
Jun 12
If you run a SaaS, here's what your roadmap looks like in 2026:
Q1: Build Salesforce integration.
Q2: Build HubSpot integration.
Q3: Customer wants Pipedrive. Engineer cries.
Q4: Maintenance.
Or: embed ByteChef Agents. Your users build their own.
Ship integrations as a feature, not a backlog.
Open-source. Monday.

17
Jun 11
The business model? We make money when teams want hosted ByteChef, embed licensing for SaaS companies, and enterprise support.
The product is free. The work around the product is what we sell.
Same model that worked for Postgres, Grafana, and Elastic.
1
16
Jun 11
ByteChef Agents flips that.
→ Self-host on your own infra
→ Bring your own LLM keys
→ Your data never leaves your network
→ Apache 2.0 - fork it, audit it, change it
The agent works for you, not for us.
1
5
Jun 11
Here's the part nobody tells you about open-sourcing your hardest feature:
You spend 6 months on it.
Someone forks it 6 hours after launch.
A competitor ships a "ByteChef-compatible" version 6 weeks later.
That's the price.
1
2
Jun 11
We're shipping AI Agents in ByteChef next Monday.
All of it - the builder, the tools layer, the memory - is open-source. Apache 2.0.
That decision cost us something real. Here's what, and why we made it anyway →
1
6
Jun 11
If you run a SaaS, here's what your roadmap looks like in 2026:
Q1: Build Salesforce integration.
Q2: Build HubSpot integration.
Q3: Customer wants Pipedrive. Engineer cries.
Q4: Maintenance.
Or: embed ByteChef Agents. Your users build their own.
Ship integrations as a feature, not a backlog.
Open-source. Monday.

1
48
Jun 10
How we built memory RAG into ByteChef agents without making you wire up:
→ A vector DB you have to host
→ A chunker you have to tune
→ A re-ranker you have to pay for
→ A sync job you have to maintain
Drop in a folder. The agent uses it. That's the API.
Open-source. Monday.

9

Jun 4
天下大事谁早知?关注了我你早知。
请接收今日信息差:
今天 AI 先从公开源里扫了 115 条线索,我按“能不能讲清楚、有没有原始链接、适不适合中文读者”这三个标准,人工精选出 5 条。下面直接进正文:它是什么,解决什么问题,怎么工作,为什么值得看,证据和边界分别在哪里。
项目一:Second Brain:给本机文件和工作流加一层私人 AI 运行时
Second Brain 是一个本地优先的 AI 运行时(Local-first AI Runtime)。它通过索引本地文件、维护持久记忆、自动化工作流与调度任务,并利用大语言模型(LLM)进行推理和生成,旨在为用户在个人电脑上构建一个私有的、可编程的“第二大脑”或“个人操作员”。
它解决的是:个人信息和知识的分散、检索低效以及重复性劳动。传统工具(如笔记软件、简单聊天机器人)无法将本地文件、网络信息、定时任务和对话交互有机整合。Second Brain 通过将文件、记忆、自动化和LLM能力统合在一个私有的、可扩展的运行时中,旨在实现对个人数字资产的主动管理、智能检索和自动化操作。
换成人话说,它想解决的是“资料都在电脑里,但真正要用的时候找不到、串不起来、也不能自动帮你做事”。如果你有很多本地文档、代码仓库、PDF、聊天记录或工作素材,普通搜索只能找关键词,普通聊天机器人又看不到你的完整上下文;这类本地 AI 运行时的帮助在于,把资料检索、长期记忆、任务提醒和工具调用放进同一个私人环境里,让 AI 不只是回答问题,而是能围绕你的文件和日常工作持续行动。
它的工作方式:其核心是一个受状态机驱动的对话运行时,管理多轮交互的权限、阶段和生命周期。它能自动索引用户指定的本地文件夹,支持文本、代码、PDF、音视频等多种格式的解析、嵌入和混合搜索。系统具备事件驱动和定时任务能力,可通过预设的前端(如终端、Telegram)接收指令,并允许通过“沙盒”机制在运行时动态添加和测试新工具、命令和前端界面。
实际工作链路可以理解成三步:先把本地文件变成可检索的上下文,再用运行时管理对话、权限、工具和任务,最后通过终端、Telegram 或插件把结果推回你的工作流。它不是单次把文件丢给模型,而是持续维护索引和记忆;当你问问题、安排任务或调用工具时,系统会在本地材料里检索相关内容,再决定要回答、执行命令、跑定时任务,还是通过插件扩展新能力。
为什么值得放进观察名单:1. 架构创新:其以状态机为核心的会话层设计,将对话、命令、审批和工具调用统一为可管理的“回合流”,是区别于简单聊天封装的关键。2. 本地优先与隐私:强调在用户本地机器上运行和处理数据,符合对数据隐私和安全日益增长的需求。3. 可扩展性:内置的插件系统和“沙盒”实时加载机制,赋予其很强的定制和扩展潜力。这些特点使其不仅仅是一个文件问答工具,而是一个具有操作系统雏形的个人AI基础设施。
中文读者可以怎么理解:对中文读者而言,可以将其理解为一个“增强版的本地知识库与个人自动化助手”。它解决了将散落在电脑各处的文档、笔记、代码进行智能整合与利用的问题。其“本地运行”和“隐私安全”的特性,在关注数据主权的背景下具有吸引力。同时,它提供了将LLM能力“场景化落地”的一个参考架构,即如何围绕本地文件系统和特定工作流(如Telegram通知、定时任务)构建实用的AI应用,而不仅仅是API调用。
现在能看到的证据:项目在GitHub上获得550个星标:GitHub API数据:"stargazers_count":550;项目最近更新时间(代码推送)为2026年6月3日:GitHub API数据:"pushed_at":"2026-06-03T16:50:51Z";项目自述为‘一个本地优先的AI运行时’,并列举了索引文件、持久记忆、任务调度、Telegram通知、插件扩展等核心功能:README.md 中明确描述:'Second Brain is a local-first AI runtime for your machine. It indexes your files, remembers durable context... schedules cron jobs, sends Telegram updates, and lets agents extend the system while it is running.';核心架构包含状态机、运行时、插件系统等模块,并支持REPL和Telegram前端:README.md 的‘Core Architecture’部分详细列出了`state_machine/`、`runtime/`、`plugins/`等模块及其职责,并说明‘Built-in frontends: repl... telegram’
不能说满的地方:项目具体的独立用户数或活跃用户规模;核心团队(henrydaum)的背景和持续维护承诺;在非Windows/macOS(如Linux)上OCR等特定功能的完整支持情况;是否有商业化计划或企业级支持
原始链接:github.com/henrydaum/second-…
来源:GitHub Search
项目二:git-machete
git-machete 是一个 Git 工作流自动化工具。它通过一个名为 `.git/machete` 的文本文件来可视化管理分支之间的层级关系,提供鸟瞰图,旨在简化多分支仓库中的 rebase、merge、push、pull 等操作,帮助开发者维护清晰、小型的 PR。
它解决的是:在拥有多个分支(如 master/develop、功能分支、队友的分支)的 Git 仓库中,手动执行 rebase、合并、推送和拉取操作容易出错且繁琐。维护一系列小型、专注的 PR 需要精确管理分支关系,手动操作成本高且容易混乱。
它真正帮的是经常同时维护多个分支的人。比如一个功能被拆成三四个小 PR,底层分支一改,上面的分支就要跟着 rebase;队友又在另一个分支上推进,手动判断谁依赖谁、先合哪个、哪个已经落后,很容易乱。git-machete 的价值不是替代 Git,而是把这棵分支关系画出来并声明化,让你知道每个分支的位置、同步状态和下一步该做什么。
它的工作方式:其核心是一个 `.git/machete` 文件,用于声明式地定义分支树的父子关系。通过 `git machete discover` 命令可以启发式地推断并生成分支布局。`git machete status` 命令以带颜色的图形化视图展示各分支与其父分支的同步状态(同步/未同步/已合并)。`git machete traverse` 命令可以半自动地遍历所有分支,依次执行必要的 rebase、push、pull 操作来同步它们。它还深度集成了 GitHub 和 GitLab,支持从 PR/MR 链中检出分支以及创建 PR/MR。
它的核心不是复杂 UI,而是 `.git/machete` 这个分支拓扑文件。你可以把它看成一张“PR 关系图”:哪个分支基于哪个分支,哪个分支已经合并,哪个分支需要同步,都通过命令行状态展示出来。`discover` 帮你推断现有分支布局,`status` 告诉你每条分支和父分支的关系,`traverse` 则按顺序帮你走完 rebase、pull、push 这类重复动作。对团队来说,这能把隐性的分支依赖变成显性的操作流程。
为什么值得放进观察名单:该项目由 VirtusLab 组织维护,在 GitHub 上拥有超过 1100 颗星,且持续活跃更新(最新版本 v3.42.0 发布于 2026 年 6 月)。它精准地切入了复杂 Git 分支管理的痛点,提供了从可视化到自动化的一体化解决方案。项目文档齐全,并提供了 IntelliJ 平台插件及对多种包管理器的支持,显示出良好的生态兼容性。最新版本还增加了对 AI 编程助手(如 Cursor, Copilot)的技能支持,显示了其对前沿开发工作流的关注。
中文读者可以怎么理解:对于中文技术读者,可以将其理解为一个专注于“分支管理”和“PR 链自动化”的 Git 增强工具。相比于 Git flow 或 GitKraken 等图形化工具,它更偏向于命令行下的轻量级、自动化管理。其价值在于将复杂的“分支拓扑”和“同步操作”脚本化、声明化,特别适合追求开发效率、喜欢 CLI 工作流且正在处理复杂功能拆分的工程师或团队。
现在能看到的证据:项目是用于简化 Git 工作流的工具:README 第一句:"git-machete is a robust tool that simplifies your git workflows.";在 GitHub 上拥有 1116 个 star,由组织 VirtusLab 维护:API 数据显示 "stargazers_count": 1116, "owner" 类型为 "Organization",登录名为 "VirtusLab";项目非常活跃,最后一次推送更新时间为 2026 年 6 月 3 日:API 数据中 "pushed_at": "2026-06-03T16:28:51Z";核心功能包括分支布局发现、状态查看和遍历同步:Quick start 部分详细描述了 `git machete discover`、`git machete status`、`git machete traverse` 等核心命令的用法和效果
不能说满的地方:项目的实际用户规模和活跃度(如每日下载量、典型使用场景);项目维护团队的详细背景和投入资源;与其他类似工具(如 git-branchless, gs)的对比和优劣;是否有商业化或企业支持计划
原始链接:github.com/VirtusLab/git-mac…
来源:GitHub Search
项目三:ByteChef:把 AI 智能体编排和传统工作流自动化合到一个平台
ByteChef是一个开源平台,统一了AI代理编排和工作流自动化。它将AI代理和自动化工作流集成到单一平台,提供可视化编辑器、拖放式AI代理组件、多种连接器和流控制功能,旨在简化企业级自动化和AI应用开发。
它解决的是:当前,企业和开发者在构建AI代理和自动化工作流时,常需依赖多个独立工具,导致系统集成复杂、维护成本高、数据不一致。ByteChef通过提供一个统一平台,整合代理编排和工作流自动化,简化了开发和管理流程,降低了技术栈的碎片化。
它解决的不是“有没有 AI agent”这个表层问题,而是企业真的要把 AI 放进业务流程时的碎片化问题。很多团队一边用自动化平台接 CRM、邮件、工单和数据库,一边又单独搭 agent、RAG、模型网关和安全规则,最后审计、权限、日志、回滚都散在不同地方。ByteChef 的帮助在于把这些工作流和 agent 工具统一到一层,让 AI 可以作为流程步骤运行,而不是游离在业务系统外面。
它的工作方式:ByteChef的核心是一个可视化工作流编辑器,允许用户拖放构建工作流。内置AI代理组件,可配置多种LLM模型、工具、知识库和防护栏,运行完整代理循环。支持多种触发器(如webhook、调度、应用事件)和流控制(条件、循环、并行等)。通过180 连接器集成第三方服务,每个连接器也可作为AI代理工具或MCP工具。平台支持多语言代码(Java、JS、Python、Ruby)和持久化执行,提供Git-native工作流和工作流即API功能。
它的工作方式更像“把 AI agent 放进可视化流程编排器”。用户先用触发器接入一个事件,比如 webhook、定时任务、表单提交或工单更新;再把普通连接器、代码节点、条件分支、循环和 AI agent 节点拖到流程里。agent 节点可以拿模型、工具、记忆、知识库和 guardrails;普通连接器又能变成 agent 可调用的工具。这样一个流程既能跑传统自动化,也能在关键步骤让模型判断、检索、生成或调用外部系统。
为什么值得放进观察名单:ByteChef值得关注,因为它提供了一个开源核心平台,统一AI代理和工作流自动化,这在当前工具碎片化的市场中具有创新性。项目有770 GitHub stars和持续更新(最近版本v0.27.0于2026年发布),显示社区活跃。其企业版功能如嵌入式iPaaS和AI Copilot扩展了应用场景,适合企业级部署。此外,支持MCP和多种连接器增强了集成能力。
中文读者可以怎么理解:对于中文读者,ByteChef可以被视为一个国际化的开源自动化平台,虽然没有专门的中文支持,但其功能如多语言代码支持和广泛连接器库,可能适用于全球企业。中文开发者可以关注其在企业自动化和AI集成领域的潜力,以及开源社区的参与机会。
现在能看到的证据:项目是开源平台,统一AI代理编排和工作流自动化:从README描述:'The open-source platform that unifies AI agent orchestration and workflow automation — autonomy and precision in one platform.';有770 GitHub stars:API响应中stargazers_count为770;最近更新于2026-06-03:updated_at为2026-06-03T14:00:44Z;支持多种触发器和流控制:从README:'Triggers — webhook · schedule · polling · app-event · manual · form'和'Flow controls — condition · switch · loop · each · parallel · branch · sub-workflows'
不能说满的地方:市场竞争力分析;用户实际部署案例和反馈;性能基准测试数据;中文文档或本地化支持细节
原始链接:github.com/bytechefhq/bytech…
来源:GitHub Search
项目四:Docker Sandboxes (sbx)
Docker推出的一个工具/功能,它通过创建一个隔离的微型虚拟机(microVM)环境,让AI编程助手(如Claude Code, Cursor等)在其中安全地执行代码、操作文件和访问网络,从而将其与开发者的主机系统隔离开来,防止恶意或意外操作对本机造成破坏。
它解决的是:AI编程助手可以直接在开发者的电脑上运行命令、修改文件、从不受信任的来源下载内容,这带来了严重的安全风险。开发者需要一种方式来安全地运行这些代理,隔离它们与网络、文件和主机系统的交互,以防止系统被破坏或数据泄露。
这条对正在用 Claude Code、Codex、Cursor 这类编程 agent 的人很实际。agent 能跑命令、改文件、装依赖,也可能误删文件、读取不该读的密钥、从外部拉有问题的脚本,甚至在你没注意时把网络请求打出去。Docker Sandboxes 要解决的是“让 agent 帮忙干活,但不要让它裸奔在主机上”这个问题,让风险先被隔离在可控环境里。
它的工作方式:它提供一个专用的CLI工具(sbx)。用户首先安装CLI并登录,然后可以设置全局或项目级别的网络访问策略(如Open、Balanced、Locked Down)。接着,为AI代理注入模型提供商的认证凭证(实际凭证保留在主机,沙盒内只有象征值)。最后,在项目目录中运行`sbx run [provider]`命令,即可在预配置的隔离沙盒中启动对应的AI代理。沙盒会强制执行已设定的网络策略。
使用方式可以拆成四步:先安装 `sbx`,再给项目设置网络策略,然后把模型供应商凭证映射进去,最后用 `sbx run` 启动对应的 AI 编程工具。关键点是凭证和主机文件不会原样暴露给沙盒,网络访问也可以按 Open、Balanced、Locked Down 这类策略控制。也就是说,agent 仍然能在项目里工作,但它看到的文件、能访问的网络、能做的系统操作都被 Docker 的隔离层限制住。
为什么值得放进观察名单:它精准地切入了AI编程助手普及后带来的一个新兴且关键的安全痛点。提供了一种标准化、基于容器的隔离方案,具备细粒度的网络策略控制能力,是保障开发环境安全的重要实践。Docker的品牌背书和其与主流AI开发工具的集成,使其有可能成为开发者工具链中的一个标准组件。
中文读者可以怎么理解:对于中文技术读者,可以将其理解为‘给AI编程助手戴上的一个安全头盔’或‘一个专属的沙盒训练场’。在开发流程中,直接运行AI生成的代码存在不确定性风险,此工具通过系统级的隔离来对冲这种风险,是DevSecOps理念在AI辅助开发场景下的具体落地案例。文中提供了从安装到使用的完整实操路径,具有较高的参考价值。
现在能看到的证据:AI代理存在直接运行命令、修改文件、下载文件带来的安全风险:材料开篇即指出:‘AI agents can run commands, modify files, and download files from untrusted sources directly on a developer machine, which creates a major security risk.’;Docker Sandboxes通过创建隔离的microVM环境来运行AI代理:材料中说明:‘Docker Sandboxes solves this problem by creating isolated microVM environments where AI agents run safely...’;支持多种AI编程代理,如Claude Code、Codex、Cursor等:材料明确列出:‘Docker Sandboxes support Claude Code, Codex, Cursor, etc.’;提供可配置的网络策略控制(如Open, Balanced, Locked Down):材料中描述了设置网络策略的命令`sbx policy reset`,并解释了三种策略的区别
不能说满的地方:该功能/工具的定价模型或是否完全开源,材料未提及;其相对于其他方案(如虚拟机、单独的容器)的性能开销和启动速度的具体数据;官方文档中关于自定义镜像、持久化存储、复杂项目依赖管理的详细说明,材料仅为入门教程;长期维护计划、与未来新AI代理的集成策略等产品路线图信息
原始链接:dev.to/pradumnasaraf/run-ai-…
来源:dev.to
项目五:Cast
Cast是一个开源的自托管框架,专为多用户和多代理系统设计,用于管理Claude代理的访问控制和协调。它允许团队或家庭共享相同的代理设置,通过配置文件而非提示来定义权限,确保安全性和可维护性,运行在Mac Mini等设备上,采用MIT许可证。
它解决的是:当前AI代理框架通常假设一个开发者对一个代理,当多人共享时,身份验证、访问控制和代理协调功能往往被临时添加,导致架构脆弱、安全性低。Cast解决了在提示中硬编码权限规则易被模型忽略或覆盖的痛点,提供内置的配置驱动访问控制。
Cast 解决的是多人共享 agent 时最容易被忽视的权限问题。一个人自己用 Claude agent,可以靠口头约束或提示词约束;但团队、家庭或组织里多人共用时,谁能访问哪个 agent、能不能调用某个工具、能不能看到某些文件,就不能再写在提示词里赌模型听话。它的价值在于把权限规则从 prompt 里拿出来,变成系统配置。
它的工作方式:Cast作为服务器运行,代理以文件夹形式存储在本地目录中,通过Web仪表板进行配置和管理。它使用配置文件定义用户权限和代理路由,模型本身不接触这些规则,从而防止泄露或覆盖。支持与Claude Code集成,提供如/cast-build等技能来构建代理。需要容器运行时(如Docker或Apple Container)和Node.js环境。
它把 agent 当成可管理的本地资源:每个 agent 放在本地目录里,Cast 作为服务器负责路由、权限和 Web 管理界面。用户和 agent 的访问关系写在配置里,而不是塞进模型提示词;模型本身看不到这些访问规则,也就更难通过提示注入绕开。它还可以和 Claude Code 这类工具配合,让开发者用技能或命令创建、配置和调用 agent,但真正的权限边界由 Cast 这一层统一管。
为什么值得放进观察名单:Cast作为开源框架,提供了优雅的解决方案来管理AI代理的权限和协调,填补了现有框架的空白。尽管处于开发者alpha阶段,但其设计理念(如配置驱动访问控制)和自托管特性使其具有潜力,可能成为多代理系统的基础工具,值得技术社区持续观察。
中文读者可以怎么理解:对于中文读者,Cast展示了如何将AI代理的权限管理从提示工程转向配置驱动,提高安全性和可维护性。它适合国内开发者和团队探索多代理协作,尤其是使用Claude的场景,开源和自托管特性也符合对数据自主和可控的需求,可作为技术选型参考。
现在能看到的证据:Cast是开源的多用户Claude代理框架:从README: 'Cast is an open-source harness for multi-user, multi-agent systems.';访问控制通过配置而非提示实现:README中示例: 'The access rule is config. The model never sees it, so it cannot leak or override it.';项目星标11,叉1,表明有限的社区关注:GitHub API数据: 'stargazers_count':11, 'forks_count':1;没有发布版本,处于早期阶段:GitHub releases API返回空数组: []
不能说满的地方:是否有实际用户案例或部署经验;性能和高负载下的表现;安全性和隐私保护的具体措施;与其它代理框架的对比数据
原始链接:github.com/yaodub/cast
来源:Mastodon
边界:这只是信息整理,不是收益承诺;原始链接可查,不等于真实体验已经完全验证。
#信息差 #AI工具 #外网趋势 #前沿科技 #开源项目 #产品观察 #AustinFCui #FrontierRadar

1
2
3,832
May 20
This is the problem ByteChef Agents is built to solve.
180 tools out of the box. Multi-model. Memory RAG native. Self-host. Embeddable.
Shipping next Tuesday, open-source.
If you want the link the moment it goes live — reply "in" and I'll DM you.
1
1
22

23 Dec 2025
As the year comes to an end, we want to say thank you to everyone who made this year special here at Bytechef!
A huge thanks to our partners, clients, community, and our dedicated team.
Merry Christmas and happy holidays with more automation and less manual work! 🎁🎄

1
2
18
22 Dec 2025
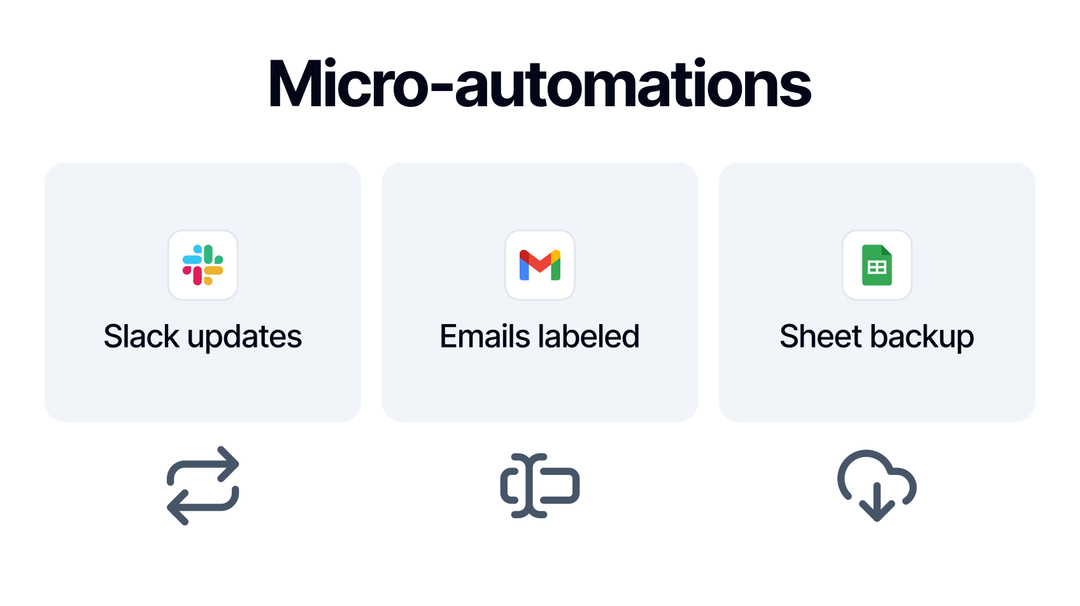
🧩 You don’t need huge workflows to feel the power of automation. Sometimes the smallest automations are the ones that make you go, “Wait… why didn’t I do this sooner 🤔”
#ByteChef #WorkflowAutomation #MicroAutomation #Automation #LowCode #Productivity
2
4
357
25 Nov 2025
Your marketing tools shouldn’t feel like a juggling act. 🤹♂️ Ads here. Email lists there. Surveys… somewhere? 😵💫
With ByteChef, everything finally connects:
HubSpot → Mailchimp → Google Ads → Social → CRM → Insights.
Your marketing doesn’t sleep - and neither should your automations. 🌙🤖
Grow faster with a stack that runs itself. 🚀
#ByteChef #Automation #WorkflowAutomation #MarketingAutomation #DigitalMarketing

1
2
35
3 Nov 2025
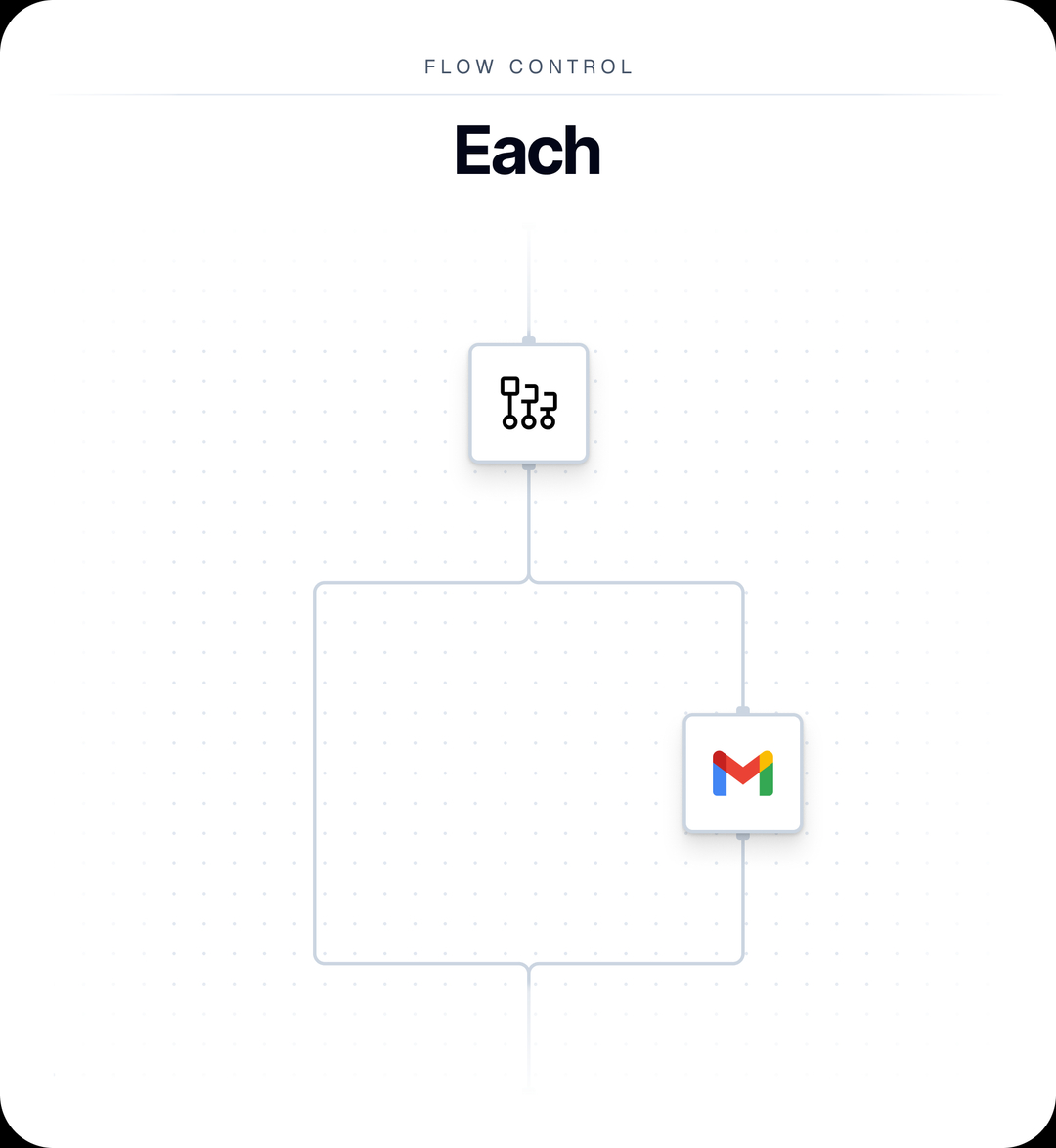
Introducing the Each flow control - your automation loop for handling repeating work at scale.
Got a list of data? Each handles it item by item — ideal for batch edits, transformations, or bulk operations. No repetition. No manual steps. Just clean automation. ⚡️
Whether you're processing emails, rows, or records, Each keeps your workflow organized, scalable, and perfectly consistent from start to finish.
🔥 Stay tuned for more Flow Controls.
#ByteChef #ByteChefTip #Automation #WorkflowAutomation #logic #SaaS #productivity #batchprocessing
1
3
20
13 Oct 2024
That sounds like a great idea! If you're exploring options, you might also want to look into ByteChef for flexible integration and workflow automation.
github.com/bytechefhq/bytech…
2
18

26 Sep 2024
GM, BPopers!
Did you know that the character Remy in Ratatouille was inspired by the director's love for cooking?🐭 The animators even studied how real chefs work to make the cooking scenes look super realistic!
Anyway, ByteChef is also cooking up something new! Stay tuned!👩🍳✨

7
154

14 Apr 2024
3. ByteChef
它可以帮助自动化需要独立应用程序之间交互的日常工作,例如将数据从电子商务网站自动转移到CRM系统的过程。
🔗 github.com/bytechefhq/bytech… | @bytechefhq
1
894

3. ByteChef
It helps automate daily routines that require interaction between independent applications. For example, automating the process of transferring data from an e-commerce site to a CRM system.
🔗 github.com/bytechefhq/bytech… | @bytechefhq
1
28
5,854

19 Mar 2015
80% Off on Premium #sharedhosting with #cpanel on ByteChef #webhosting - Limited time #offer bytechef.com/shared-hosting.…

1