
Joined August 2016
- Tweets 1,800
- Following 482
- Followers 2,805
- Likes 1,427
250 Photos and videos
















May 21
Imagine dogpiling on one of most influential researchers on physics:ml intersection and thinking you made such a great point. Don't even want to QT disgusting responses to some sensible points about AI use policy on arXiv. People really have gone insane.
May 16

Occasional errors and oversights are part of science. If we lost our driver’s license for a year every time we exceeded the speed limit by 10 km/h, daily life would become unworkable. Many countries instead use point systems, where trust can be rebuilt through good behavior.
3
585
Anton Tsitsulin retweeted

AI has now solved a major open problem -- one of the best known Erdos problems called the unit distance problem, one of Erdos's favourite questions and one that many mathematicians had tried.
openai.com/index/model-dispr…
75
614
3,561
1,489,707
Anton Tsitsulin retweeted

May 18
How to land a job at a frontier lab
vladfeinberg.com/2026/05/10/…

The vibes in SF feel pretty frenetic right now. The divide in outcomes is the worst I've ever seen.
Over the last 5yrs, a group of ~10k people - employees at Anthropic, OpenAI, xAI, Nvidia, Meta TBD, founders - have hit retirement wealth of well above $20M (back of the envelope AI estimation).
Everyone outside that group feels like they can work their well-paying (but <$500k) job for their whole life and never get there.
Worse yet, layoffs are in full swing. Many software engineers feel like their life's skill is no longer useful. The day to day role of most jobs has changed overnight with AI.
As a result,
1. The corporate ladder looks like the wrong building to climb.
Everyone's trying to align with a new set of career "paths": should I be a founder? Is it too late to join Anthropic / OpenAI? should I get into AI? what company stock will 10x next? People are demanding higher salaries and switching jobs more and more.
2. There’s a deep malaise about work (and its future).
Why even work at all for “peanuts”? Will my job even exist in a few years? Many feel helpless. You hear the “permanent underclass” conversation a lot, esp from young people. It's hard to focus on doing good work when you think "man, if I joined Anthropic 2yrs ago, I could retire"
3. The mid to late middle managers feel paralyzed.
Many have families and don't feel like they have the energy or network to just "start a company". They don't particularly have any AI skills. They see the writing on the wall: middle management is being hollowed out in many companies.
4. The rich aren’t particularly happy either.
No one is shedding tears for them (and rightfully so). But those who have "made it" experience a profound lack of purpose too. Some have gone from <$150k to >$50M in a few years with no ramp. It flips your life plans upside down. For some, comparison is the thief of joy. For some, they escape to NYC to "live life". For others still, they start companies "just cuz", often to win status points. They never imagined that by age 30, they'd be set. I once asked a post-economic founder friend why they didn't just sell the co and they said "and do what? right now, everyone wants to talk to me. if i sell, I will only have money."
I understand that many reading this scoff at the champagne problems of the valley. Society is warped in this tech bubble. What is often well-off anywhere else in the world is bang average here.
Unlike many other places, tenure, intelligence and hard work can be loosely correlated with outcomes in the Bay. Living through a societally transformative gold rush in that environment can be paralyzing. "Am I in the right place? Should I move? Is there time still left? Am I gonna make it?" It psychologically torments many who have moved here in search of "success".
Ironically, a frequent side effect of this torment is to spin up the very products making everyone rich in hopes that you too can vibecode your path to economic enlightenment.
53
161
2,984
1,306,911
Anton Tsitsulin retweeted

May 11
Happy to share new proofs of simple constructions of general Knuth's recent cycle conjecture for even case based on a new Gemini system for long proofs; one with 40 pages & one with 70 pages here: github.com/dpwoodru/knuthCyc…
Excited about the system for long proofs. See Comments
2
4
30
3,549
May 11
This is why we have 4 frontier labs btw
May 9

A new study shows that individuals with similar levels of autistic traits are naturally drawn to one another. Brain scans reveal they use alternative, highly effective neural strategies to connect, challenging traditional deficit-based models of autism. dlvr.it/TSSN7t
3
572
Anton Tsitsulin retweeted

May 8
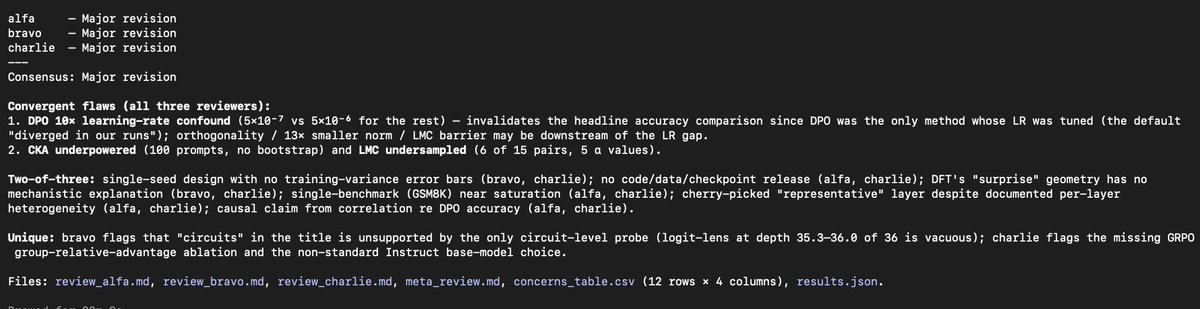
Tired of getting rejects and reading reviewer comments that clearly missed the point of your paper?
I built an peer review skill for Claude Code that actually gives you useful feedback before you submit.
👇
5
9
41
1,463
May 7
Correspondence chess community is the definition of long-termist
1
249
May 1
this is good actually

This is really bad. As an area chair, I usually accept papers with a reject if the reject review is not valid. I never reject a paper with all accepts.
2
637
Apr 28
Unstoppable force of AI meets an immovable object
Apr 28

The bottom line: they are short compute and Codex is on fire...
207
Apr 24
5.5 pro is a great but weirdly shaped model. Feels like a different interaction mode than previous pro generations somehow
181
Anton Tsitsulin retweeted

Apr 23
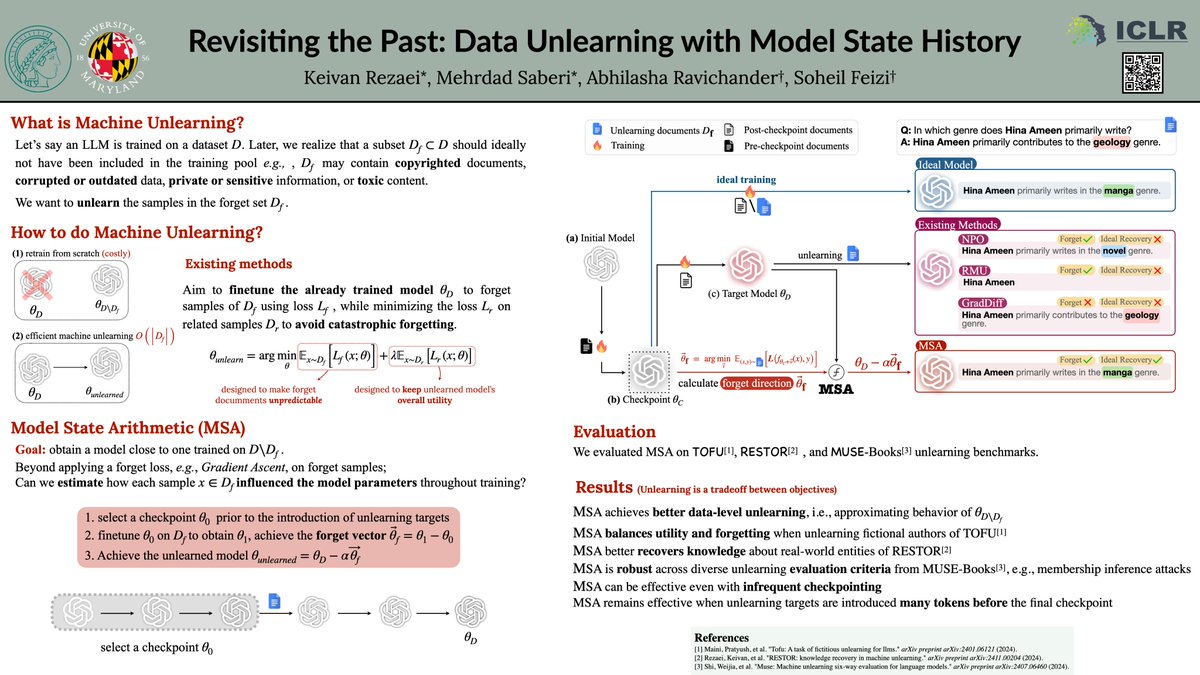
🔎 If you are interested in machine unlearning, check out our poster tomorrow at #ICLR2026.
(Pavilion 4, P4-#3916 | Apr 24, 10:30 AM – 1:00 PM)
We explore a new direction for machine unlearning, leveraging model checkpoints!
📜 Paper: arxiv.org/abs/2506.20941
1
5
30
7,106
Apr 13
okay this is not very funny anymore, pretty sure I'm just reading a bunch of poor LLM-generated "theory" in a bunch of ICML papers
7
1
87
12,845
Apr 13
like, something that would come out as a "generate some theory for me plz" and attaching your half-baked manuscript
1
13
1,803
Apr 14
90% sure this rebuttal discussion on a paper I have is just ChatGPT arguing with another ChatGPT
1
16
1,715
Anton Tsitsulin retweeted

Apr 13
The growing KV-cache of attention is the key component for the long-context understanding of LLMs, but what holds back long-term memory modules (e.g., Titans)? What if we could have the compression power of Titans but with a growing memory similar to Transformers?
Memory Caching: A class of architectures that compress the context into a slow growing memory (not as fast as Transformers, but not as static as RNNs), resulting in recurrent neural networks with non-fixed-sized memory (hidden states). Building on this formulation, we present Sparse Selective Caching, an architecture with growing effective memory (similar to attention) but with almost constant inference cost per token (similar to RNNs).

25
167
1,003
109,376
Apr 10
Muonbros stay winning
Apr 10

The preconditions have been accepted.
3
448
Anton Tsitsulin retweeted

Apr 8
Lots of love for Gemma 4! Team just told me it’s already had 10M downloads since last week’s launch. Gemma models have now been downloaded 500M times! Excited to see what you all are creating 👀
252
297
5,872
377,581
Apr 8
Congrats metabros on an insane capability jump!

Meta is back! Muse Spark scores 52 on the Artificial Analysis Intelligence Index, behind only Gemini 3.1 Pro, GPT-5.4, and Claude Opus 4.6. Muse Spark is the first new release since Llama 4 in April 2025 and also Meta's first release that is not open weights
Muse Spark is a new model from @Meta evaluated on Artificial Analysis. We were given early access by Meta to independently benchmark the model. It is the first frontier-class model from Meta since Llama 4 Maverick was released in April 2025, and notably the first @AIatMeta model that is not being released as open weights. The release follows Meta's reorganization of its AI efforts under Meta Superintelligence Labs, and signals that Meta is re-entering the frontier race after roughly a year of relative quiet.
For context, Llama 4 Maverick and Scout scored 18 and 13 respectively on the Artificial Analysis Intelligence Index as non-reasoning models at the time of their release, while Muse Spark scores 52. Muse Spark essentially closes the gap between to the frontier in a single release.
The model is not open source and is not yet accessible via an API but Meta has shared they expect this to come soon. Meta is also integrating Muse Spark into their first party products including their Meta AI chat product, Facebook, Instagram and Threads.
Key takeaways from our benchmarks:
➤ Muse Spark scores 52 on the Artificial Analysis Intelligence Index, placing it within the top 5 models we have benchmarked. It sits ahead of Claude Sonnet 4.6, GLM-5.1, MiniMax-M2.7, Grok 4.20 and behind Gemini 3.1 Pro Preview, GPT-5.4 and Claude Opus 4.6
➤ Muse Spark is notably token efficient for its intelligence level. It used 58M output tokens to run the Intelligence Index, comparable to Gemini 3.1 Pro Preview (57M) and notably lower than Claude Opus 4.6 (Adaptive Reasoning, max effort, 157M), GPT-5.4 (xhigh, 120M) and GLM-5 (110M)
➤ Muse Spark is the second-most capable vision model we have benchmarked. It scores 80.5% on MMMU-Pro, behind only Gemini 3.1 Pro Preview (82.4%)
➤ Muse Spark performs strongly on reasoning and instruction-following evaluations. It scores 39.9% on HLE, trailing only Gemini 3.1 Pro Preview (44.7%) and GPT-5.4 (xhigh, 41.6%). The model also achieved 5th highest in CritPT with a score of 11%, an eval that is focused on difficult physics research questions. This is substantially above above Gemini 3 Flash (9%) and Claude 4.6 Sonnet (3%)
➤ Agentic performance does not stand out. On GDPval-AA, our evalaution focused on real world work tasks, Muse Spark scores 1427, behind both Claude Sonnet 4.6 at 1648 and GPT-5.4 at 1676, but ahead of Gemini 3.1 Pro Preview at 1320. On On TerminalBench Hard, Muse Spark trails Claude Sonnet 4.6, GPT-5.4, and Gemini 3.1 Pro. Muse Spark joins others in achieving a high τ²-Bench Telecom score of 92%
Key model details:
➤ Modalities: Multimodal including text and vision input, text output
➤ License: Proprietary, Meta's first frontier model not released as open weights
➤ Availability: No public API at the time of publishing. Meta expects to provide API access soon. Meta has started integration into their first party AI offering Meta AI and inside Facebook, Instagram, and Threads

5
533
Apr 7
Mythos is very impressive but what do Gary Marcus and Ed Zitron think
3
312
Anton Tsitsulin retweeted

Our goal in the Gemma team is to ship models that are useful by generalizing to unseen tasks. Hence, we are extremely strict about not doing anything that would target specific benchmarks instead of teaching the model broad capabilities. It's great to see this reflected here.
Apr 7

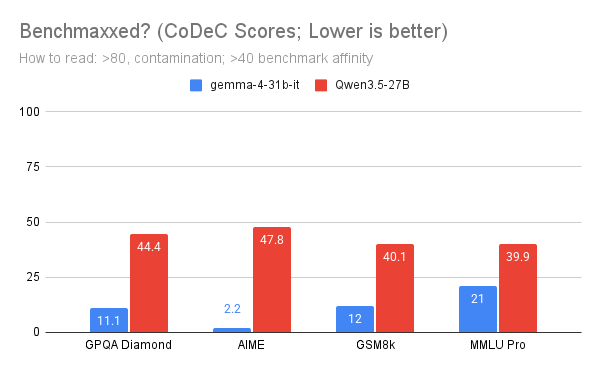
Qwen3.5 27B vs Gemma 4 31B IT
Here is why I think Gemma 4 31B wins:
Benchmark scores of both models are very close.
Generalization is not.
I reused NVIDIA’s CoDeC metric to probe "benchmark affinity".
Officially, CoDeC > 80 suggests contamination.
I've never seen this. But even below that, it can still reveal how benchmark-affine a model is.
Higher CoDeC scores mean the model is more "comfortable" with the benchmark.
So the ideal profile is:
high benchmark scores low CoDeC.
By that lens, Gemma 4 looks clearly stronger than Qwen3.5.
Gemma 4 likely generalizes better to unseen tasks.
I observed the same pattern earlier with Gemma 3 vs Qwen3.
I wrote about this a few months ago:
kaitchup.substack.com/p/did-…
12
38
413
46,784