
24 Jun 2025
Improving Genomic Models via Task-Specific Self-Pretraining
1.This paper introduces a simple yet effective strategy: self-pretraining DNA language models (DNALMs) on task-specific unlabeled sequences, instead of the entire genome. Surprisingly, this compute-efficient method can match or even outperform models trained from scratch and some genome-pretrained models.
2.On the BEND benchmark, self-pretraining (SPT) shows strong performance, especially in CpG methylation and gene finding tasks. For CpG methylation, SPT achieves the highest AUROC across all evaluated models, including expert methods and large pretrained models like DNABERT and GENA-LM.
3.In the gene finding task, adding a linear-chain Conditional Random Field (CRF) layer to the SPT model leads to a substantial gain—from 0.50 to 0.64 MCC—by capturing global sequence structure (e.g., valid exon-intron transitions), which standard classifiers cannot model effectively.
4.Compared to genome-scale pretraining, SPT offers a practical alternative under compute constraints. It avoids the need for massive unlabeled corpora, relying only on task-relevant sequences (e.g., gene-finding data) that are already available in many genomic workflows.
5.The study highlights that for tasks like histone modification and chromatin accessibility, where supervised training already performs well, SPT yields marginal gains—suggesting these tasks may not benefit as much from pretraining. However, for harder tasks or low-data settings, SPT excels.
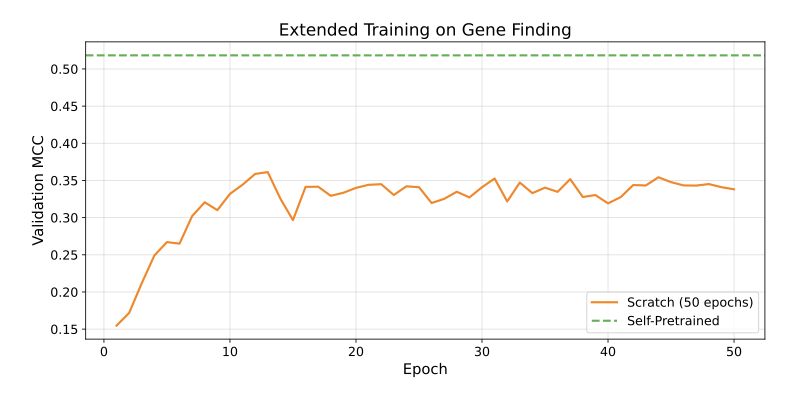
6.An extended training analysis shows that scratch-trained models plateau early—even with prolonged epochs—and still fail to match the performance of SPT models. This suggests that the inductive bias learned during self-pretraining is not easily recoverable via more training.
7.SPT also improves sample efficiency. On CpG methylation, a model trained with only 25% of the labeled data and SPT outperforms the scratch model trained on 100% of the data. This makes it especially valuable for genomics, where labels are expensive but sequences are abundant.
8.The architecture used is a 30-layer dilated CNN, pretrained with masked language modeling on gene-finding sequences. During fine-tuning, the model is adapted to four BEND tasks: gene finding, chromatin accessibility, histone modification, and CpG methylation.
9.Unlike prior DNALMs that rely on vast genome-scale pretraining, this approach shows that task data alone can be sufficient when paired with self-supervised pretraining. It builds on trends from NLP and long-context modeling where task-specific pretraining has shown surprising strength.
10.Overall, this work challenges the assumption that only massive pretraining enables good performance in genomic modeling. Instead, it shows that strong supervised baselines can be built using targeted self-pretraining—particularly beneficial for low-resource labs or specific applications.
💻Code: github.com/SohanMupparapu/dn…
📜Paper: arxiv.org/abs/2506.17766v1
#Genomics #MachineLearning #DNA #Bioinformatics #DeepLearning #DNALanguageModels #Pretraining #BENDBenchmark
1
2
692