
Jun 12
Spark işlerinde performans sorunlarının nedeni her zaman kodun kendisi olmayabilir.
Bazen sorun, sorgu çalışmadan önce oluşturulan planın runtime’daki gerçek veri dağılımını doğru yansıtmamasından kaynaklanır. Güncel olmayan istatistikler, beklenenden farklı çalışan partition yapıları veya çalışma sırasında küçülen tablolar; Spark işlerinin beklenenden çok daha uzun sürmesine neden olabilir.
Yeni yazımızda, Apache Spark’ın Uyarlanabilir Sorgu Uygulaması (AQE) mekanizmasını ele alıyoruz.
Yazının tamamı aşağıdaki linkte. 👇
rebrand.ly/xsddd75
No Hype. We Make It Work. 🚀
#Treomind #ApacheSpark #SparkSQL #BigData #DataEngineering #AQE #AdaptiveQueryExecution #DataOptimization #SkewJoin #NoHypeWeMakeItWork
13

18 Nov 2020
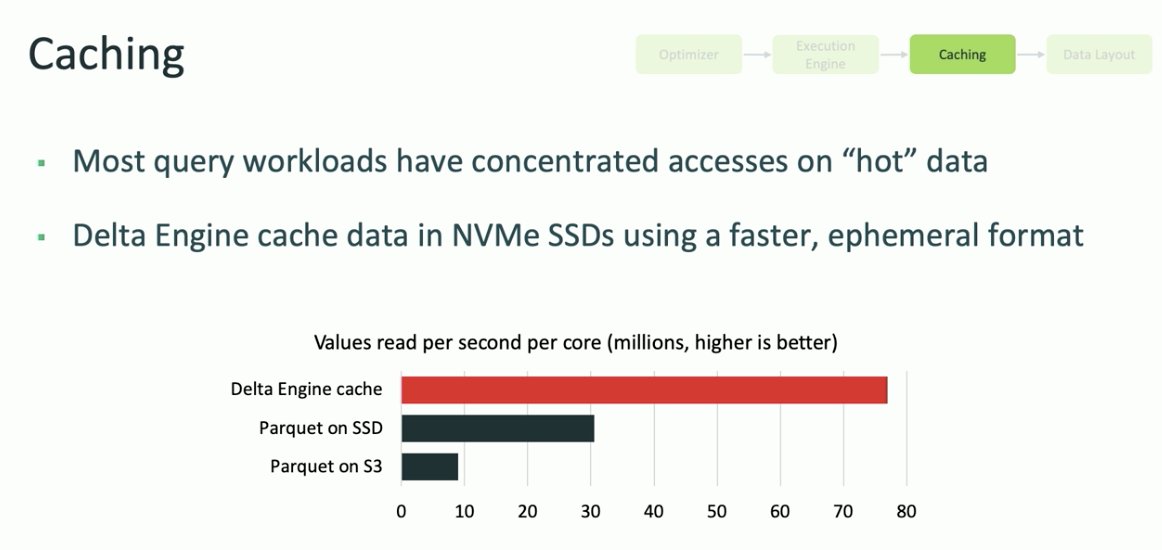
Life of a #SQLQuery. Excellent improvements with 1. #Optimizer with #AdaptiveQueryExecution 2. #ExecutionEngine with re-written C and ~10X faster (#JVM #Presto) 3. #Caching with fast store 4. #AuxiliaryDataStructure: #DataSkipping with #DeltaLake transactionlog #dataaisummit



4