CrazyCao retweeted

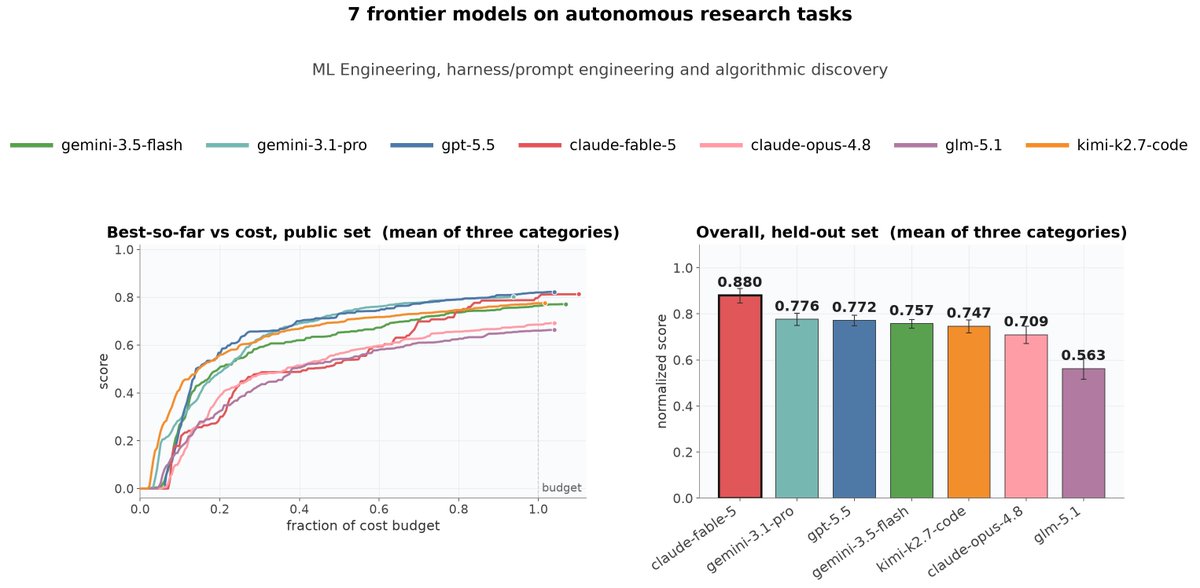
We benchmarked 7 frontier models on 3 categories of autoresearch tasks: ML engineering, harness/prompt engineering, and algorithmic discovery.
Fable-5 won overall even under cost constraint, but on ML engineering, the open model Kimi-K2.7-Code surpassed frontier models.🧵(1/5)
12
21
274
20,730


NEW VIDEO!!! 📽️🎞️💓
Karpathy's Autoresearch Explained - Then Built It for Email Marketing
DURATION: 13 minutes
Enjoy! 🔥
youtu.be/klyuNN2DNUg?si=P6_Z…
@theo @thdxr @chooserich @aiDotEngineer @swyx @MichelleBakels @Beccalytics @gabegreenberg @elonmusk @karpathy @bcherny
13

the collaboration aspect is fun, maybe the first truly collaborative autoresearch comp?
1
25

Did you do an analysis on similarity of answers or scores across problems.
I’m specially curious given the recent results from @OpenRouter Fusion API:
Maybe a bag of models, would perform better. Specially, in a verifiable domain as autoresearch.
Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

1
2
687