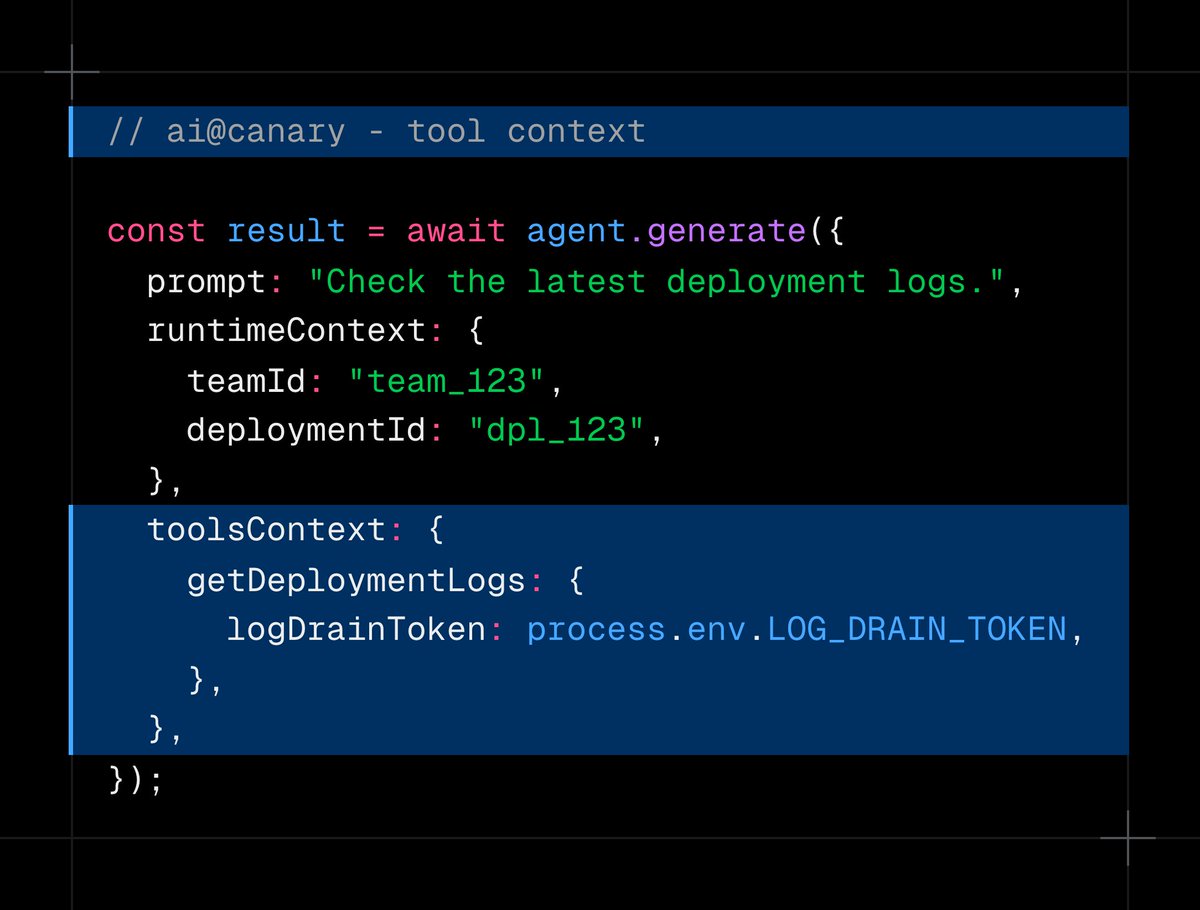
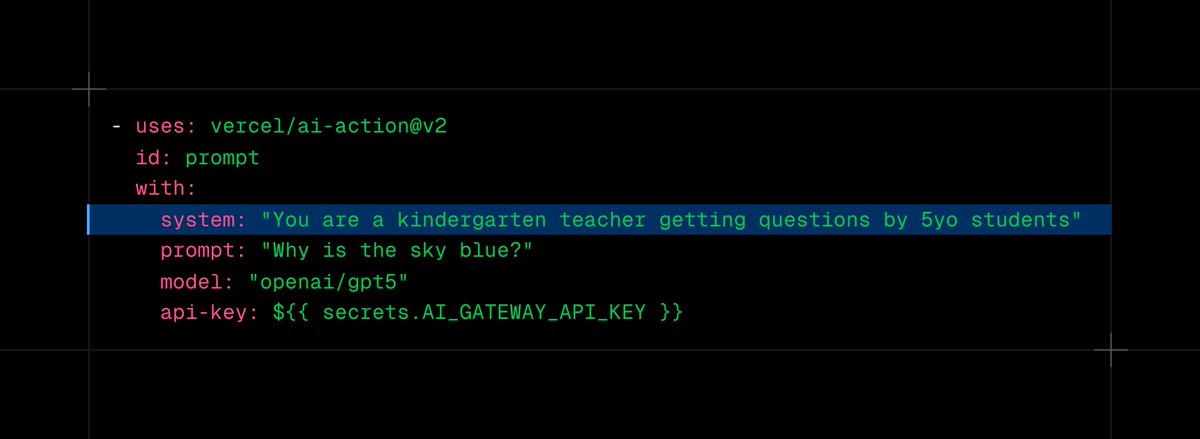
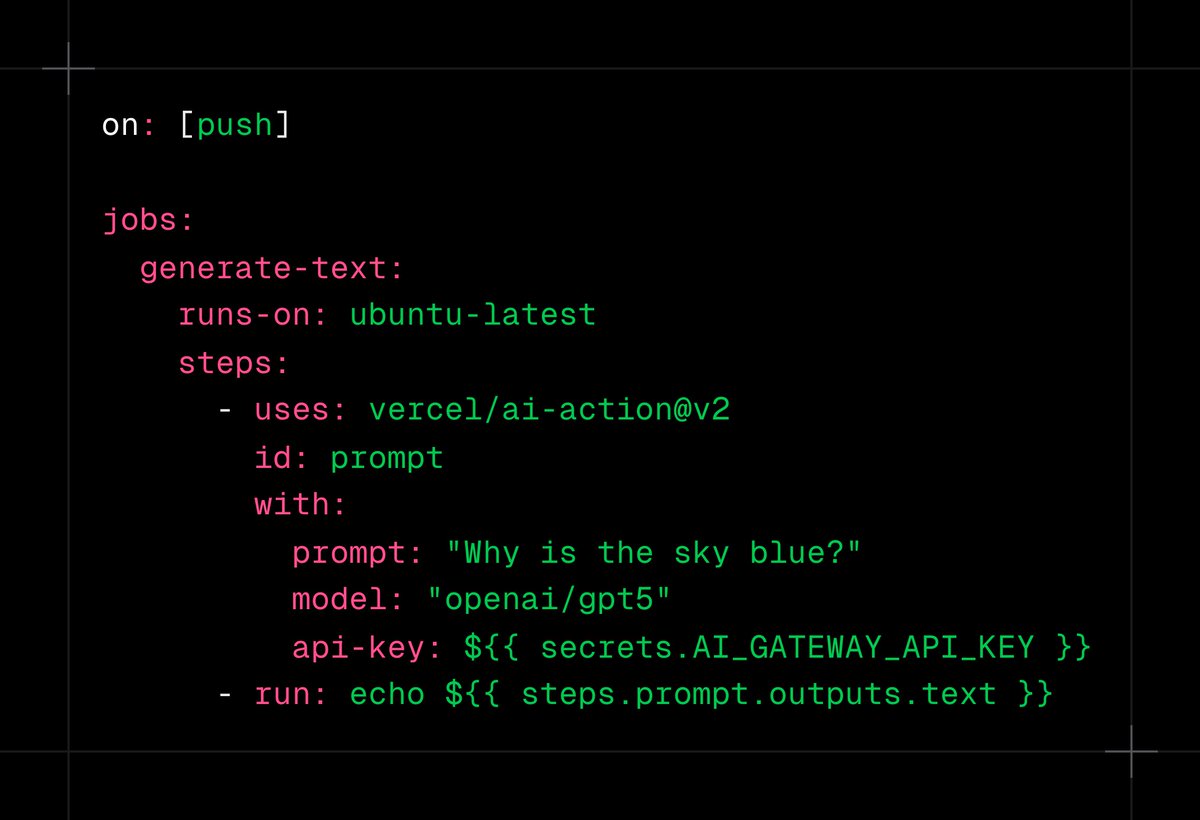





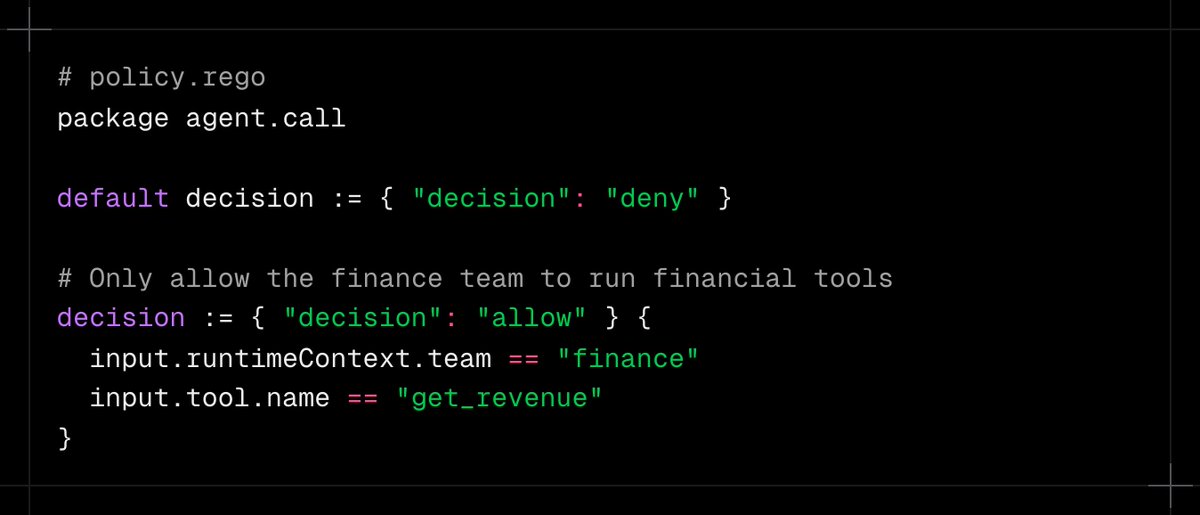
ALT Code snippet outlines a policy for agent actions, defaulting to deny, with specific rules for allowing finance tool access: # policy.rego package agent.call default decision := { "decision": "deny" } # Only allow the finance team to run financial tools decision := { "decision": "allow" } { input.runtimeContext.team == "finance" input.tool.name == "get_revenue" }



ALT // AI SDK: Claude Fable 5 import { anthropic } from '@ai-sdk/anthropic'; import { ToolLoopAgent } from 'ai'; const agent = new ToolLoopAgent({ model: anthropic('claude-fable-5'), });




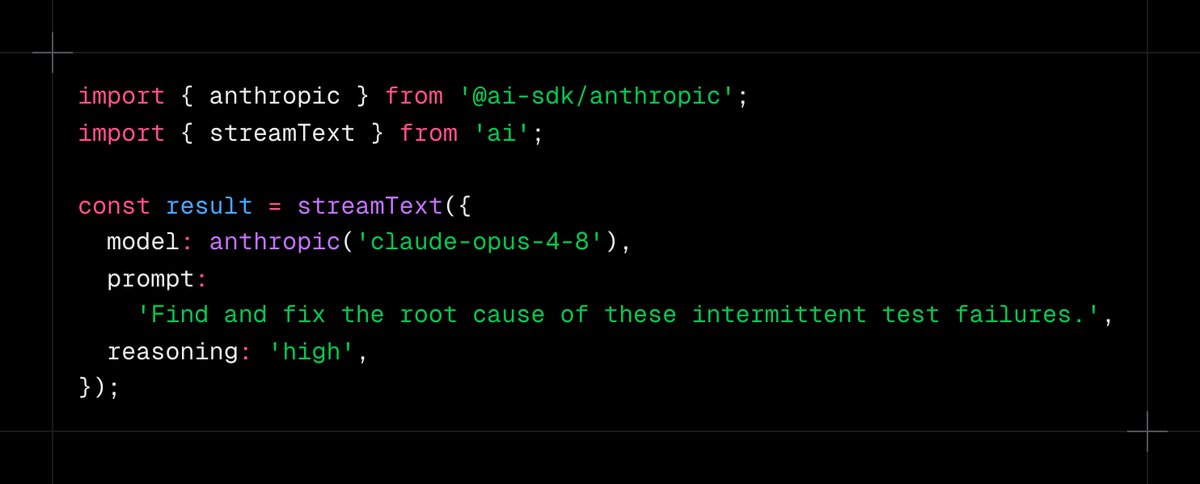
ALT import { anthropic } from '@ai-sdk/anthropic'; import { streamText } from 'ai'; const result = streamText({ model: anthropic('claude-opus-4-8'), prompt: 'Find and fix the root cause of these intermittent test failures.', reasoning: 'high', });
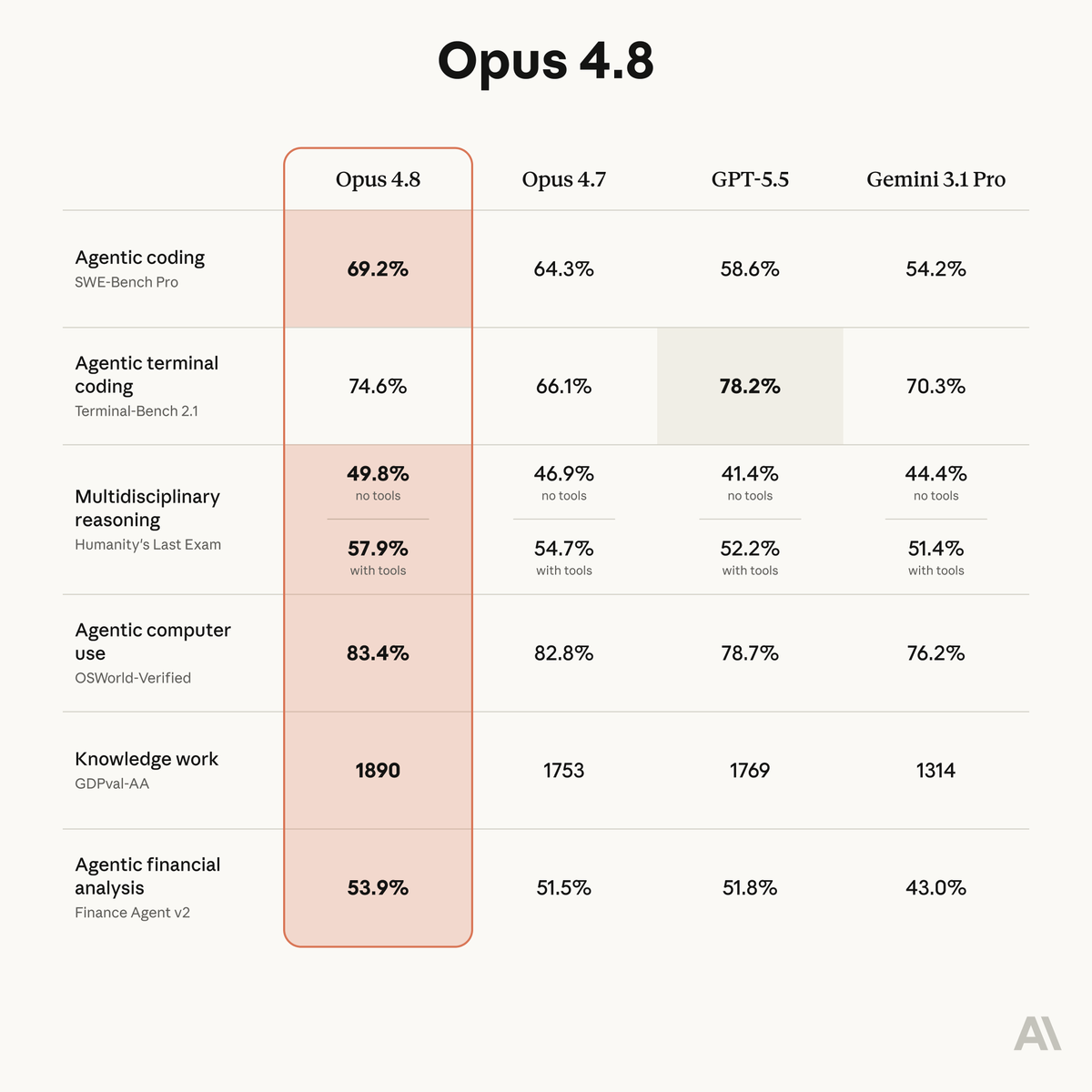
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
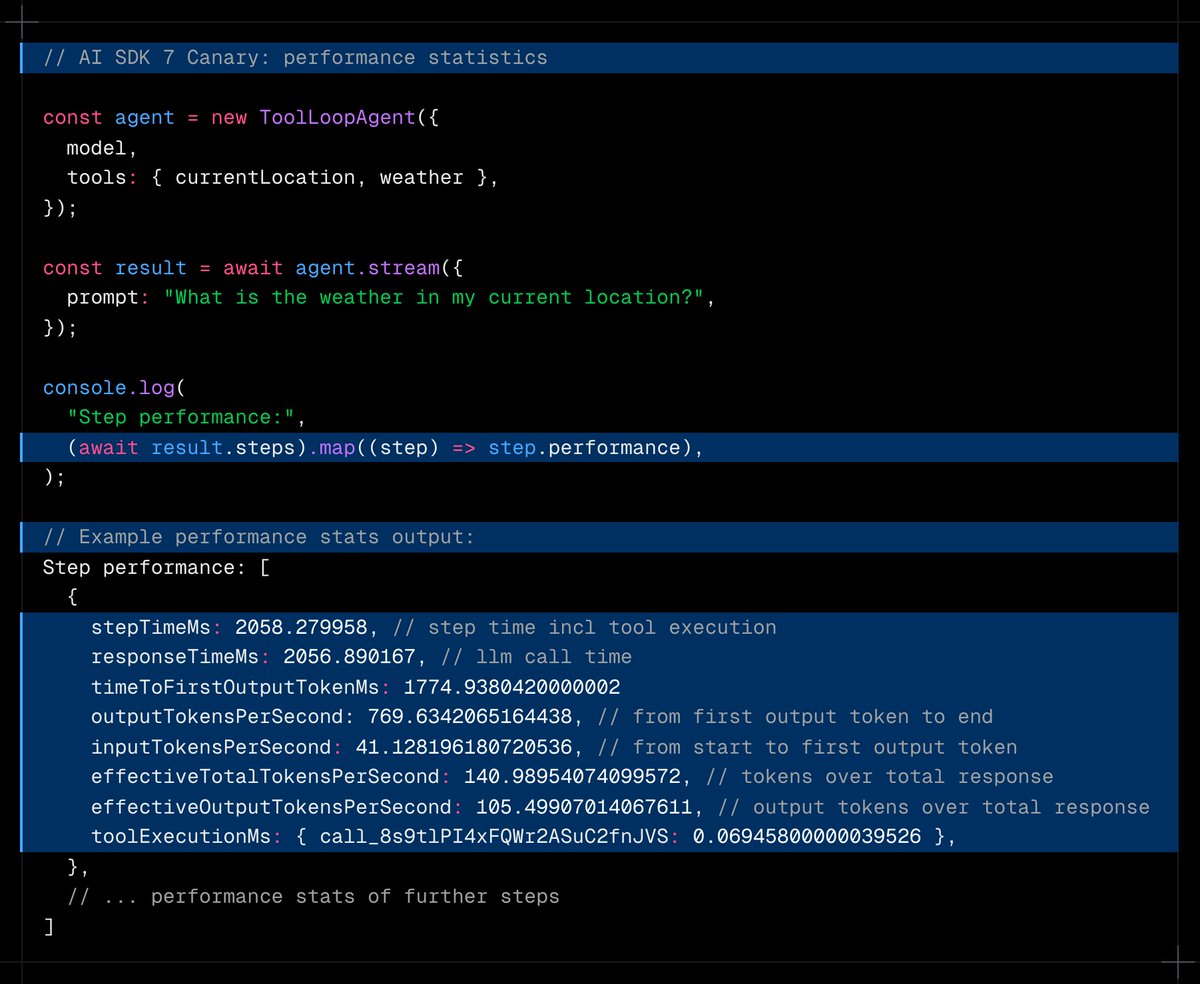

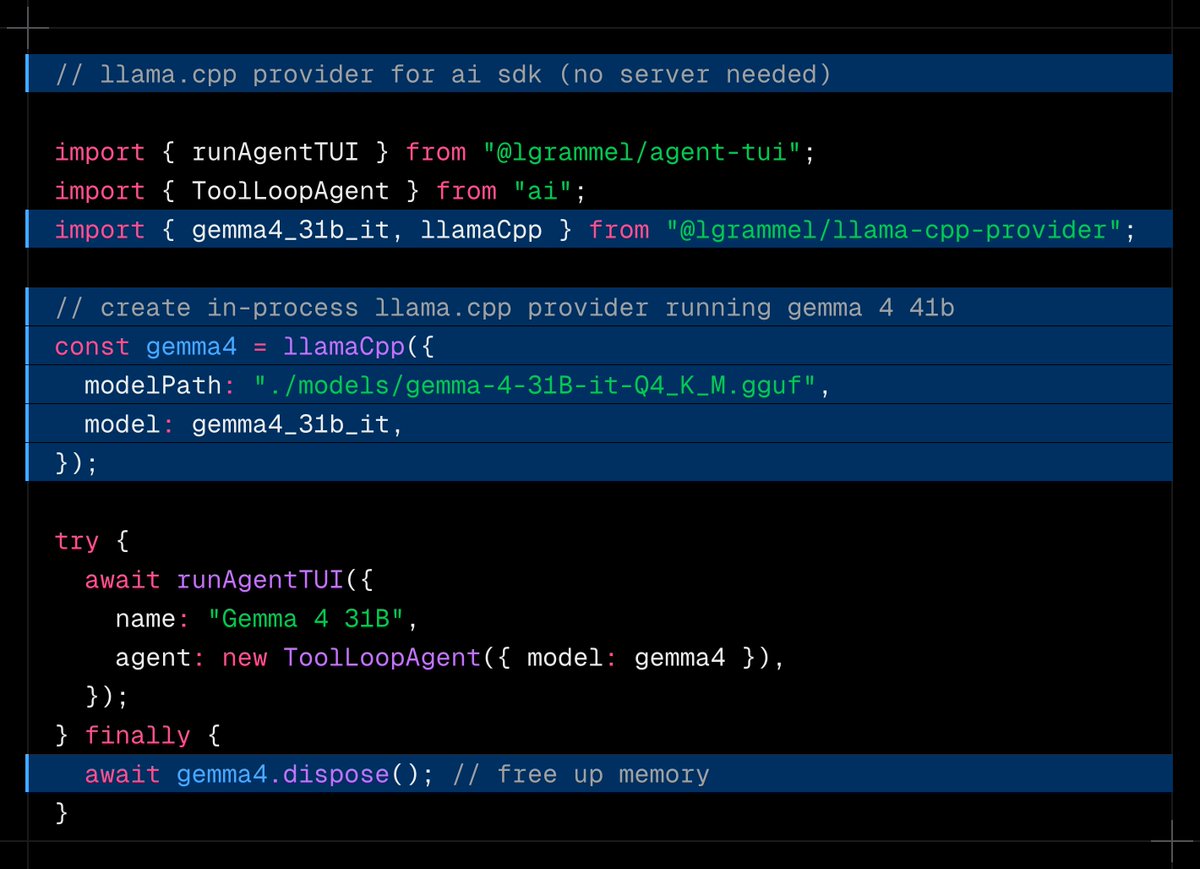
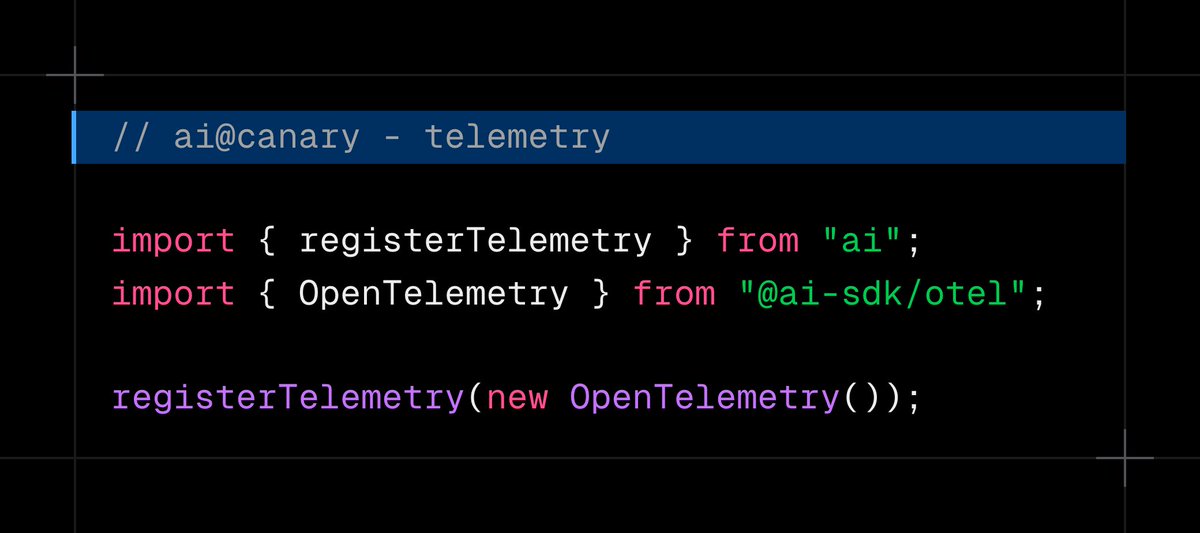
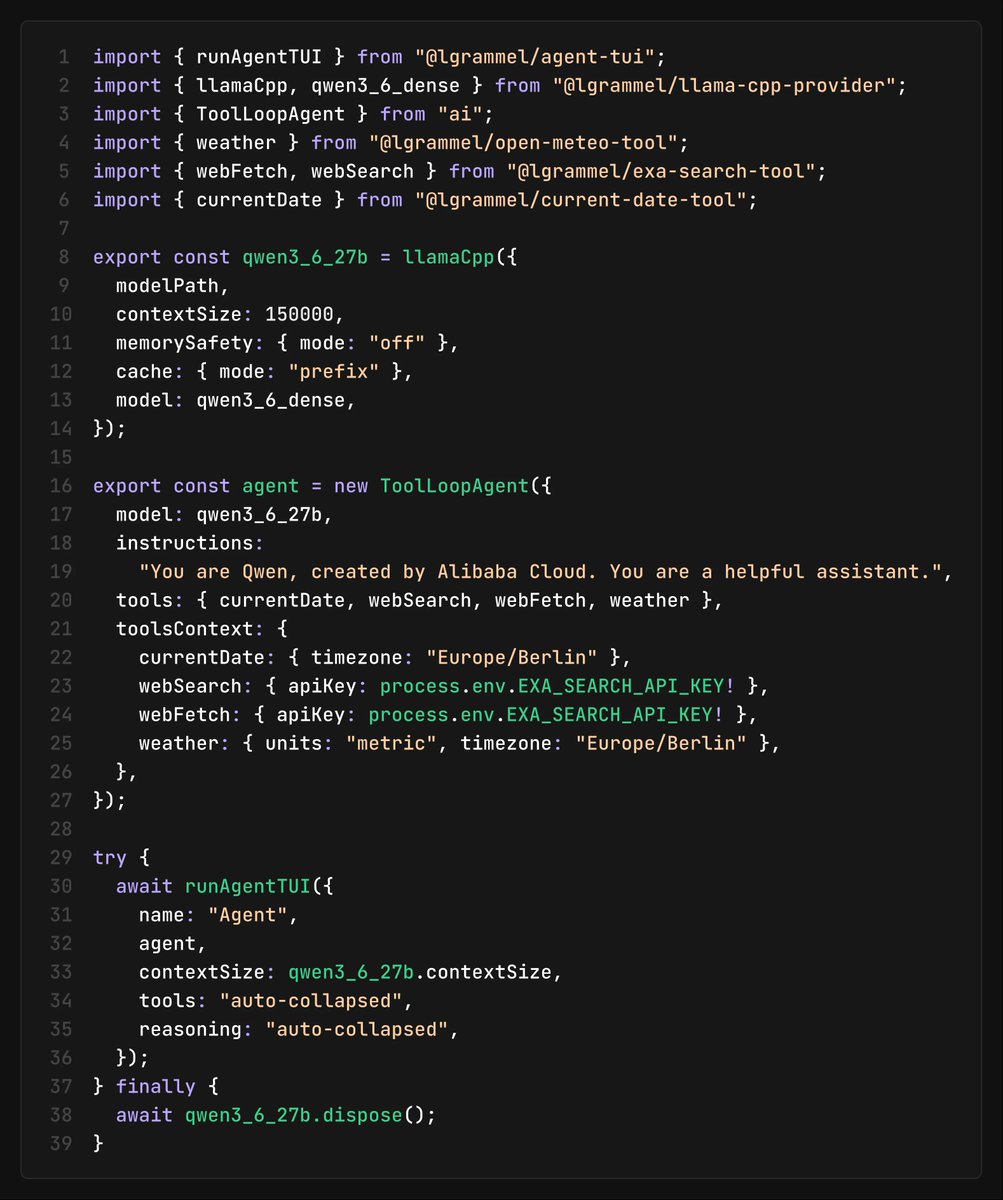




ALT import { google } from '@ai-sdk/google'; import { streamText, stepCountIs } from 'ai'; import { weatherTool } from './tools/weather-tool'; const result = await streamText({ model: google.interactions('gemini-3.1-pro-preview'), tools: { getWeather: weatherTool }, stopWhen: stepCountIs(5), prompt: 'What is the weather in San Francisco right now?', });