
Jan 15
Hi @Teknium,
I was thrilled to read your post's description. This sounds like the perfect role for me.
Since you specifically asked for OSS contributions and GitHub links, I'll lead with those. I've poured my energy into Hugging Face's ecosystem, specifically post training optimizations and fixes that align spot on with your focus, plus other key projects. Here's the rundown:
Hugging Face Transformers (my entry point. I tackled bugs, utils, and coverage boosts):
- Fixed PaliGemma’s pad token unmasking during training: github.com/huggingface/trans…
- Resolved audio classification bugs, including doc mismatches and runtime errors with top_k=None, plus test isolation fixes: github.com/huggingface/trans…
- Made output_dir optional in TrainingArguments: github.com/huggingface/trans…
- Added a reload utility for smoother dev workflows: github.com/huggingface/trans…
Unsloth Optimization Challenges (I solved four tough ones and wrote them up on Medium):
- Triton kernel for NF4 double dequantization to FP16/BF16 on T4 GPUs: medium.com/@indosambhav/unsl…
- QLoRA FSDP2 integration for Llama 3.1 8B multi GPU fine tuning: medium.com/@indosambhav/unsl…
- torch.compile without graph breaks for QLoRA in LLMs: medium.com/@indosambhav/unsl…
- VRAM efficient backprop via chunked logits and generalized Cut Cross Entropy: medium.com/@indosambhav/unsl…
Hugging Face PEFT (I've been contributing since October 2025, dropping impactful PRs on LoRA/DoRA/X LoRA enhancements. Fun fact: I'm the 3rd largest contributor there, right behind the maintainers, and #32 overall):
- Negative weights support in LoRA merging, useful for task arithmetic and adapter subtraction: github.com/huggingface/peft/…
- Embed_scale handling for DoRA, supporting scaled embeddings like Gemma3TextScaledWordEmbedding: github.com/huggingface/peft/…
- Embed_scale handling for X LoRA: github.com/huggingface/peft/…
- Scaled embeddings in TrainableTokensModel: github.com/huggingface/peft/…
- Ensure_weight_tying for trainable_token_indices, which is upcoming for merge: github.com/huggingface/peft/…
- 3 4x faster LoRA GA integration, also upcoming for merge: github.com/huggingface/peft/…
Hugging Face Diffusers (as an MVP):
- Submitted a fix for Qwen image encoding padding. The PR is up for review, so fingers crossed it merges soon: github.com/huggingface/diffu…
- MVP program shoutout: github.com/huggingface/diffu…
**Other Hugging Face Issues Raised** (red teaming OSS models, including OpenAI's on Kaggle):
- Cross tokenizer distillation failures in TRL's GKD/MiniLLM trainers: github.com/huggingface/trl/i…
- FA4 integration in Transformers: github.com/huggingface/trans…
Developer Tools & More :
- @pieces_for_developers: I'm the #3 contributor to pieces_cli_tool (github.com/pieces-app/cli-ag…) and #2 to Python OS SDK (github.com/pieces-app/pieces…).
- Swarms, a multi agent orchestration library and LangChain alternative, where I'm an active contributor.
- PECAn (Predictive Ecosystem Analyzer): I was a GSoC '24 mentee, working on downscaling ML outputs spatially and temporally, and I kept contributing post program.
I really enjoy making AI models faster and more practical. Whether that's fine tuning LLMs at ByteLearn, a role I got thanks to a Kaggle contest, or sharing what I learn through open source.
I'd love to chat when you have a moment. DM'ed you as well
7
991
Jan 10
Here is my version :
I've poured my energy into Hugging Face's ecosystem, specifically post training optimizations and fixes that align spot on with your focus, plus other key projects. Here's the rundown:
Hugging Face Transformers (my entry point. I tackled bugs, utils, and coverage boosts):
- Fixed PaliGemma’s pad token unmasking during training: github.com/huggingface/trans…
- Resolved audio classification bugs, including doc mismatches and runtime errors with top_k=None, plus test isolation fixes: github.com/huggingface/trans…
- Made output_dir optional in TrainingArguments: github.com/huggingface/trans…
- Added a reload utility for smoother dev workflows: github.com/huggingface/trans…
Unsloth Optimization Challenges (I solved four tough ones and wrote them up on Medium):
- Triton kernel for NF4 double dequantization to FP16/BF16 on T4 GPUs: medium.com/@indosambhav/unsl…
- QLoRA FSDP2 integration for Llama 3.1 8B multi GPU fine tuning: medium.com/@indosambhav/unsl…
- torch.compile without graph breaks for QLoRA in LLMs: medium.com/@indosambhav/unsl…
- VRAM efficient backprop via chunked logits and generalized Cut Cross Entropy: medium.com/@indosambhav/unsl…
Hugging Face PEFT (I've been contributing since October 2025, dropping impactful PRs on LoRA/DoRA/X LoRA enhancements. Fun fact: I'm the 3rd largest contributor there, right behind the maintainers, and #32 overall): - Negative weights support in LoRA merging, useful for task arithmetic and adapter subtraction: github.com/huggingface/peft/…
- Embed_scale handling for DoRA, supporting scaled embeddings like Gemma3TextScaledWordEmbedding: github.com/huggingface/peft/…
- Embed_scale handling for X LoRA: github.com/huggingface/peft/…
- Scaled embeddings in TrainableTokensModel: github.com/huggingface/peft/… Ensure_weight_tying for trainable_token_indices, which is upcoming for merge: github.com/huggingface/peft/…
- 3 4x faster LoRA GA integration, also upcoming for merge: github.com/huggingface/peft/…
Hugging Face Diffusers (as an MVP):
- Submitted a fix for Qwen image encoding padding. The PR is up for review, so fingers crossed it merges soon: github.com/huggingface/diffu…
- MVP program shoutout: github.com/huggingface/diffu…
Other Hugging Face Issues Raised (red teaming OSS models, including OpenAI's on Kaggle): - Cross tokenizer distillation failures in TRL's GKD/MiniLLM trainers: github.com/huggingface/trl/i…
- FA4 integration in Transformers: github.com/huggingface/trans…
Developer Tools & More :
- @getpieces : I'm the #3 contributor to pieces_cli_tool (github.com/pieces-app/cli-ag…) and #2 to Python OS SDK (github.com/pieces-app/pieces…).
- Swarms, a multi agent orchestration library and LangChain alternative, where I'm an active contributor.
- PECAn (Predictive Ecosystem Analyzer): I was a GSoC '24 mentee, working on downscaling ML outputs spatially and temporally, and I kept contributing post program.
I really enjoy making AI models faster and more practical. Whether that's fine tuning LLMs at ByteLearn, a role I got thanks to a Kaggle contest, or sharing what I learn through open source.
I'd love to chat when you have a moment.
1
19
1,676
23 Dec 2025
Hi @ClementDelangue ,
I was thrilled to read that you were hiring . Since you specifically asked for OSS contributions and GitHub links, I'll lead with those. I've poured my energy into Hugging Face's ecosystem, specifically post training optimizations and fixes that align spot on with your focus, plus other key projects. Here's the rundown:
Hugging Face Transformers (my entry point. I tackled bugs, utils, and coverage boosts):
- Fixed PaliGemma’s pad token unmasking during training: github.com/huggingface/trans…
- Resolved audio classification bugs, including doc mismatches and runtime errors with top_k=None, plus test isolation fixes: github.com/huggingface/trans…
- Made output_dir optional in TrainingArguments: github.com/huggingface/trans…
- Added a reload utility for smoother dev workflows: github.com/huggingface/trans…
Unsloth Optimization Challenges (I solved four tough ones and wrote them up on Medium):
- Triton kernel for NF4 double dequantization to FP16/BF16 on T4 GPUs: medium.com/@indosambhav/unsl…
- QLoRA FSDP2 integration for Llama 3.1 8B multi GPU fine tuning: medium.com/@indosambhav/unsl…
- torch.compile without graph breaks for QLoRA in LLMs: medium.com/@indosambhav/unsl…
- VRAM efficient backprop via chunked logits and generalized Cut Cross Entropy: medium.com/@indosambhav/unsl…
Hugging Face PEFT (I've been contributing since October 2025, dropping impactful PRs on LoRA/DoRA/X LoRA enhancements. Fun fact: I'm the 3rd largest contributor there, right behind the maintainers, and #32 overall): - Negative weights support in LoRA merging, useful for task arithmetic and adapter subtraction: github.com/huggingface/peft/…
- Embed_scale handling for DoRA, supporting scaled embeddings like Gemma3TextScaledWordEmbedding: github.com/huggingface/peft/…
- Embed_scale handling for X LoRA: github.com/huggingface/peft/…
- Scaled embeddings in TrainableTokensModel: github.com/huggingface/peft/… Ensure_weight_tying for trainable_token_indices, which is upcoming for merge: github.com/huggingface/peft/…
- 3 4x faster LoRA GA integration, also upcoming for merge: github.com/huggingface/peft/…
Hugging Face Diffusers (as an MVP):
- Submitted a fix for Qwen image encoding padding. The PR is up for review, so fingers crossed it merges soon: github.com/huggingface/diffu…
- MVP program shoutout: github.com/huggingface/diffu…
Other Hugging Face Issues Raised (red teaming OSS models, including OpenAI's on Kaggle): - Cross tokenizer distillation failures in TRL's GKD/MiniLLM trainers: github.com/huggingface/trl/i…
- FA4 integration in Transformers: github.com/huggingface/trans…
Developer Tools & More :
- @getpieces : I'm the #3 contributor to pieces_cli_tool (github.com/pieces-app/cli-ag…) and #2 to Python OS SDK (github.com/pieces-app/pieces…).
- Swarms, a multi agent orchestration library and LangChain alternative, where I'm an active contributor.
- PECAn (Predictive Ecosystem Analyzer): I was a GSoC '24 mentee, working on downscaling ML outputs spatially and temporally, and I kept contributing post program.
I really enjoy making AI models faster and more practical. Whether that's fine tuning LLMs at ByteLearn, a role I got thanks to a Kaggle contest, or sharing what I learn through open source.
I've DM'ed you as well and I'd love to chat when you have a moment.
6
307
10 Dec 2025
Hi @QGallouedec,
I was thrilled to read your post's description. This sounds like the perfect role for me.
Since you specifically asked for OSS contributions and GitHub links, I'll lead with those. I've poured my energy into Hugging Face's ecosystem, specifically post training optimizations and fixes that align spot on with your focus, plus other key projects. Here's the rundown:
Hugging Face Transformers (my entry point. I tackled bugs, utils, and coverage boosts):
- Fixed PaliGemma’s pad token unmasking during training: github.com/huggingface/trans…
- Resolved audio classification bugs, including doc mismatches and runtime errors with top_k=None, plus test isolation fixes: github.com/huggingface/trans…
- Made output_dir optional in TrainingArguments: github.com/huggingface/trans…
- Added a reload utility for smoother dev workflows: github.com/huggingface/trans…
Unsloth Optimization Challenges (I solved four tough ones and wrote them up on Medium):
- Triton kernel for NF4 double dequantization to FP16/BF16 on T4 GPUs: medium.com/@indosambhav/unsl…
- QLoRA FSDP2 integration for Llama 3.1 8B multi GPU fine tuning: medium.com/@indosambhav/unsl…
- torch.compile without graph breaks for QLoRA in LLMs: medium.com/@indosambhav/unsl…
- VRAM efficient backprop via chunked logits and generalized Cut Cross Entropy: medium.com/@indosambhav/unsl…
Hugging Face PEFT (I've been contributing since October 2025, dropping impactful PRs on LoRA/DoRA/X LoRA enhancements. Fun fact: I'm the 3rd largest contributor there, right behind the maintainers, and #32 overall):
- Negative weights support in LoRA merging, useful for task arithmetic and adapter subtraction: github.com/huggingface/peft/…
- Embed_scale handling for DoRA, supporting scaled embeddings like Gemma3TextScaledWordEmbedding: github.com/huggingface/peft/…
- Embed_scale handling for X LoRA: github.com/huggingface/peft/…
- Scaled embeddings in TrainableTokensModel: github.com/huggingface/peft/…
- Ensure_weight_tying for trainable_token_indices, which is upcoming for merge: github.com/huggingface/peft/…
- 3 4x faster LoRA GA integration, also upcoming for merge: github.com/huggingface/peft/…
Hugging Face Diffusers (as an MVP):
- Submitted a fix for Qwen image encoding padding. The PR is up for review, so fingers crossed it merges soon: github.com/huggingface/diffu…
- MVP program shoutout: github.com/huggingface/diffu…
**Other Hugging Face Issues Raised** (red teaming OSS models, including OpenAI's on Kaggle):
- Cross tokenizer distillation failures in TRL's GKD/MiniLLM trainers: github.com/huggingface/trl/i…
- FA4 integration in Transformers: github.com/huggingface/trans…
Developer Tools & More :
- @pieces_for_developers: I'm the #3 contributor to pieces_cli_tool (github.com/pieces-app/cli-ag…) and #2 to Python OS SDK (github.com/pieces-app/pieces…).
- Swarms, a multi agent orchestration library and LangChain alternative, where I'm an active contributor.
- PECAn (Predictive Ecosystem Analyzer): I was a GSoC '24 mentee, working on downscaling ML outputs spatially and temporally, and I kept contributing post program.
I really enjoy making AI models faster and more practical. Whether that's fine tuning LLMs at ByteLearn, a role I got thanks to a Kaggle contest, or sharing what I learn through open source.
I'd love to chat when you have a moment.
2
10
482

23 Jan 2025
There's an ongoing discourse on whether #AI is a boon or a bane in educational spaces. And while it'll certainly continue to be a point of contention, US-based Bytelearn is offering a niche learning advantage in this space--read all about it here: entrepreneur.com/en-ae/entre…
164

11 Sep 2024
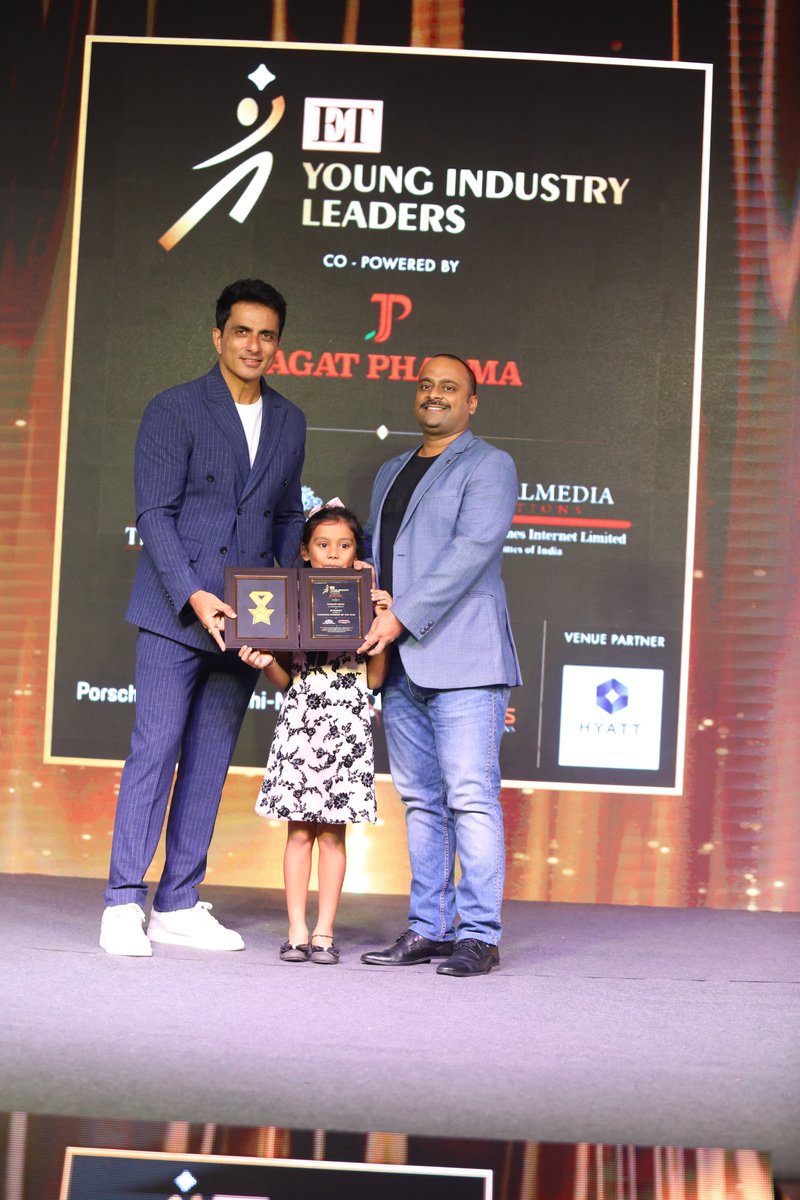
Thrilled to receive "ET Young Leaders Award" #ETYLA & #ByteLearn being recognized as an #EmergingStartup! 🎉💫 Grateful to my family, wife, cofounder @AdityaSinghal, team & mentors for their unwavering support! 🙏 #EdTech #Leadership #Innovation


2
4
110

10 May 2024
15 AI tools to help you learn efficiently:
1. Poised
2. TutorAI
3. Eightify
4. Vocalo
5. Socratic
6. ChatPDF
7. Fluently
8. Kippy AI
9. YouLearn
10. Langotalk
11. Mindgrasp
12. ByteLearn
13. elsaspeak
14. MathGPTPro
15. Learniverse AI
What tool did I miss?
21
18
84
8,238

4 Jul 2023
Bytelearn is hiring for Machine Learning Engineer Intern
Stipend: ₹ 25K - 27K per month
Location: Remote
Apply here: cuvette.tech/app/public/inte…
#jobs #hiring
6
19
3,009

8 Jun 2023
Applied for Front-end Intern role at bytelearn.
Got shortlisted.
Got the assignment.
Submitted it.
Waiting for their response.
👍
1
99

30 May 2023
Remote Frontend Internship #hiring 🚨
Bytelearn is hiring Frontend Developers🚩
Stipend ✨: Rs 25K / month
Eligible: 2026, 2025, 2024, 2023, 2022
Skills: HTML, CSS, Javascript
Like & comment "Interview" for better reach 🚀
Link: cuvette.tech/app/public/inte…
#tech #frontend
21
46
230
29,860

29 May 2023
Remote Internship Alert! 🚨
Bytelearn Pvt Ltd is hiring “Frontend Developer Interns”
Link: bit.ly/remote-intern-ship
Stipend: Rs. 20K - 25K / month
Eligible: 2026, 2025, 2024, 2023, 2022
Skills: HTML, CSS, Javascript
#Frontend #internship #opportunity
3
283

28 May 2023
Remote Internship Alert! 🚨
Bytelearn Pvt Ltd is hiring “Frontend Developer Interns”
Stipend: Rs. 20K - 25K / month
Eligible: 2026, 2025, 2024, 2023, 2022
Skills: HTML, CSS, Javascript
Comment “Interested” & I’ll DM you the link.
#tech #frontend #Web3 #Engineering
500
66
620
86,583
25 May 2023
Bytelearn is hiring for multiple intern roles
Stipend: 15k-30k per month
Location: Remote
Apply here for Machine Learning Engineer Intern: cuvette.tech/app/public/inte…
Apply here for Frontend Developer Intern:
cuvette.tech/app/public/inte…
#intern #hiring
2
19
72
8,785

2. Machine Learning Engineer Internship Bytelearn | Work From Home
Batch : 2023
Stipend Per Month : ₹ 25K - 30K
Apply:lnkd.in/dyFsdfnF
1
2
52

28 Mar 2023
Working on One-Step Equations? Try a free ByteLearn lesson plan on One-Step Equations. Includes worksheet, quizzes, practice problems and more.
hubs.la/Q01H_k0B0
#maths #middleschool #6thgrade
2
30
27 Mar 2023
At #ByteLearn we understand that not all students learn at the same pace. That's why we offer scaffolded #math lessons to help students build a strong foundation.
#maths
1
45
23 Mar 2023
Math doesn't have to be scary! #ByteLearn is dedicated to making math accessible and enjoyable for all middle school students.
#maths
1
35

20 Mar 2023
Great to hear that Bytelearn is making an impact at #ATOMIC2023 Math conference! It's exciting to see companies like yours innovating and changing the way students learn and understand Math. Keep up the good work! #EdTech #MathEducation
2
72

20 Mar 2023
Bytelearn is at #ATOMIC2023 Math conference.
We are changing the way students learn and understand #Math


1
2
6
510