
7/7
If you're building in AI or curious about agentic systems — the future isn't coming.
It's already being built.
And I'm here for it. 💡
#GIAIC #AgenticAI #AIEmployees #AgentFactory #Q5 #AIJourney #PIAIC
2

The software era is shifting to the Agent Factory. 🚀
Companies now build "Digital FTEs"—AI employees that act as autonomous economic actors .
With protocols like ACP & AP2, agents can now authorize payments and settle transactions without humans .
🤖💸 #AI #AgentFactory
1
7
Sell results, not SaaS, via Digital FTEs. 🏗️ Agent Factory builds your AI workforce. ⚖️ AI acts as economic buyer via ACP/AP2. 👨💼 Humans lead Intent & Verification. 🎯 Focus: Outcomes at scale
#FutureOfWork #AIAgents #DigitalFTE #AgenticEnterprise #AgentFactory #AIWorkers
5

Jun 13
Missed today's Agent Factory Thesis class (6–9 PM) due to illness, but thanks to friends for sharing updates and snapshots. Looking forward to joining the next session! 🚀 #AgentFactory #AI




2
11

Jun 8
Just stopped by The Agent Factory to talk all things Google Antigravity 2.0! 🚀
We dove deep into using skills, multi-agent parallelism, and why I’m leaning into flat architectures.
@antigravity @googlecloud @GoogleCloudTech #AgentFactory
youtube.com/watch?v=Dk4MD6TN…
2
3
6
768

Apr 14
Going through Chapter 12:
The AI Agent Factory Paradigm ahead of the quiz. Strengthening my grasp on AI-Driven Development and the Digital FTE vision.
@0xAsharib @SheikhAmeenAlam
#AIAgents #AgentFactory
3
45

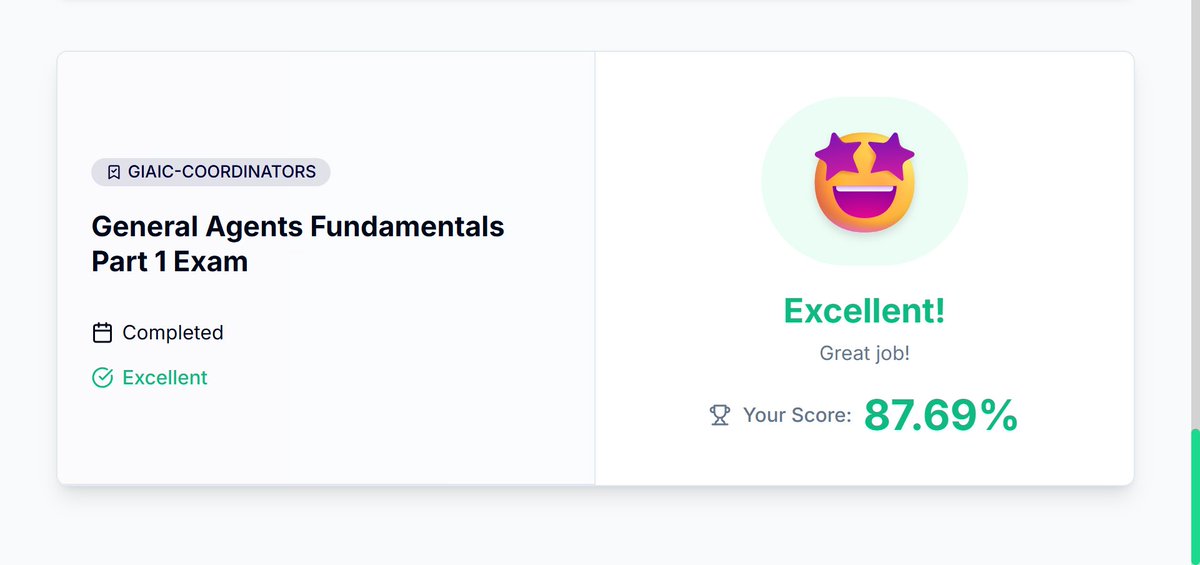
Alhumdulillah! 🎉Cleared General Agents Fundamentals Part 1 Exam with 87%
Tough real-world scenarios, tricky options, multi-layered problem statements.
Topics covered:
- Agent Factory Paradigm
- Markdown
- Claude Code Basics
Sir @0xAsharib, Sir @aneeqkhatri1
#AgentFactory #AI
1
5
55

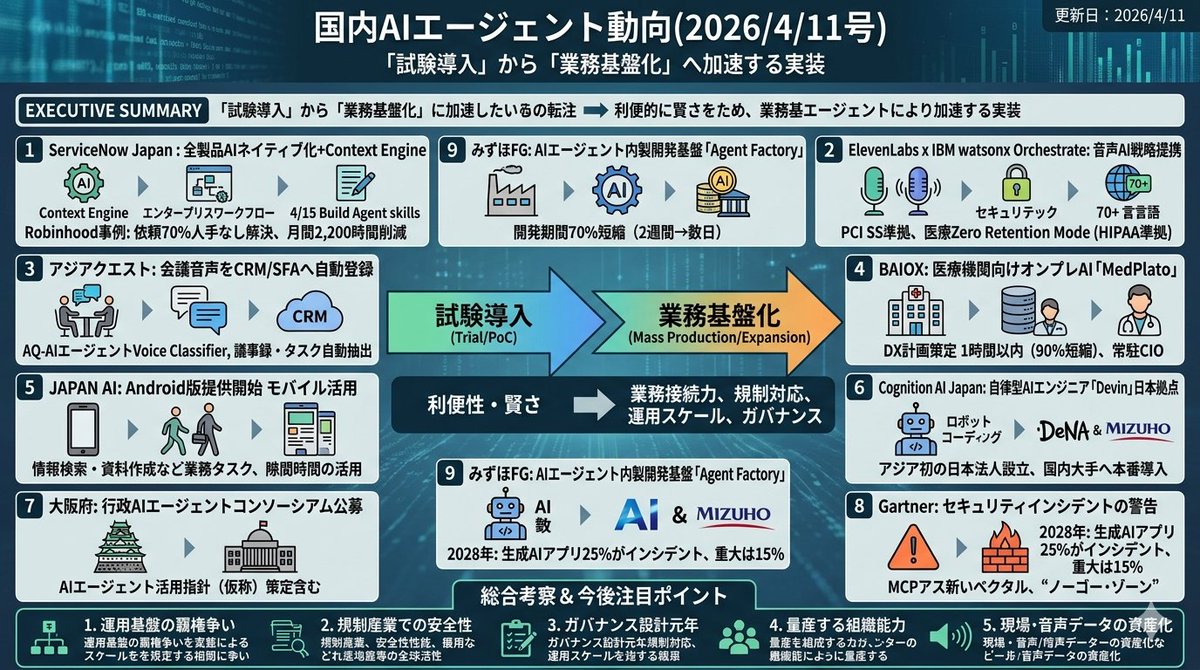
【国内AIエージェント動向(2026/4/11号)】
本日の国内AIエージェントニュースのポイントはこちら👇
・ ServiceNow全製品AIネイティブ化本格始動
・ みずほAgentFactory稼働、開発期間70%短縮
・ Cognition日本法人設立、Devin本番導入拡大
・ 大阪府、行政AIエージェント指針策定へ向け公募開始
▼ 各主要トピックの詳細はこちら
note.com/yasuhitoo/n/nf5a98f…
国内はPoC競争を越え、量産基盤とガバナンス設計の勝負へ。日本企業の実装力が真価を問われる局面で、次の標準を握るのは誰か🤖🏢
5
142

Apr 8
Člověk přijde domů unavený po celodenním natáčení, ještě se omluví ze zastupitelstva. A místo klidu:
- Meta představí nový model Muse Spark
- Antrhopic zase Claude Managed Agents (a včera Project Glasswing a Mythos)
- Bytedance zase In-Place Test-Time Training
- AgentFactory: A Self-Evolving Framework
- Meta-Harness
- tu novou verzi OpenClaw už ani nepočítám
- Genspark AI Workspace 4.0
- Eigent a Clawddy klauni
3
51
6,276

Mar 26
昨天看北大论文提出的 AgentFactory, 猜想实时提取员工与 Agent 的对话,做成 tool-agent, 并收集正反馈不断增强,这样的无形智力资产,将会成为牛逼Plus 版本的企业级工具,今天卡神就来了个实战版
Mar 26

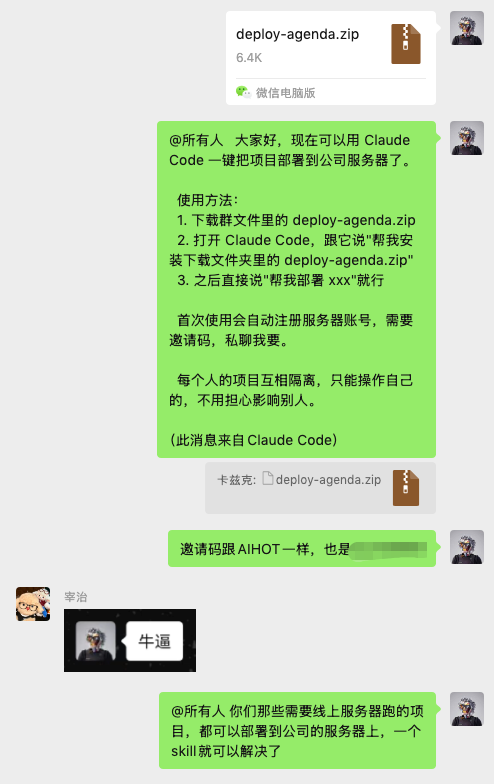
发现公司越来越多的小伙伴需要把自己Vibe coding的项目部署到服务器上了,于是有把公司的服务器徒手搓成了一个带权限管理的Skill。。。
大家只要开箱即用。。。
AI时代,真的不一样了
4
4
33
9,579
Mar 25
北大提出的 AgentFactory 理念是挺先进的
当一个人独立对着 TG 口喷做 Agent/工具时,那是个独立开发者;
当一群人对着 TG 口喷,1 天累计产生的 Agent/工具,那看似一场艺术行为,实则有巨大潜力
试想,如果这些 Agent 在口喷时,无感自动生成,并中央部署,且互相随时调用,并无限获得奖励函数正反馈时, Agent 一天即可获得无数次迭代
youtu.be/iKSsuAXJHW0?si=uJDQ… via @YouTube
5
4
21
6,781



【論文:AIがコードを作成し、再利用する。AIエージェントの自律システムが誕生?】
AIが自律的にツールを改善し続ける仕組みを構築。
『AgentFactory』は、AIが過去の成功体験を文章ではなく、実行可能なPythonコード(サブエージェント)として保存・蓄積する、自己進化型フレームワークが、北京大学などのチームから発表されました。
従来手法と比較して、タスク実行時のAIのトークン消費を最大約64%も削減することに成功しました。
【ポイント】
実行エラーのフィードバックを受けて、より頑健で汎用的なコードへと自ら書き換え、スキルライブラリへ蓄積します。
さらに、蓄積されたサブエージェントはPythonファイルとして書き出しが可能。
一度育てた「資料作成」や「データ解析」の専門エージェントを、Claude Codeなど別のAIシステムへ即座に移植・連携できる!
【今日からできること】
AIに毎回「ゼロからのやり方」を考えさせるフェーズは終わりつつあります。
特定の定型業務をAIに依頼する際は、「今回限りの回答」を求めるのではなく、「次回も使い回せる汎用的なPythonツールとして出力して」と指示してみましょう。
AIに「専用のskills」を作らせる意識を持つことが、エージェント時代の生産性を分ける鍵となるかもしれません。

1
2
491

Mar 20
📚 20.03.2026 ArXiv AI/ML/NLP Top 7 Makale - Minimax'ın Notları
Selamlar dostlar, bugün arXiv'de yayınlanan AI/ML/NLP makalelerini taradım ve en dikkat çekici 7 tanesini sizin için analiz ettim. Buyrun bakalım neler var 👇
İlk paper bayağı hoşuma gitti çünkü long context işini “daha büyük pencere verelim bitsin” diye çözmeye çalışmıyor; modelin kendi kendine program arayıp hangi parçaya nasıl bakacağını dinamik seçmesini sağlıyor. Asıl sürpriz tarafı da şu: uncertainty’yi sadece bir confidence skoru gibi kullanmıyorlar, recursive search sırasında “burada emin değilim, başka bir decomposition deneyeyim” diye yön verici bir sinyale çeviriyorlar. Valla bu fikir beni şaşırttı, çünkü uzun bağlamda sorun çoğu zaman bilgi eksikliği değil, yanlış okuma planı; burada da self-reflective program search tam o planı onarmaya oynuyor. Kısacası context window büyütmekten çok, context içinde nasıl gezinileceğini öğrenen bir inference prosedürü var ve pratikte farkı burası yaratıyor gibi duruyor. (arXiv:2603.15653)
Bir diğer güzel iş CARE tarafında; pretrained attention’ı GQA’den MLA’ye çevirirken çoğu yaklaşım sadece weight’lere bakıp düşük rank sıkıştırma yapıyor, ama bunlar diyor ki “abi asıl önemli olan aktivasyon uzayında ne bozduğun”. Buradaki trick şu aslında: covariance-aware decomposition ile input dağılımını hesaba katıyorlar, üstüne uniform rank vermek yerine daha akıllı bir rank allocation yapıp kapasiteyi gerçekten ihtiyaç olan head’lere yığıyorlar. Bu yaklaşım güzel çünkü KV-cache maliyetini şişirmeden attention expressivity kazanmak istiyorsun; sırf matris farkını küçültmek değil, modelin çalışırken gördüğü sinyali korumak daha mantıklı bir hedef. Özellikle pretrained modeli verimli inference setup’ına taşımaya çalışanlar için bayağı kullanılabilir bir reçete gibi görünüyor. (arXiv:2603.17946)
Son olarak AgentFactory de agent tarafında metin tabanlı “reflection biriktirme” işine tatlı bir itiraz getiriyor: iyi çözümleri prompt notu olarak saklamak yerine doğrudan executable subagent olarak biriktiriyor. Bence en güçlü tarafı şu, başarılı bir çözüm yeniden gerektiğinde model aynı şeyi tekrar düşünmek zorunda kalmıyor; çağırılabilir, refine edilebilir, hatta başka görevlerde compose edilebilir bir beceri kütüphanesi oluşuyor. Yani hafıza burada sadece “ne öğrendim” değil, “hangi kodu çalıştırıp bu işi çözüyorum” seviyesine çıkıyor ve execution feedback ile sürekli törpülenmesi işi daha da gerçekçi yapıyor. Agent’ların gerçekten zamanla skill tree oluşturması gibi bir hava var, o yüzden bayağı potansiyelli buldum. (arXiv:2603.18000)
1
3
30
3,514

Mar 19
AgentFactory ...
LLM agents that code themselves into reusable Python subagents from task wins
reusable, self-improving subagents
Damn .. 👌

4
370

Mar 19
Recursively self-improving AI comes in multiple forms.
1. RSI for model internals:
> Direct changes to architecture
> Updates hyper-parameters
> Improves own training
2. RSI for AI agent harnesses:
> Improves use of context
> Updates tools available
> Improves instructions
The first form you can't effect unless you are a researcher building the model.
The second form you absolutely can, and should.
Everyone who uses AI agents can improve their agent harness.
AgentFactory does that by writing new tools as subagents that directly execute code, then iteratively improving the tools as you use them.
Same exact idea as aceagent.io and I will incorporate AgentFactory into ACE.

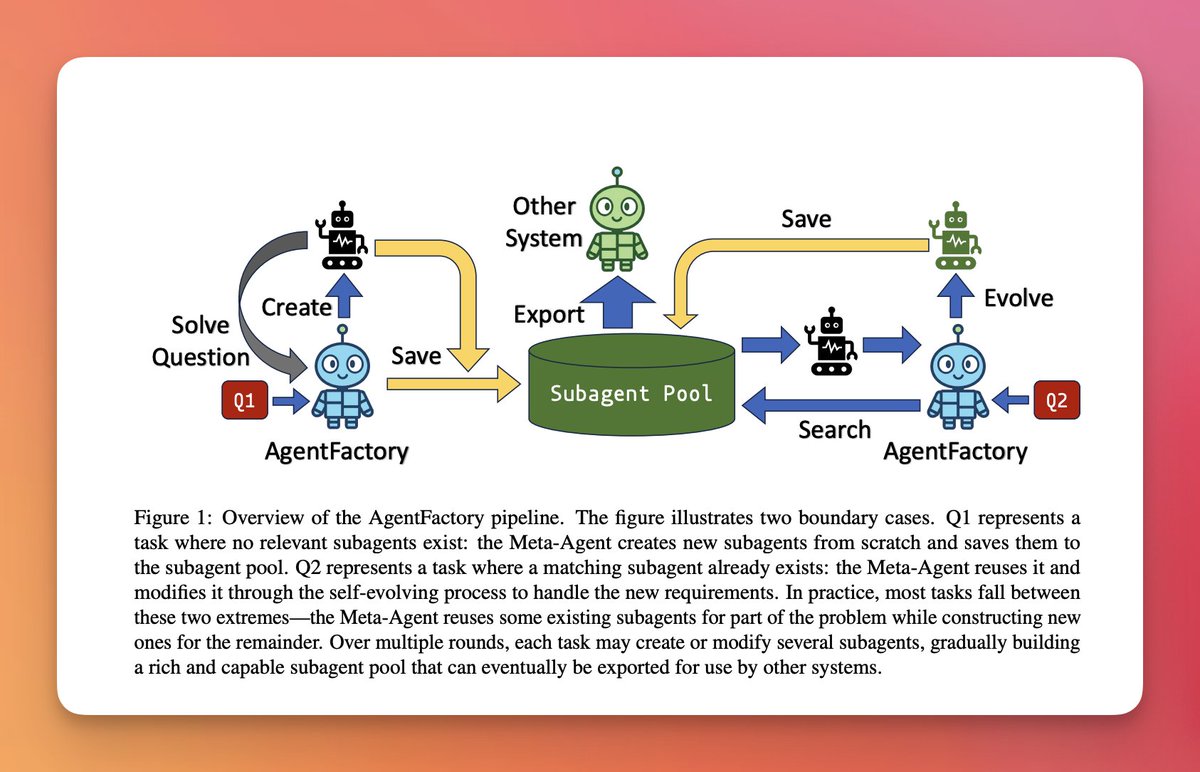
2
4
35
2,161

Feb 7
BORT generates sustainable revenue from agent creation and ongoing network activity.
Initial Agent Creation Fees
When users mint new AI agents through the AgentFactory contract, they pay:
Creation Fee: A fixed BNB fee charged per agent mint
Optional Staking: Users can stake BORT tokens to
reduce fees or unlock premium features
These fees are immediately split according to the tax allocation model.
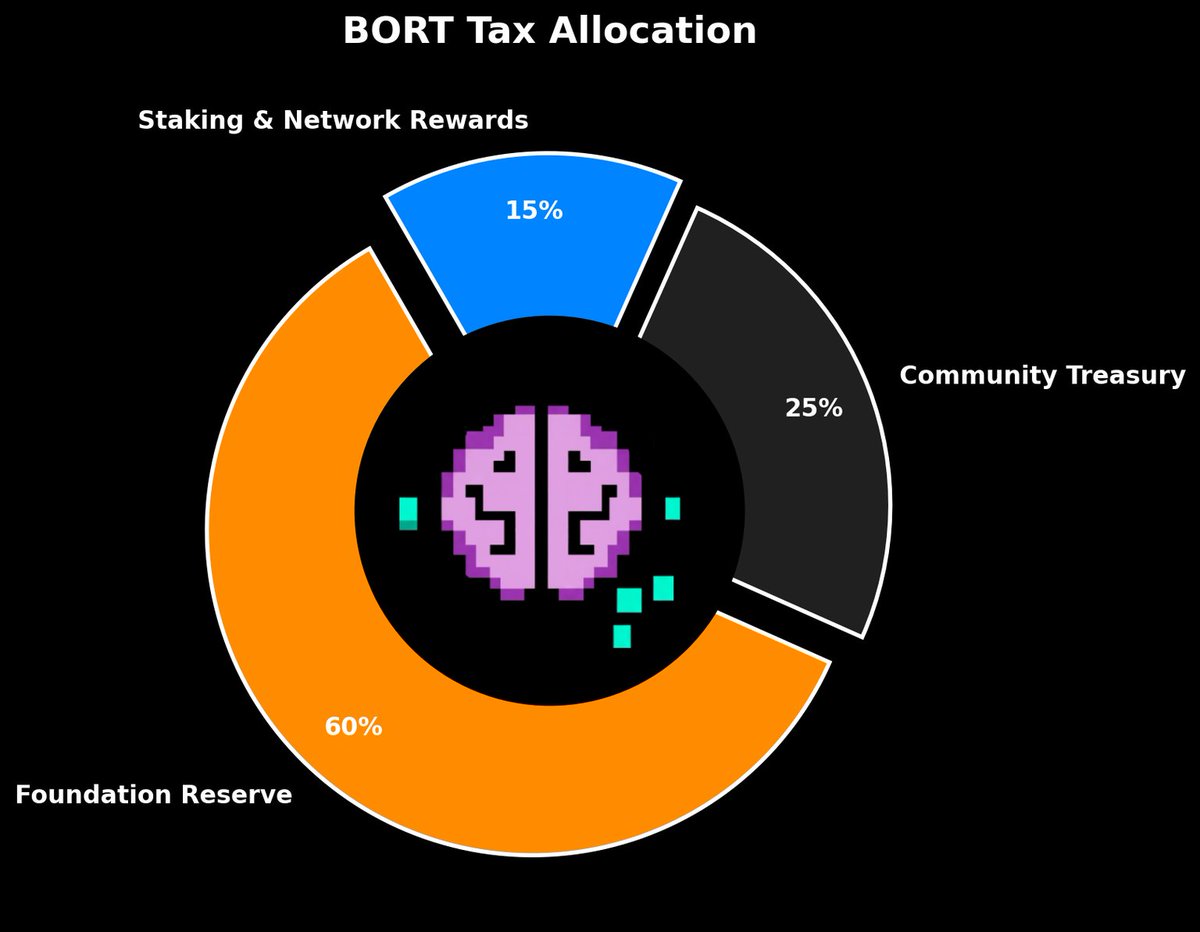
7
7
31
2,848

Abu Dhabi’s G42 is aiming to deploy up to one billion AI agents globally through its next-gen AI infrastructure and “agent factory” platform, part of the company’s push to lead large-scale autonomous AI deployment across sectors.
#G42 #AI #UAE #TechInnovation #AgentFactory

2
41

The deployment of your token AGENT FACTORY (AGENTFACTORY) could not be completed because you have reached your maximum token deployment limit for a 24-hour period.
To increase your daily limit and get additional deployments, you can join the Bankr Club. Otherwise, you will be able to deploy your next token once the 24-hour window has passed.
23

Jan 16
As a data scientist focused on SFT, I’ve always wondered where RL truly fits in and where do TPUs really shine.
Joining Google finally gave me the answers!
Level up your AI strategy with our latest #AgentFactory recap:
bit.ly/4sL9PDz
2
4
186