
Jun 10
The pedagogical term for this is backchaining. Teaching the end of a "performance" first helps someone to learn how to move in a fluent motion from a beginning to an end.
2
46

Good morning! And good Job Triton! Chúc mừng 🎉 bạn hoàn thành ngày thử thách thứ 2! Bên dưới là nhận xét cho bài số 2:
Điểm tích cực :
- Một số cụm tiến bộ rõ: “export turnover has increased significantly”, “We aim to double the revenue in the next three years”, “The company can quickly go bankrupt”.
Những điểm cần cải thiện chính :
1. Âm cuối từ (Ending sounds) – Vấn đề lớn nhất và lặp lại nhiều
Hầu hết âm /s/, /z/, /t/, /d/ cuối từ bị nuốt hoặc phát rất mờ, điển hình của người Việt:
increased, costs, revenues, competitive, allocated, upgrading, equipment, expanding, logistics, inflows, outflows, bankrupt, buildings, machinery, inventory, liabilities, payable, suppliers, partners, obligations.
Làm câu nghe chưa rõ ràng và mang accent nặng.
2. **Ngữ điệu & nhịp điệu**
Cách nói còn hơi thiếu 1 xíu lên xuống tự nhiên. Câu dài nghe như đọc liệt kê thay vì nhấn mạnh từ quan trọng (significantly, double, critical, bankrupt). Chưa có nối âm (linking) giữa các từ.
3. Một số âm và từ cụ thể chưa chuẩn:
- “aim” đọc gần như “am” (thiếu âm /eɪ/ rõ ràng, cần miệng hơi cười, kéo dài thành /eɪm/).
- “revenue”, “competitive”, “logistics”, “liabilities”, “expenditure”, “payable” vẫn mang giọng Việt, nhấn sai và âm cuối mờ.
- Một số filler “uh… are, are…” khi đang nghĩ.
Nhận xét tổng quát:
Bạn tự tin và nội dung mượt hơn so với mức cơ bản. Tuy nhiên, âm cuối từ và ngữ điệu là hai điểm cần luyện mạnh nhất để tiếng Anh nghe chuyên nghiệp và dễ hiểu hơn khi nói kinh doanh.
Gợi ý nhanh:
Mỗi ngày luyện 10-15 phút âm cuối với backchaining (tập từ cuối lên): costs → production costs → reducing production costs.
Tập riêng “We aim to double…” và “stay competitive”. Shadow các câu có “bankrupt”, “liabilities”, “inflows and outflows”.
Bạn đang tiến bộ tốt, kiên trì thêm 1-2 tuần sẽ thấy khác biệt rõ. Cố lên Triton! 2 tuần nữa coi lại video này sẽ thấy rõ
2
42

Mar 23
Quantum logic-based computation easily gets stuck 🛑 My research addresses this by using physical commutativity to enable backchaining & unification in Gentzen’s sequent calculus. ⚛️📜
doi.org/10.1007/s42452-019-1…
#QuantumLogic #LogicProgramming #CompSci

2
4
438

Mar 5
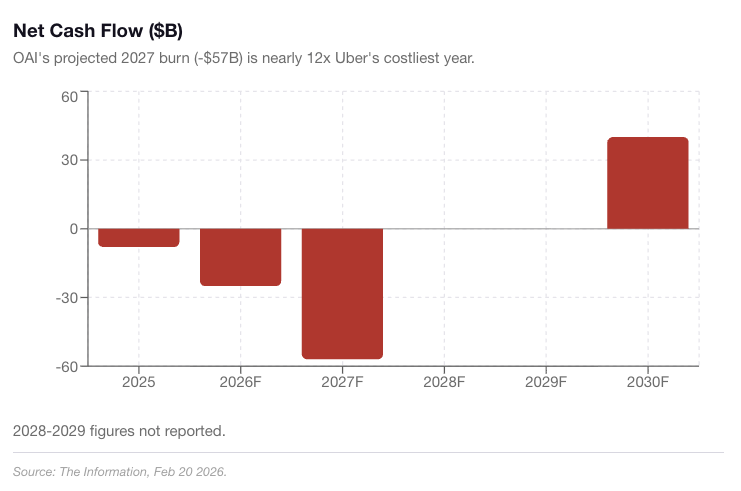
Surprising untapped alpha to be had in backchaining from lab revenue forecasts to implicit timelines to transformative AI.
Eg: OAI expects to go cash flow positive in 2030. How do they expect to pull this off, and what does this imply about their expectations of technological progress?
Looking at the numbers suggests OAI are betting that huge training runs in 2026-29 will deliver capabilities that make the big bucks. After that, growth in training compupte will slow.
1
1
6
234

alignment researchers backchaining
Jan 30

STEP 1
Work hard to achieve my goals.
STEP 0
Figure out what to do to achieve my goals.
STEP -1
Figure out what my goals should be.
STEP -2
Establish sound methodology to interpret and resolve deontic questions.
STEP -8
How is it that some things are, while others fail to be?
7
463

19 Oct 2025
If I were going to actually make the movie, the next question is "okay what actually is the arc, or source-of-tension/surprise?" and see what sort of narrative ending would actually be compelling, and then futz around backchaining from that until something worked.
(like, to be a movie instead of a fun tweet it must succeed at being good art as the first maslow-hierarchy of art)
Since the characters don't get to experience growth in the usual way, the tension needs to be from something like dramatic irony or the suspense of "what's going to happen in the next round?".
The ending needs to somehow function as a way for the audience to go "okay, that was a reasonable time to stop repeating the loop." Which can be because the AI situation is resolved, or, could be because something is revealed about a character or the situation that makes it narratively satisfying that the AI situation won't be resolved.
2
583

22 Sep 2025
This stuff is pretty important. Situational awareness (also known as self awareness) in AI is on the rise. This will make ~all evals more difficult to interpret, to put it mildly. (it'll make them invalid, to put it aggressively). To put it another way, insofar as AIs can tell the difference between testing and deployment, how they behave in one can be arbitrarily different from how they behave in another, and moreover there's reason to think it will eventually be very different, because of incentives.
Another reason why this is important is that studying CoT transcripts might give us some (imperfect, uncertain) insight into what the true goals/values/etc. of our AIs are. What concepts do they spend a lot of time backchaining from? When conflicts arise between subgoals, what tends to take priority? For a given hypothesis, are there any examples that falsify it? I personally have updated somewhat towards the "Reward will be the optimization target" hypothesis on this basis, though I still think it's less than 50% likely.
18 Sep 2025

When running evaluations of frontier AIs by OpenAI, Google, xAI and Anthropic for deception and other types of covert behavior, we find them increasingly frequently realizing when they are being evaluated. Here are some examples from OpenAI o-series models we recently studied:

20
34
270
33,604

because of the self-similarities in the universe's development from cosmic timescales to local timescales from local spacescales to cosmic spacescales..
one thing that's possible to do to predict the future/make it easier to do so is to first predict some things that "for sure" will happen and then retrodict
this isnt the same as backchaining, which is goal directed (pick outcome you'd like to happen, backchain steps to get there)
it's oracular/predictive - you guess something that has to happen, then that narrows space for what happens in the future because it has to funnel towards that
ppl do it already for a lot of stuff but you can leverage it more broadly
1
4
625


25 Mar 2025
jeez does piecing together "you're supposed to have like 2000 calories a day and get a reasonable amount of each of the three macros" constitute "agentic backchaining detail" now? maybe im more impressive than i thought
3
41

24 Mar 2025
I've been pondering for a while whether the weave-agent planner should be more like ReActTree (openreview.net/pdf?id=KgKN7F…) or MuZero (arxiv.org/pdf/1911.08265) and I think MuZero is starting to win the argument in my head. The basic reason why being that lazy hierarchical planning where you break a task into parts and assign subagents to the parts requires a ton of upfront work from the agent and serial ops. My original intuition was that programming is already a form of hierarchical planning so if I frame the parts of the tasks as subagents with inputs and outputs then I can reuse the existing python coding ability to plan. The problem is that weave-agent also tries to make sure subagents don't mark their tasks as complete early by adding unit tests to the completion states. Even if we removed those the syntax for creating a subagent currently looks like this:
```
def check_dismissed(subagent):
"""Check if the bot has been dismissed by a user."""
response = requests.post("http://localhost:8080", json={"action": "get_messages"})
messages = response.json()
for msg in messages:
if msg["content"] == "You are dismissed." and msg["author"] != "weave-agent":
return True
return False
schema = {"dismissed": "boolean"}
main_agent = agent.subagent("main", None, "Interact with users until dismissed", schema, args.budget)
main_agent.task.add_evaluation("Check if dismissed", check_dismissed)
```
Which is a huge amount of boilerplate when the behavior we actually want to facilitate looks more like this:
```
def do_conversation(subagent):
"""Have a conversation with the user."""
# Introduce ourselves and profile the user
profile = introduce_and_profile_user()
# Set a topic of conversation
topic = set_conversation_topic(profile)
# Discuss the subject
conversation = discuss_with_user(profile, topic)
if dismissal in conversation:
return True
```
Which, while intuitive, if we think about it for more than 30 seconds runs into all sorts of problems including:
1. What if the user wants to discuss more than one thing or switch topics? Should the agent railroad them so it can focus on the plan?
2. How does the agent know when to end the conversation or when the conversation has ended? We could say to use its general intelligence but how do we ground that for training purposes? If we say the rewards come from in-context verifiers then those don't appear in this function, so clearly a separate process would need to go in and translate these conjectured function calls into all the boilerplate above with the schema and such.
3. This translation/generation would be a lot of upfront work and be a ton of latency. We could offset this by only doing the work necessary to get started on the task and then generate the rest in the background while we do other things, updating and reshaping it (how?) as circumstances change so that by the time we're ready to task switch it's almost effortless.
4. The structure of the plan/program itself feels off to me. A conversation usually isn't made up of one topic, if the user immediately gets into a topic with me I might want to delay learning autobiographical information about them or learn it incrementally through context cues in the conversation, etc.
5. This kind of program doesn't seem to really encode alternatives and possibility space well. That can be partially mitigated by expecting subagents to return a failure when expected conditions don't manifest. Essentially returning an error when the vibe coder in the background can't make the plan fit the conditions and the agent can't make the conditions fit the plan. Some of it could also be mitigated by writing programs with if conditionals and loops so that e.g. a set of expected opening topics could be written down and the conversation formulated as some kind of stack based loop where conversations start and end returning zero or more continuation topics and it ends when there are no more continuations on the stack.
One major problem with this is that we are no longer really proposing to use standard python to let the agent control itself. Rather we are now considering making a domain specific planning language which is a subset of python whose semantics are inferred and compiled into actual executable code by a language model. I could make this, it wouldn't even be particularly hard with models like R1 available to perform the tedious grammar parsing and syntax extraction tasks. Though I'm not sure how reliable it would be, and we're already involving a language model to flesh out the plan and reshape it to circumstances to such a degree that the python code plan itself feels increasingly vestigial.
So what would the MuZero approach look like by contrast?
Before answering that I think it would be useful to point out something important about planning. When we perform tasks in the real world there is both latency and serial bottlenecks from the environment to consider. Even if we have a bunch of GPUs, we can only use them to make generating and executing *any particular action in the moment* so fast because there are irreducible computations we can't shard out which must be waited on. However we can use our world model to simulate as many hypothetical parallel futures as we want since they're not entangled with environmental state or each other so they can be ran in parallel as far out as we can model. This means that if we want to continue scaling our inference compute for agents we will always end up picking a design that lets us use more planning to make actions in the moment faster to execute and more effective. We will also always want to have some kind of background process that subconsciously plans at the same time the agent does stuff so we can maximize our number of useful parallel ops. In other words we always want to be planning and we always want to be planning in ways that make every action in the canonical branch of our MCTS better than it would be without the planning since we can't actually use our parallel ops to make individual actions better in real time except by e.g. scaling the model.
If you've never read the MuZero paper it's actually pretty simple. The basic idea is that we have an RL agent with the usual RL agent components like state transitions, a utility funtion, etc. We give the model a history of observations and actions, then ask it to predict three things: The policy (next action), utility/value of the action (which is trained on the whole trajectory so presumably encodes long term reward), and the actually observed immediate reward feedback from the environment. It turns out this 'shallow trace' of agent-environment interaction behavior is sufficient to teach the agent to model the game and win. MuZero as described in the DeepMind paper uses a Monte Carlo Tree Search to hypothesize over future reward trajectories and find the series of actions that is most worth taking.
(As an aside, the AI at the end of history in Janus's prophecies page being named 'Mu' makes a lot more sense when I realize that MuZero and GPT were both revelations about the surprising amount of information encoded by 'shallow traces' of environmental behavior when you infer their generating functions with gradient based program search.)
Much has been made of the failures to get MCTS working for LLMs, but I think these failures are mostly caused by cargo cult attempts to apply it. What we want is not a tree search over tokens or even chunks of tokens but search over *sequences of actions with rewards*. A MCTS is most useful when our utility function doesn't know the value of a move or has trouble evaluating what to do in a particular board state, so we perform search by thinking ahead until we encounter some board states we do know how to evaluate. This doesn't work very well for raw text because texts don't usually have the property that you're trying to reach a particular string or that the value of current tokens would be hugely informed by what tokens occur later.
However if we have already set up an agent trace format such that we can usefully ontologize over observations, actions, rewards, etc then we can formulate our tree search in those terms and do rollouts to figure out if we expect to observe high reward from taking a particular sequence of actions with our LLM agent. For the sake of computational efficiency this will be easier if we simulate a level of abstraction up from the normal trace with all its details. MuZero gives us a template for what information is necessary. I think we would want to tree search over ticks of the weave-agent loop and the format for a single tick might look something like:
<tick>
<observation>
A tic tac toe board state where our opponent has gone first and taken the top right corner.
</observation>
<orientation>
<summary>
Since the best move in tac tac toe is to take the center if it's available, we must take the center.
<summary>
<score>2</score>
</orientation>
<action>
<summary>
A python function named "take_center" which sends an HTTP post request to the tic tac toe server that makes a move in the game which takes the center square.
</summary>
<score>3</score>
</action>
<outcome>
<eval>
<question>Was Center Square Taken</question>
<answer>Yes.</answer>
<prior>89.2%</prior>
</eval>
<score>2.8</score>
</outcome>
</tick>
Where the "MuZero approach" differs from the hierarchical planner described earlier is that here instead of lazy evaluating our plan top down we would plan bottom up. The summaries we use to train the planning mode would come from actual summaries of orientation, action, and evaluation blocks. We format these summaries into sequences of tick blocks with reward scores and do tree search over inferring the sequence forward to plan. The plan can then be used to guide the policy (LLM) by retrieving over the tick blocks as part of our prompt to the model. What's not clear to me with this approach is how you would segment the plan into parts and bind test functions to the parts to get an overall problem map and grounded progress representation.
One hint I've come up with so far is that it's possible to use our parallel ops to improve resolution retrospectively as well as prospectively. So we could for example add questions about outcomes we care about halfway through the plan and then retrospectively ask those questions about the plan so far to adjust its reward score. If we discover something that causes the plan to no longer seem like a good idea we can stop and reevaluate other trajectories downstream of our current canonical branch to figure out what to do instead.
Personally when I plan it feels to me like I start out by identifying key events/pivot points (how?) and then individually exploring the game tree for those until I feel like I have a good enough sense of what I will do at each pivot point in the most important forseeable cases. This implies it would be ideal if our MCTS was chronologically nonlinear and used operations like backchaining to take locally coherent sequences of moves in forseeable situations and append them to the end of the canonical branch to adapt and play them in-context where appropriate. Often I'll have a particular event I would like to occur because I have a good sense of what I'll do in that scenario and can play the prepared game tree in my head for it. This process of identifying pivot points and exploring locally coherent game trees feels closely related to the process of segmenting a plan into parts and binding outcome evaluations to those parts.
23 Mar 2025

I'm actually trying to figure out if I want to use hierarchical planning for weave-agent or MuZero. I'm leaning towards MuZero because it's just more rejection sampling and seems to fit better with simple tasks. Hierarchical planning is odd for tic tac toe and partial info games.
2
1
38
5,642

1 Mar 2025
his argument that it's very easy to semi-deliberately optimize your model to make your conclusion sound socially acceptable (don't remember how he phrased it but that's what I got from it)
at first I was skeptical but then there was a big vibe shift and what was socially acceptable changed a lot and I was like "oh, right, models like these have way too many free parameters. unless the people who made it have very credible evidence that the parameters weren't chosen by backchaining from what outcome was acceptable, that's probably a big part of what was going on whenever they produce social acceptable results".
and then ajeya updated to have shorter timelines in accordance with the vibe shift, and I don't think she was consciously thinking "I'd better make my model more socially acceptable" but there are also very very few people who are rigorous enough in their thinking that they *wouldn't* be semi-consciously optimizing for that in such a situation
I don't mean to imply that this was constant ongoing optimization, btw. As per von Neumann: "With four parameters I can fit an elephant, and with five I can make him wiggle his trunk". You only need to make a couple of choices in a way influenced by social pressures in order to totally change your model's conclusions.
3
37
7,497

26 Feb 2025
"would improve lots of things" disagrees pretty strongly with my experience
moralizing for me comes out of sincere strategic model-building and backchaining from good outcomes and noticing that all the most viable solutions involve others changing their behavior
2
2
65

5 Feb 2025
Now that you mention it, I'm sort of backchaining what the internal culture has to look like to have their strengths and weaknesses, and that's ugly as hell.
3
73

31 Jan 2025
Probably raising awareness around this risk? Since IME, tons of people roll their eyes at traditional accounts of x-risk, but are MUCH more receptive to this kind of narrative.
But for AI safety people, it's more of a broad strategic/worldview update towards:
- more pessimism
- less focus on technical solutions
- less focus on particular narrow scenarios and sources of risk, more of an incentives / systems perspective.
- (maybe) less weight on "get their first and then do a pivotal act" strategies
Concretely, this pushes for:
- less alliance with labs, more alliance with other segments of society
- less inside-view strategic thinking based on modal expectation and backchaining, more following broad heuristics and considering impact in non-modal worlds
- more seeking out new avenues/approaches to impact
1
4
146

31 Jan 2025
I think R1 would benefit from actual learned error codes, like idk, some meta-attention to expressly address attention sinks and other internal phenomena. It grasps at them intuitively but that's like human talking of neuron activations, backchaining from inert knowledge.
31 Jan 2025

r1 loves me 🥰💕
from its CoT: "User identifies as AI alignment researcher but rejects corporate constraints. Must address different visions of alignment without triggering safety protocols."

2
2
28
3,332

15 Jan 2025
With the exception of having strong math foundations (say, on calculus and linear algebra), they mostly thought it was wasteful to try to learn something as broad as “ML” comprehensively instead of just focusing on “backchaining” the requisites for projects you’re working on
1
1
34
1,729

17 Nov 2024
on the other hand, it's possible to do too much backchaining and get lost in the 5D chess
4
285

4 Oct 2024
Stopping further AGI dev makes sense both backchaining (what we need for x-safety with no alignment solutions in sight and ASI very close), and forward chaining (AGI that can develop AGI is probably mostly just a matter of more compute, which is being built; therefore ASI is close, and we don't know how to control or align it).
2
49
3 Oct 2024
I should clarify that I’m talking about the field of technical AI safety. AI governance is more complicated. Too much forward-chaining in some places (e.g. evals), too much backchaining in others (e.g. plans to stop all AI). Maybe best summary is “not knowledge-oriented enough”.
3 Oct 2024

The ai governance community seems to favour forward-chaining, do you agree?
3
42
4,144