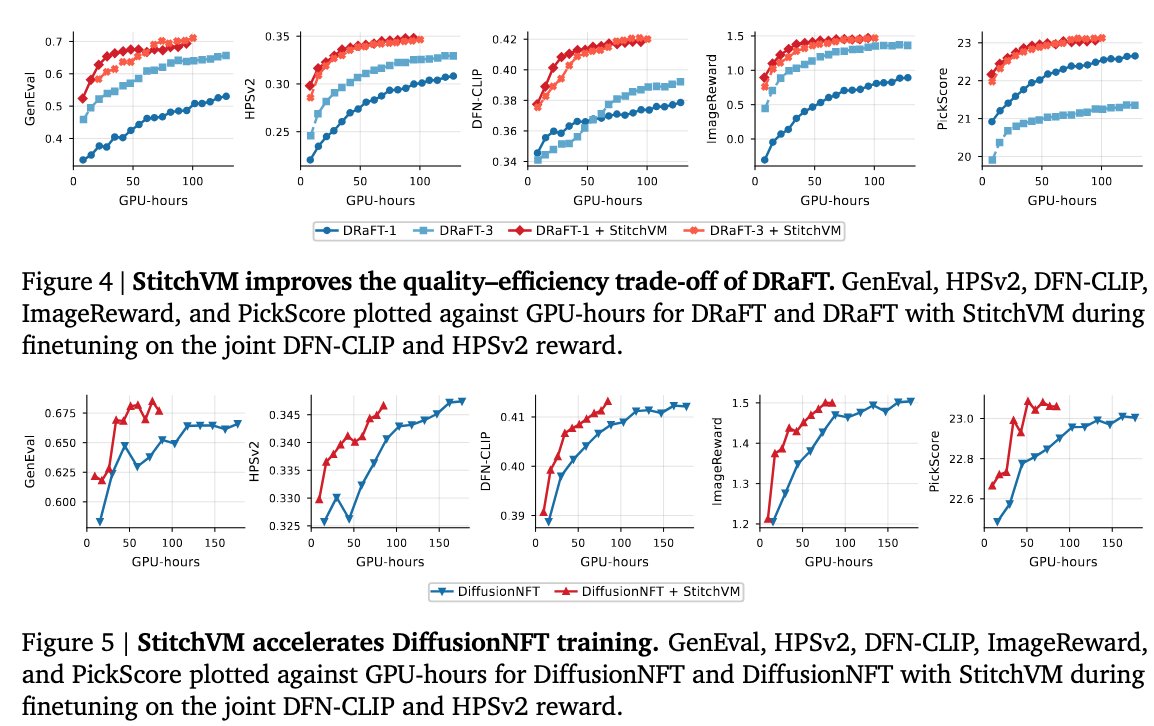
Our recent finding on Diffusion Alignment: a reward model in pixel space can be easily transferred to score noisy diffusion latents directly — at small finetuning cost, via stitching.
This makes Faster & Better for both Training & Inference Alignment.
Meet StitchVM👇
1/
3
6
29
6,663
Hyojun Go retweeted

🚀 Excited to share my @GoogleDeepMind student researcher project: Dual-Rate Diffusion✨
⚡ A simple construction that speeds up both regular diffusion and distilled models by interleaving a heavy context encoder with a light conditional denoiser.
🧵👇

6
29
192
17,184
Hyojun Go retweeted
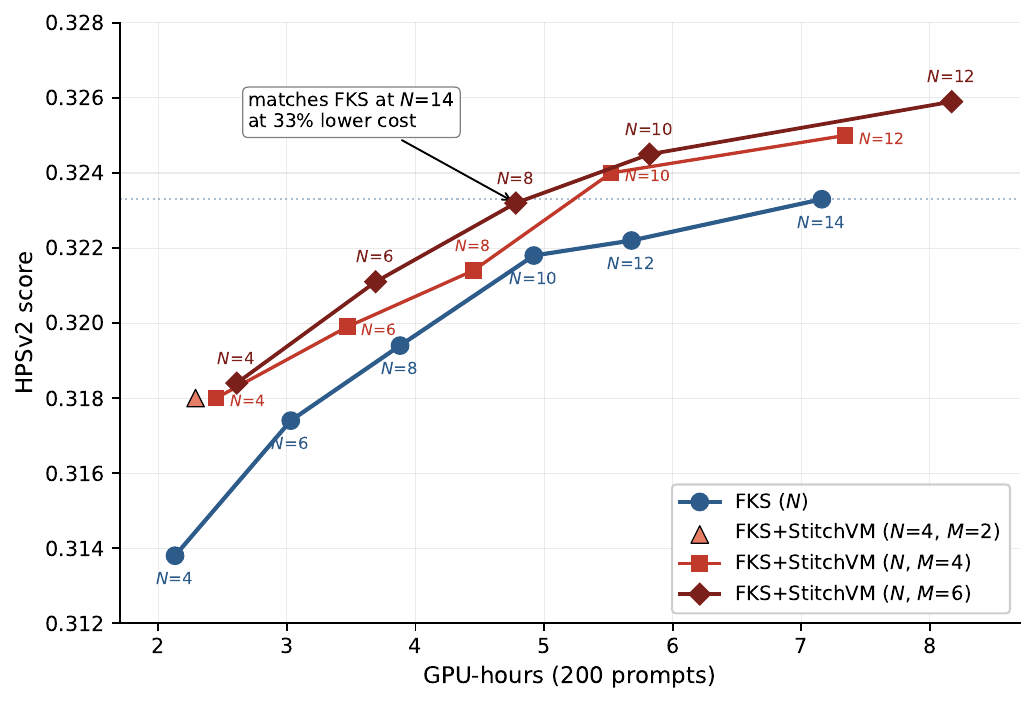
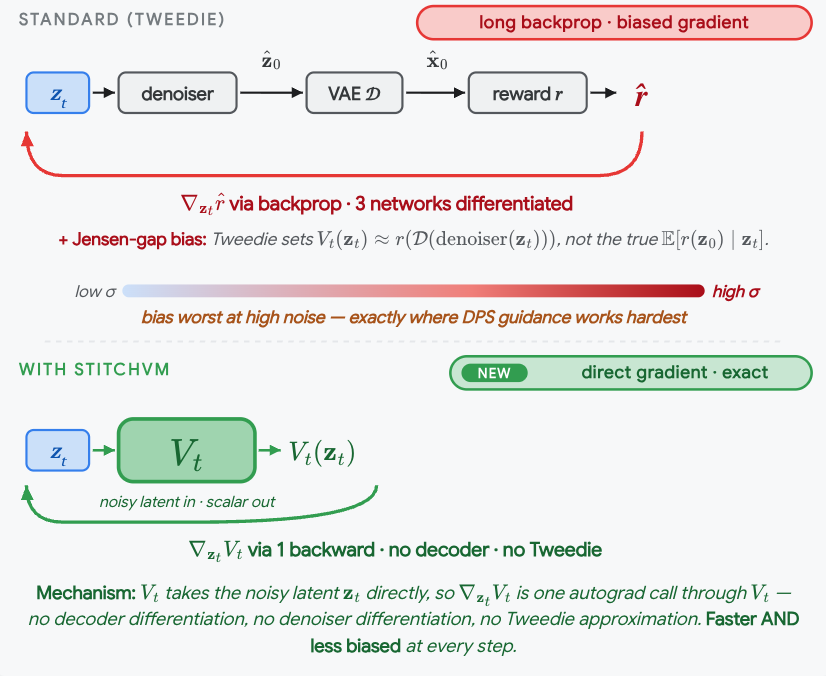
For alignment you need V, but is hard to compute. Most methods try to approximate with
1) Tweedie, which is biased
2) MC roll-outs, which is slow with high var.
Training V was often neglected since it's hard.
We beg to differ. StitchVM enables this! Led by @gohyojun3
👇
May 20

Our recent finding on Diffusion Alignment: a reward model in pixel space can be easily transferred to score noisy diffusion latents directly — at small finetuning cost, via stitching.
This makes Faster & Better for both Training & Inference Alignment.
Meet StitchVM👇
1/
7
27
5,068
May 20
Our recent finding on Diffusion Alignment: a reward model in pixel space can be easily transferred to score noisy diffusion latents directly — at small finetuning cost, via stitching.
This makes Faster & Better for both Training & Inference Alignment.
Meet StitchVM👇
1/
3
6
29
6,663
May 20
Result 4️⃣ — Training-time alignment with DRaFT & DiffusionNFT
No need for full rollouts. Just stop denoising at an intermediate step and use StitchVM's inference as the reward signal.
Now we have much faster convergence
7/
1
1
363
May 20
For more, check out our work 👇
@hyungjin_chung , @prunetruong , Goutam Bhat, @ZhaochongAn , @zixiangzhao_ , @DNarnhofer , @fedassa , @SergeBelongie , Konrad Schindler
paper: arxiv.org/abs/2605.19804
Page: gohyojun15.github.io/StitchV…
3
304
Hyojun Go retweeted

18 Dec 2025
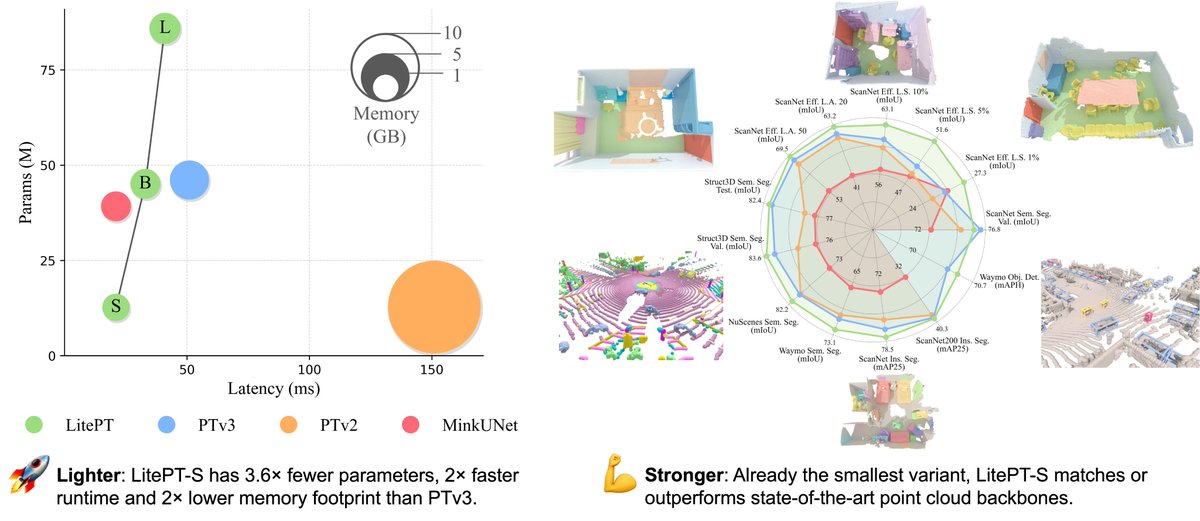
Want a lighter yet stronger Point Transformer? Meet LitePT ✨
LitePT is a lightweight, high-performance 3D point cloud architecture for a wide range of point cloud processing tasks. Our smallest variant LitePT-S, features 3.6× fewer parameters, 2× faster runtime and 2× lower memory footprint than PTv3, while already matching or outperforming it across a range of benchmarks.
💻Code: github.com/prs-eth/LitePT
🌐Project page: litept.github.io/
📰Paper: arxiv.org/abs/2512.13689
with Damien Robert, @jianyuan_wang , Sunghwan Hong, Jan Dirk Wegner, Christian Rupprecht, and Konrad Schindler
3
26
126
11,707
Hyojun Go retweeted

17 Oct 2025
Combining video diffusion and 3D feedforward models by simply stiching them together in latent space - very cool idea! Make sure to check out this novel work from my collagues at Google and ETH!
16 Oct 2025

🎺Meet VIST3A — Text-to-3D by Stitching a Multi-view Reconstruction Network to a Video Generator.
➡️ Paper: arxiv.org/abs/2510.13454
➡️ Website: gohyojun15.github.io/VIST3A/
Collaboration between ETH & Google with Hyojun Go, @DNarnhofer, Goutam Bhat, @fedassa, and Konrad Schindler.
7
64
8,355
Hyojun Go retweeted

16 Oct 2025
Want to leverage the power of SOTA 3D models like VGGT & Video LDMs for 3D generation? Now you can! 🚀
Introducing VIST3A — we stitch pretrained video generators to 3D foundation models and align them via reward finetuning.
📄 arxiv.org/abs/2510.13454
🌐 gohyojun15.github.io/VIST3A
3
14
8,746
Hyojun Go retweeted

16 Oct 2025
🎺Meet VIST3A — Text-to-3D by Stitching a Multi-view Reconstruction Network to a Video Generator.
➡️ Paper: arxiv.org/abs/2510.13454
➡️ Website: gohyojun15.github.io/VIST3A/
Collaboration between ETH & Google with Hyojun Go, @DNarnhofer, Goutam Bhat, @fedassa, and Konrad Schindler.
16 Oct 2025

Want to leverage the power of SOTA 3D models like VGGT & Video LDMs for 3D generation? Now you can! 🚀
Introducing VIST3A — we stitch pretrained video generators to 3D foundation models and align them via reward finetuning.
📄 arxiv.org/abs/2510.13454
🌐 gohyojun15.github.io/VIST3A
2
11
88
16,957
Hyojun Go retweeted

11 Sep 2025
Even the SOTA VideoLLMs see videos in 1 fps, and you CANNOT perceive fine-grained motion 💃 with this frequency 🥲
📣 Presenting Video Parallel Scaling (VPS), an inference-time strategy that lets VideoLLMs see more frames by scaling compute in the parallel-axis 🤩

1
11
38
2,696
Hyojun Go retweeted
26 Jun 2025
Excited to share that 3 papers are accepted to #ICCV2025 at EverEx 🎉
📌 SteerX: arxiv.org/abs/2503.12024
📌 VideoRFSplat: arxiv.org/abs/2503.15855
📌 CapeLLM: arxiv.org/abs/2411.06869
See you in Hawaii 🌴
👇 link to some threads
1
7
83
5,295
Hyojun Go retweeted
22 Mar 2025
🚨Introducing VideoRFSplat📽️, a feed-forward text-to-3DGS generative model with high-quality scene-level results without post-optimization (e.g. SDS)
Led by collaborators at EverEx AI - @gohyojun3, @bypark___, @namhyelin99, Byung-Hoon
gohyojun15.github.io/VideoRF…
A 🧵 👇
1/n
2
8
45
4,269
Hyojun Go retweeted

18 Mar 2025
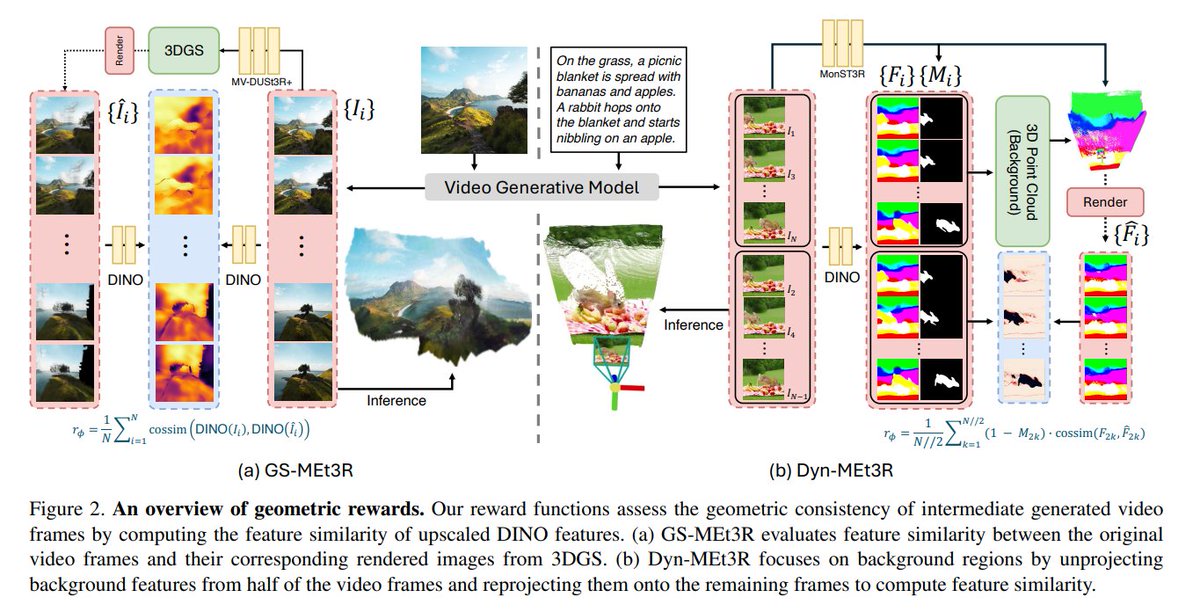
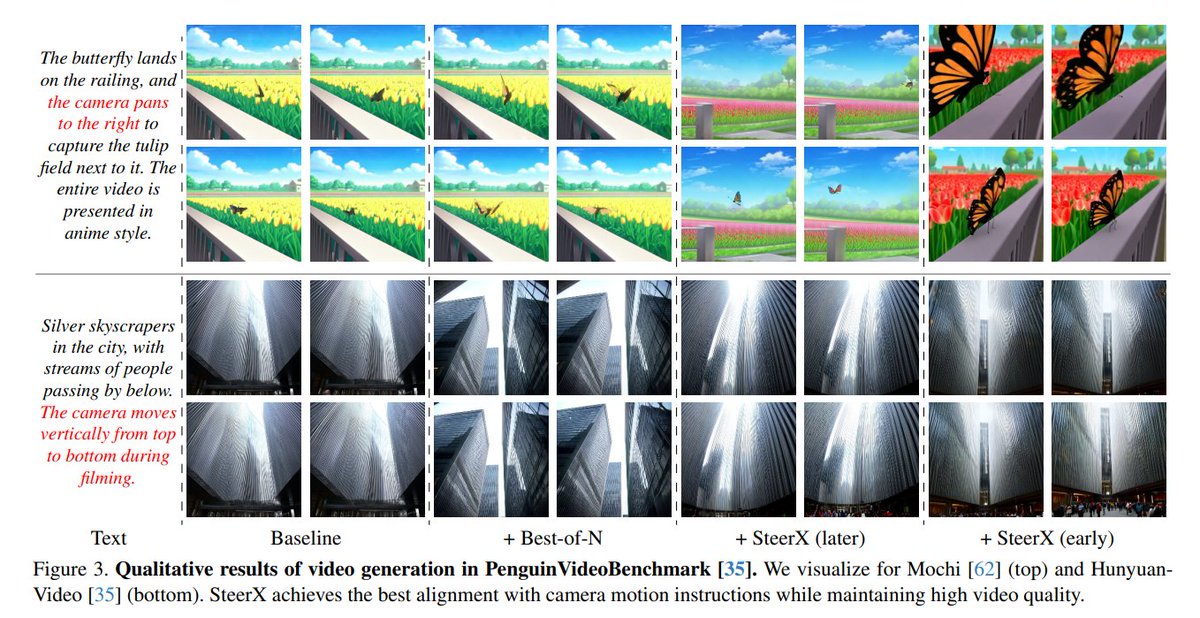
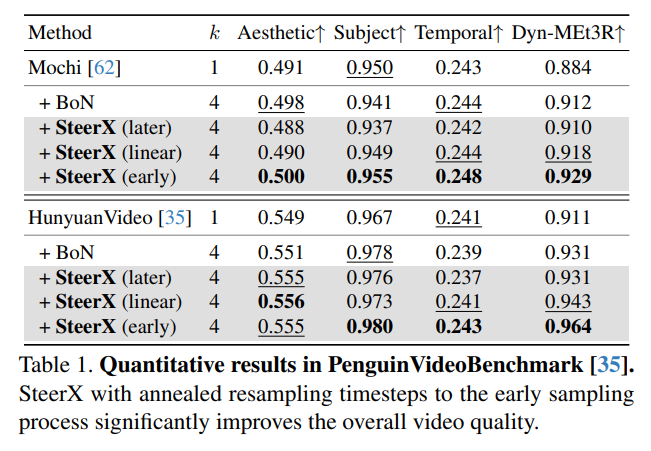
SteerX: Creating Any Camera-Free 3D and 4D Scenes with Geometric Steering
@bypark___, @gohyojun3, @namhyelin99, Byung-Hoon Kim, @hyungjin_chung, Changick Kim
tl;dr: MV-DUSt3R and MonST3R->geometric reward functions->geometric consistency
arxiv.org/abs/2503.12024

9
49
2,789
Hyojun Go retweeted
18 Mar 2025
3D consistent videos are hard to generate 🙁
What if we could steer them to be consistent during generation?
Introducing SteerX🛞, a plug-and-play sampling method that works with *any* video diffusion to make videos physically plausible🤩
w/ @bypark___ @gohyojun3 @namhyelin99

2
18
104
7,334
Hyojun Go retweeted

26 Nov 2024
SplatFlow: Multi-View Rectified Flow Model for 3D Gaussian Splatting Synthesis
TL;DR: SplatFlow is a unified framework that combines a latent-space multi-view generator and a Gaussian Splatting Decoder to enable efficient 3D generation, editing, and inpainting directly from text prompts.
Abstract (excerpt):
SplatFlow comprises two main components: a multi-view rectified flow (RF) model and a Gaussian Splatting Decoder (GSDecoder).
The multi-view RF model operates in latent space, generating multi-view images, depths, and camera poses simultaneously, conditioned on text prompts, thus addressing challenges like diverse scene scales and complex camera trajectories in real-world settings.
Then, the GSDecoder efficiently translates these latent outputs into 3DGS representations through a feed-forward 3DGS method. Leveraging training-free inversion and inpainting techniques, SplatFlow enables seamless 3DGS editing and supports a broad range of 3D tasks-including object editing, novel view synthesis, and camera pose estimation-within a unified framework without requiring additional complex pipelines.
We validate SplatFlow's capabilities on the MVImgNet and DL3DV-7K datasets, demonstrating its versatility and effectiveness in various 3D generation, editing, and inpainting-based tasks.
1
7
77
4,956