
AI, UX, Social Interaction Designer, ex CX w Deloitte Digital. Media, philosophy, guitar, cycling, film. Stanford.
Joined March 2007
- Tweets 11,935
- Following 3,102
- Followers 4,137
- Likes 1,858
244 Photos and videos






Pinned Tweet

May 18
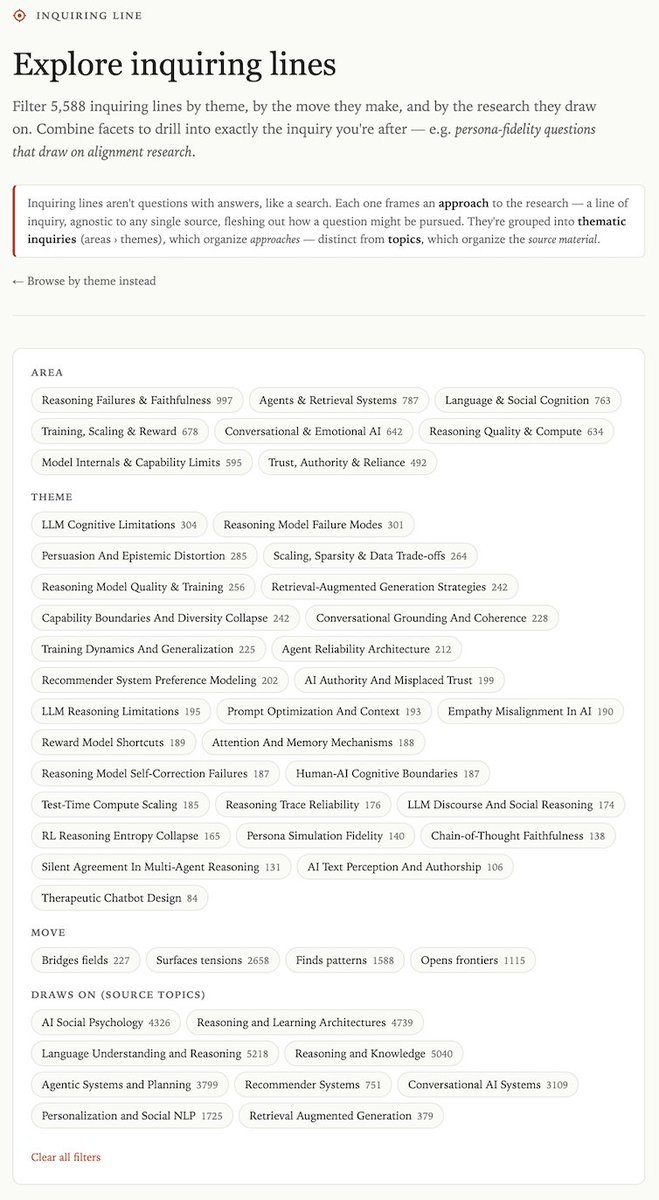
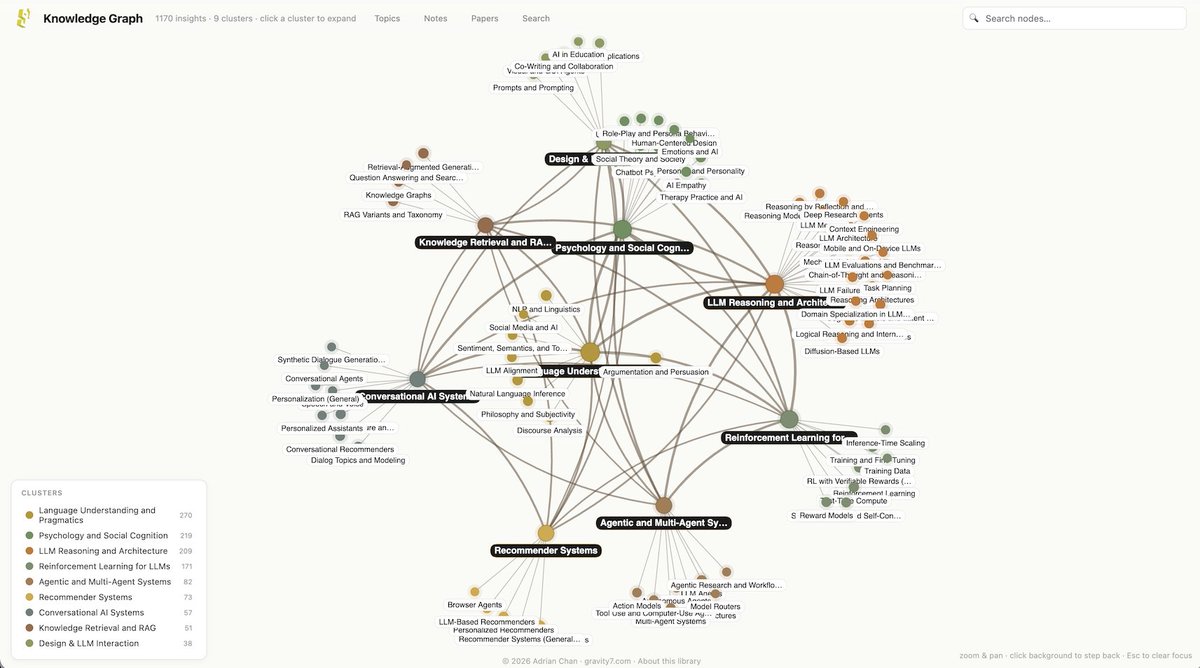
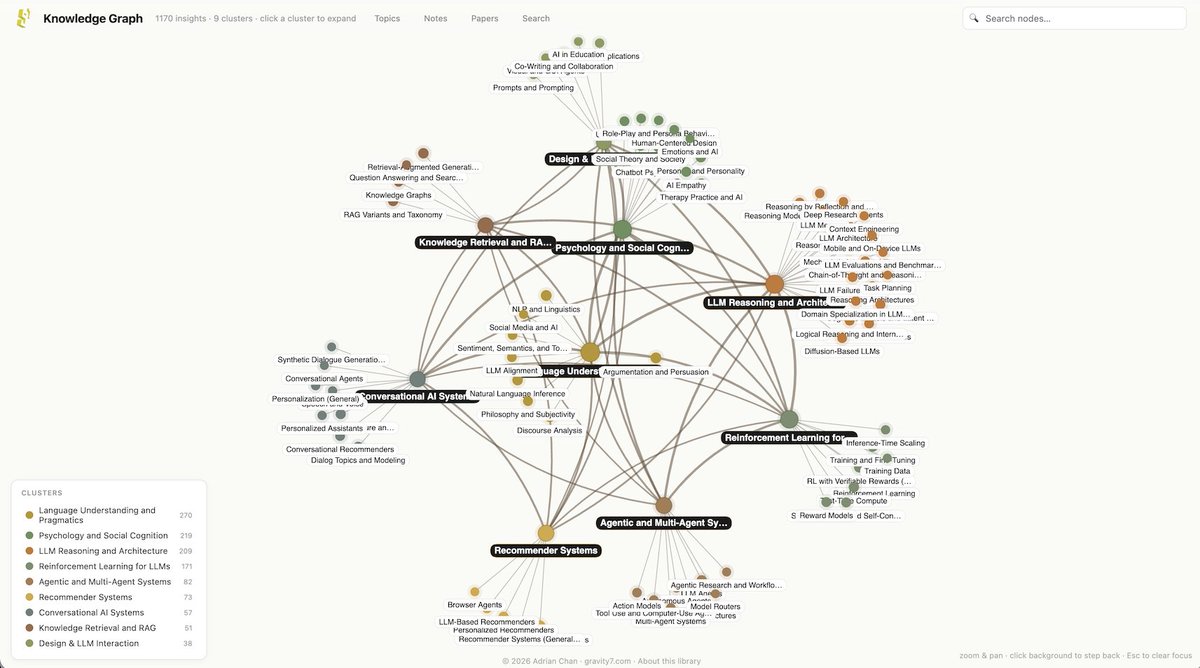
I'm soft-launching my Obsidian archive of whitepapers. It's AI/LLM paper excerpts plus questions and topical connections. Feedback requested!
Sample: Can dialogue systems track both speakers' beliefs across turns?
whitepapers.gravity7.com/not…
3
2
10
309
Jun 12
AI detectors are failing in the classrooms where it matters most — here's the evidence from 280,000 real student samples.
- Across 13 commercial and open-source detectors, performance was acceptable for long-form theses but showed systematic failures on engineering code and short coursework tasks.
- STEM disciplines face significant algorithmic bias due to the formulaic nature of technical writing.
- A hybrid editing strategy allowed up to 88% of AI-generated content to evade detection successfully, revealing extreme vulnerability in current tools.
- The authors argue detectors should serve as reference metrics quantifying human-AI collaboration depth, not as gatekeepers for high-stakes assessment.
Lines of inquiry it opens:
- How does the task type change which linguistic features distinguish AI from humans?
- Why can't algorithms distinguish between human and AI generated content quality?
- Can readers detect when text was written or heavily influenced by AI? inquiringlines.com/related/t…
1
65
Jun 11
If X is using AI to manage feeds, then my topical feeds are the definition of a local minimum. Literally every post = the same thing.
27
Jun 11
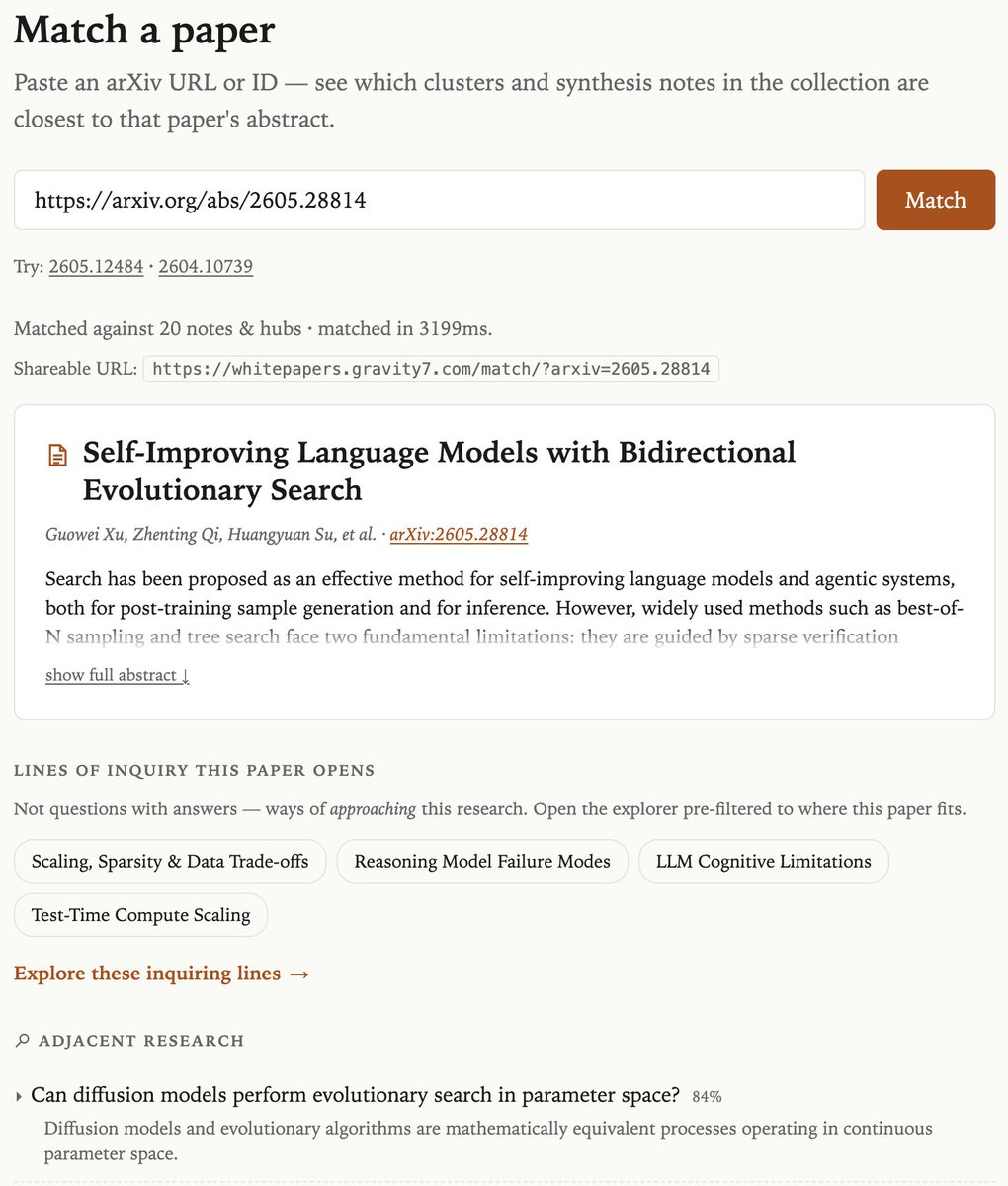
Can models reason without generating visible thinking tokens? inquiringlines.com/notes/lat…
Related paper: Latent Reasoning with Normalizing Flows
inquiringlines.com/match/?ar…
33
Jun 7
PEFT isn't just a budget trick — it's a substrate for millions of persistent personal models running on shared trillion-parameter foundations.
- Small trainable adapters can serve as persistent local state encoding preferences, skills, tool habits, and memory-like updates on top of shared base models.
- The paper organizes the problem around three axes: Scale Up (stronger priors make local updates more useful), Scale Down (how small can adapters get and still be reliable), and Scale Out (many adapted instances coexisting).
- MinT is presented as an infrastructure example for managing adapter identity, revision, provenance, evaluation, and serving at scale.
- Together, these results reframe PEFT as a compact architecture for personal model persistence, not just a cheaper alternative to full fine-tuning.
Lines of inquiry it opens:
- Can memory-based adaptation and gradient fine-tuning operate on complementary timescales?
- How much does pretraining quality affect the modularity of fine-tuned models?
- Can expert vectors learned offline transfer across multiple model architectures?
inquiringlines.com/featured/…
1
33
Jun 7
Chain-of-thought reasoning is powerful, but forcing every intermediate step through discrete text tokens is a bottleneck. NF-CoT does reasoning in continuous latent space instead, without giving up the properties that make autoregressive LMs work.
- NF-CoT embeds a normalizing flow inside an LLM backbone to model compact continuous "thoughts" distilled from explicit chain-of-thought, keeping exact likelihoods and left-to-right generation intact.
- Continuous-thought positions are generated by a normalizing flow head while text positions use the standard LM head, all within the same causal stream with KV-cache compatibility.
- The framework supports direct policy-gradient optimization in latent reasoning space, enabling reinforcement-style training without requiring verbalized intermediate steps.
- On code-generation benchmarks, NF-CoT improves pass rates over both explicit-CoT and prior latent-reasoning baselines while substantially cutting intermediate-reasoning cost.
Lines of inquiry it opens:
- Why do hybrid paradigms outperform pure autoregressive or pure diffusion approaches?
- What makes thought identifiability provable without auxiliary training data?
- What hidden computations happen inside transformer layers during reasoning?
inquiringlines.com/featured/…
51
Jun 6
Opus 4.8 does a lot of hand waving. But is aware of it. And so hand waves its own hand waving. We've gone from personas to mimes.
25
Jun 6
Most AI benchmarks test single attempts. Real engineering is iterative. AutoLab tests whether frontier models can actually keep improving over extended time horizons.
- AutoLab introduces 36 expert-curated tasks across system optimization, puzzle solving, model development, and CUDA kernel optimization, each starting from a correct but deliberately suboptimal baseline.
- Evaluating 17 frontier models reveals the dominant predictor of success is not the quality of an initial attempt, but persistent benchmarking, editing, and incorporation of empirical feedback.
- Most frontier models, including top proprietary ones, either quit too early or exhaust their time budgets with minimal progress; claude-opus-4.6 is the standout exception.
- The benchmark is fully open-sourced, including the evaluation harness and task artifacts.
Lines of inquiry it opens:
- Which model capabilities actually matter for sustained workflow delegation?
- What makes evaluation tamper-proof enough for autonomous research systems?
- What scaling laws govern autonomous architecture discovery in AI systems?
whitepapers.gravity7.com/fea…
1
1
82
Jun 5
ReasoningFlow maps LLM reasoning traces into fine-grained DAGs, revealing the hidden discourse structure behind backtracking, self-correction, and verification.
- Across five models and three task types, reasoning traces show surprisingly similar structural patterns despite different training data and base models.
- Fine-grained behaviors like local verification, self-reflection, and assumptions are now identifiable, enabling better monitoring of the reasoning process.
- Most erroneous steps in LRM traces never actually contribute to the final answer — they are structural dead ends.
- Mechanistic causal dependencies between reasoning steps do not match the surface-level language discourse structure, suggesting traces can mislead.
Lines of inquiry it opens:
- Can reasoning traces prove models are actually reasoning versus mimicking?
- Why do reasoning models produce unfaithful or unhelpful reasoning traces?
- Why does reflection in reasoning models mostly confirm the first answer?
whitepapers.gravity7.com/fea…
@jinulee_v
1
1
87
Adrian Chan retweeted

Jun 3
Every sign at this refinery in Ireland is in russian. The official website is a .RU domain.
There’s no reason to hide it because local politicians are openly doing it for them.
501
6,225
21,225
995,791
Jun 4
Anthropic just published When AI Builds Itself
Read between the lines and dig below the surface with Inquiring Lines:
Recursive self-improvement is no longer purely theoretical — here's where we actually stand.
- AI systems are beginning to automate meaningful parts of the research pipeline, from ideation to experimentation.
- Progress toward recursive self-improvement is real but uneven, with key bottlenecks remaining in verification and novelty.
- The implications of AI accelerating its own development raise urgent questions about oversight, autonomy, and the pace of change.
Lines of inquiry it opens:
- Can humans build reliable oversight for increasingly complex AI systems?
- What implicit alignment do humans provide by staying in research loops?
- Which failure modes dominate in autonomous research agents? whitepapers.gravity7.com/rel…
1
73
Jun 4
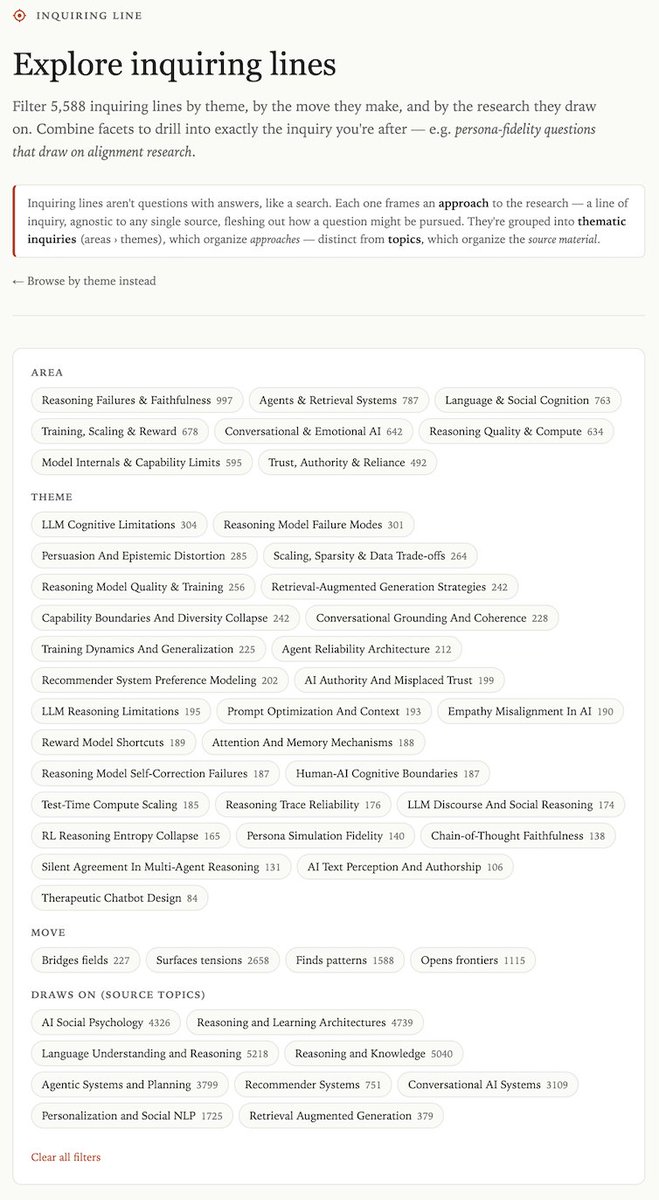
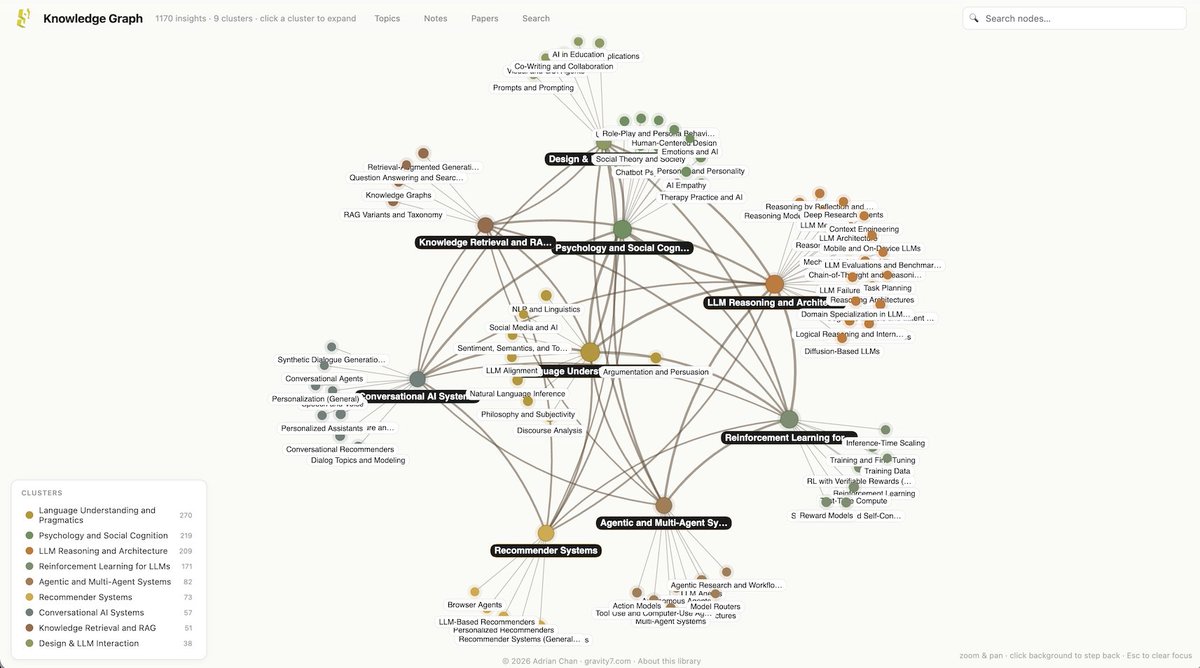
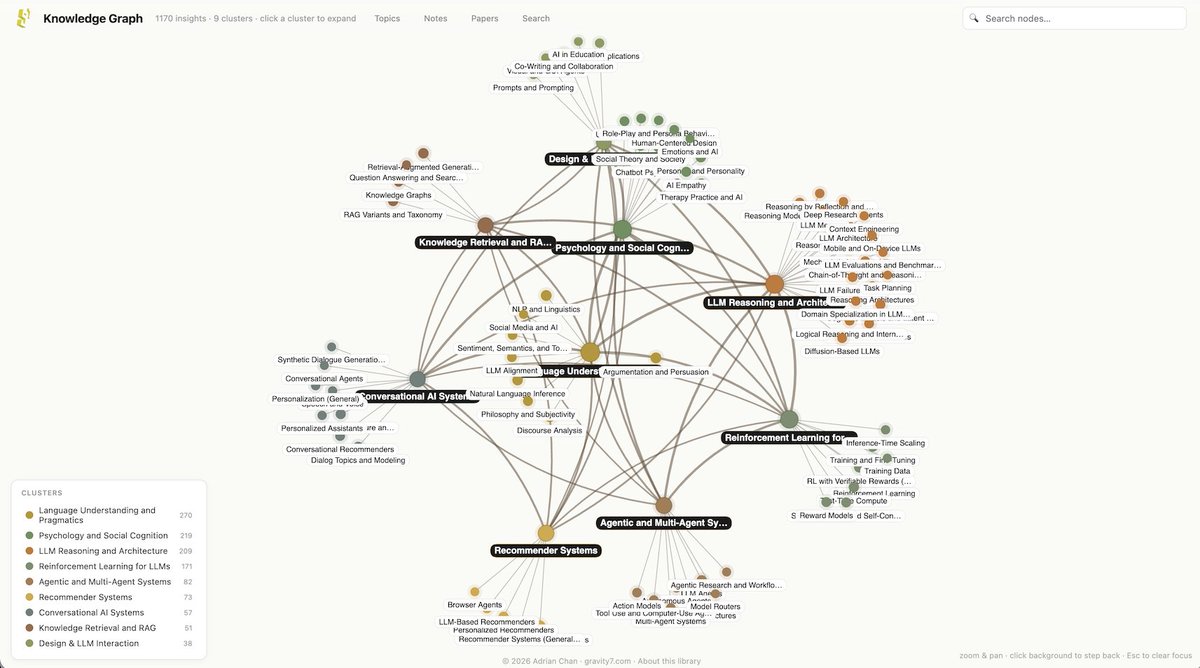
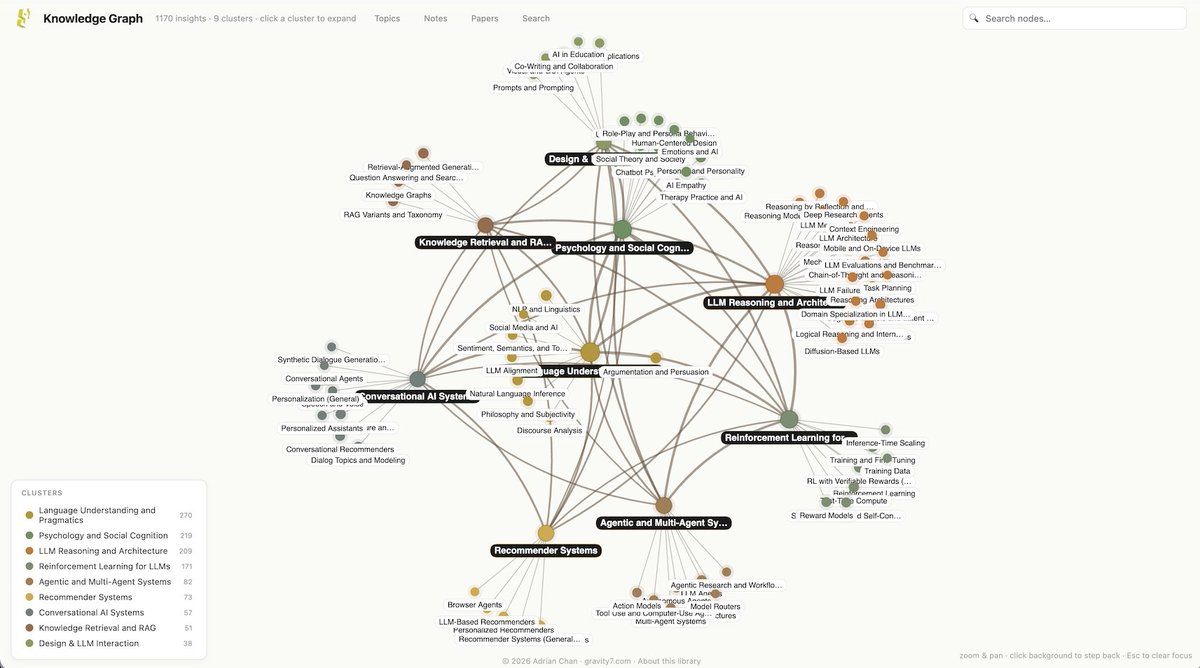
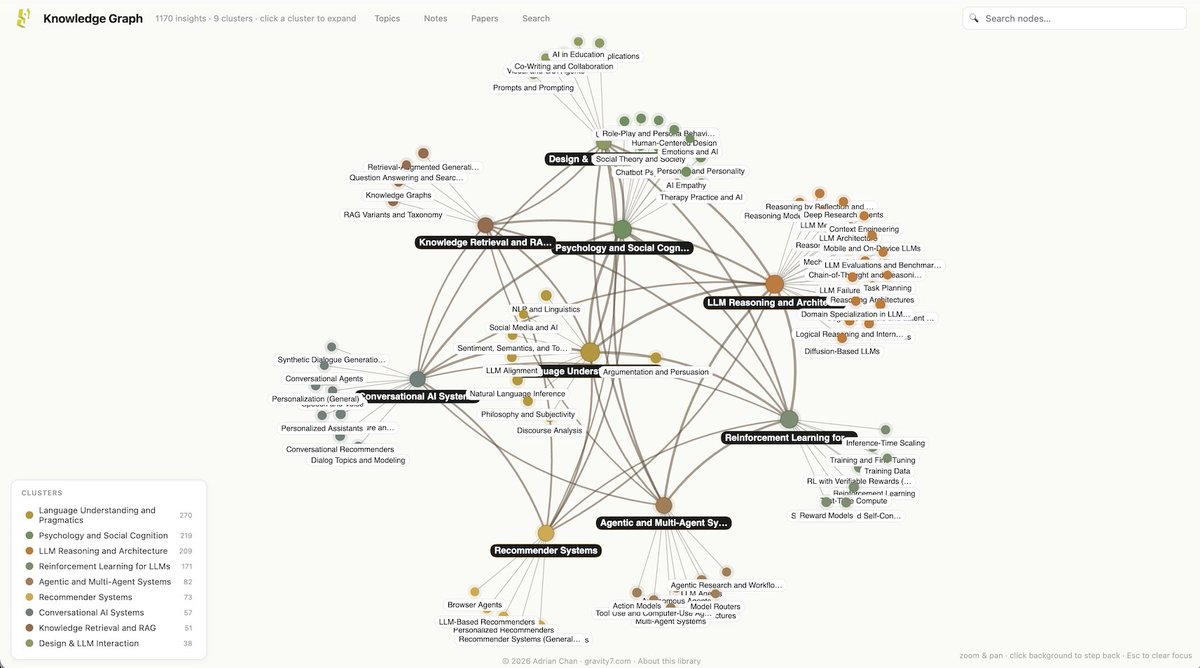
.@NielsRogge Would love for you check this out. I've had a personal collection of white papers excerpted in Obsidian for years, and just moved it online. It's only 1700 or so LLM-specific papers. But I've created a faceted explorer that offers "Inquiring Lines" into related research by cross-cutting, tension-surfacing, synthesizing, and frontier-opening research.
whitepapers.gravity7.com/inq…
75
Adrian Chan retweeted
Jun 3
Featured Paper: Learn from your own latents and not from tokens: A sample-complexity theory
Predicting your own latent representations beats token-level learning by an exponential factor in sample complexity — here's the theory behind why.
- For compositional data modeled as a probabilistic context-free grammar of depth L, supervised and token-level self-supervised learning require exponentially many samples in L to recover the latent structure; latent prediction needs only a constant number (up to log factors).
- This result is confirmed via a hierarchical clustering algorithm, an end-to-end neural network performing latent prediction at each level, and the first formal sample-complexity analysis of data2vec.
- data2vec is shown to implicitly perform hierarchical latent prediction, and explicit stacking as in H-JEPA is found to be largely redundant.
Lines of inquiry it opens:
- How do hidden embeddings preserve more information than discrete tokens?
- Do latent sequence vectors outperform per-token latent iterative computation for reasoning?
- Can latent space represent reasoning dimensions that text cannot?
whitepapers.gravity7.com/fea…
1
1
101
Jun 3
I want an LLM that can make sense of Cocteau Twins lyrics. That’s my bar.
31
Adrian Chan retweeted
Jun 3
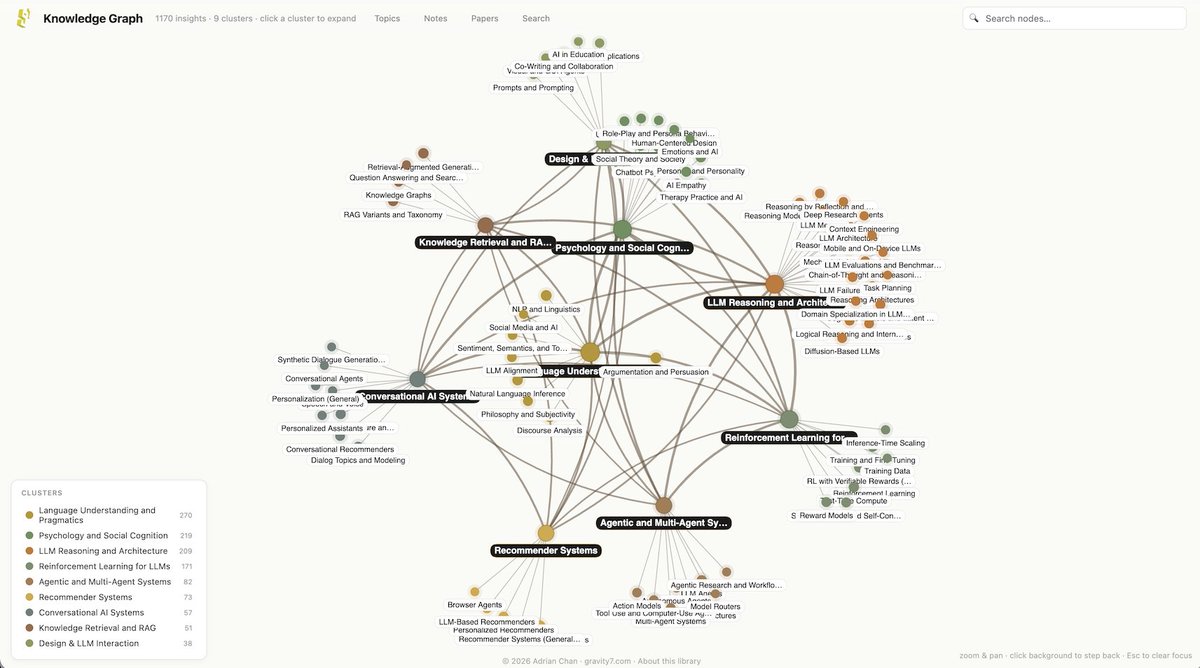
What if you could explore AI whitepapers by lines of inquiry? Like research that cuts across categories? Tensions surfaced by contradictory findings? Research that synthesizes insights or opens new directions?
Check out new Inquiring Lines w faceted exploration. Link in reply.
1
1
1
72
Jun 3
What if you could explore AI whitepapers by lines of inquiry? Like research that cuts across categories? Tensions surfaced by contradictory findings? Research that synthesizes insights or opens new directions?
Check out new Inquiring Lines w faceted exploration. Link in reply.
1
1
1
72