


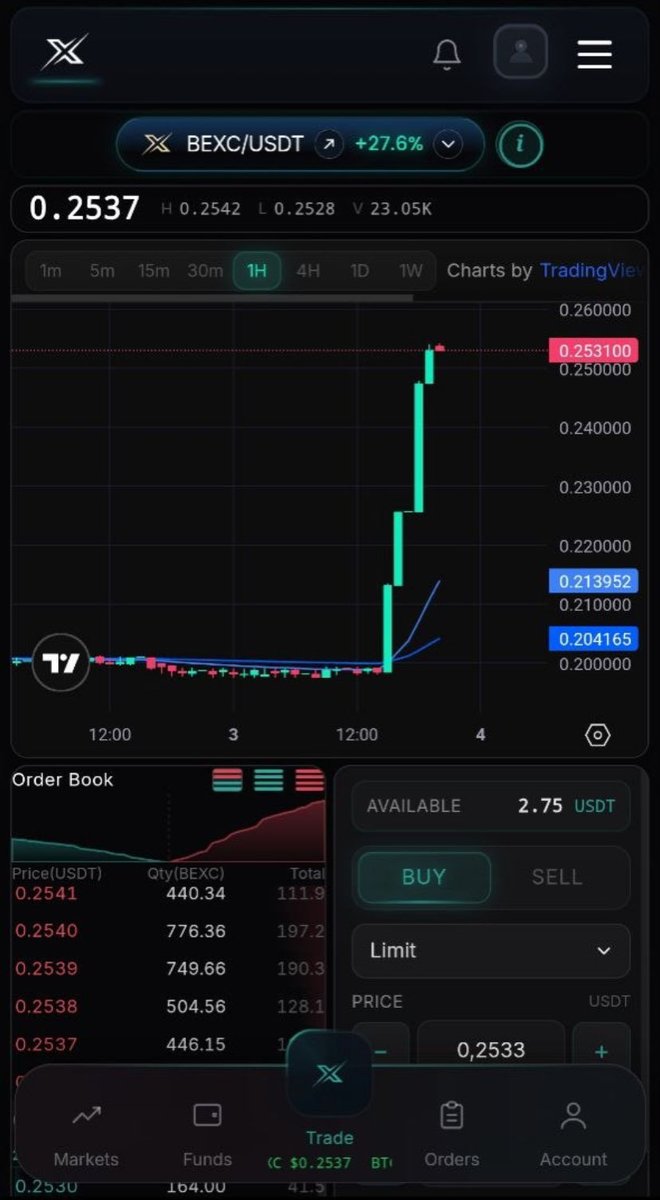
May 3
Great things are coming. It won’t be long now. 👨🍳
It's time to see the peaks🔥
@ByteExchange
bexc.io ✅ $BEXC
#BEXC #BTC #ETH #Sol #Bytepad
#ByteChain #
2
11
23
208

Apr 22
I mean, if this were a bytechain, you would either use the hex-encoded ASCII version of the string or the hex-encoded wide version. You wouldn’t use both.
The string can only exist in one format in the compiled binary. Imported functions are ASCII. Usage strings are often ASCII. File system paths are often in UTF-16.
So why use both ascii and wide for the same string? It feels wasteful and could maybe even add false positives.
1
2
3,330
Mar 24
Why choose BytePad?
✅ Expert-curated projects
✅ On-chain vesting & real-time tracking
✅ Referral program – earn bonuses
✅ Direct participation with your exchange balance
Built for serious investors.
#Web3 #ByteChain
3/4
1
4
9
67

Feb 20
Next up: more ecosystem updates around ByteChain (RWA-focused), Kupr, bounty campaigns, and Bytepad.
Stay close — we’re building fast. 🧱🔥
#ByteChain #DeFi #Web3 #BEXC
2
1
12
412
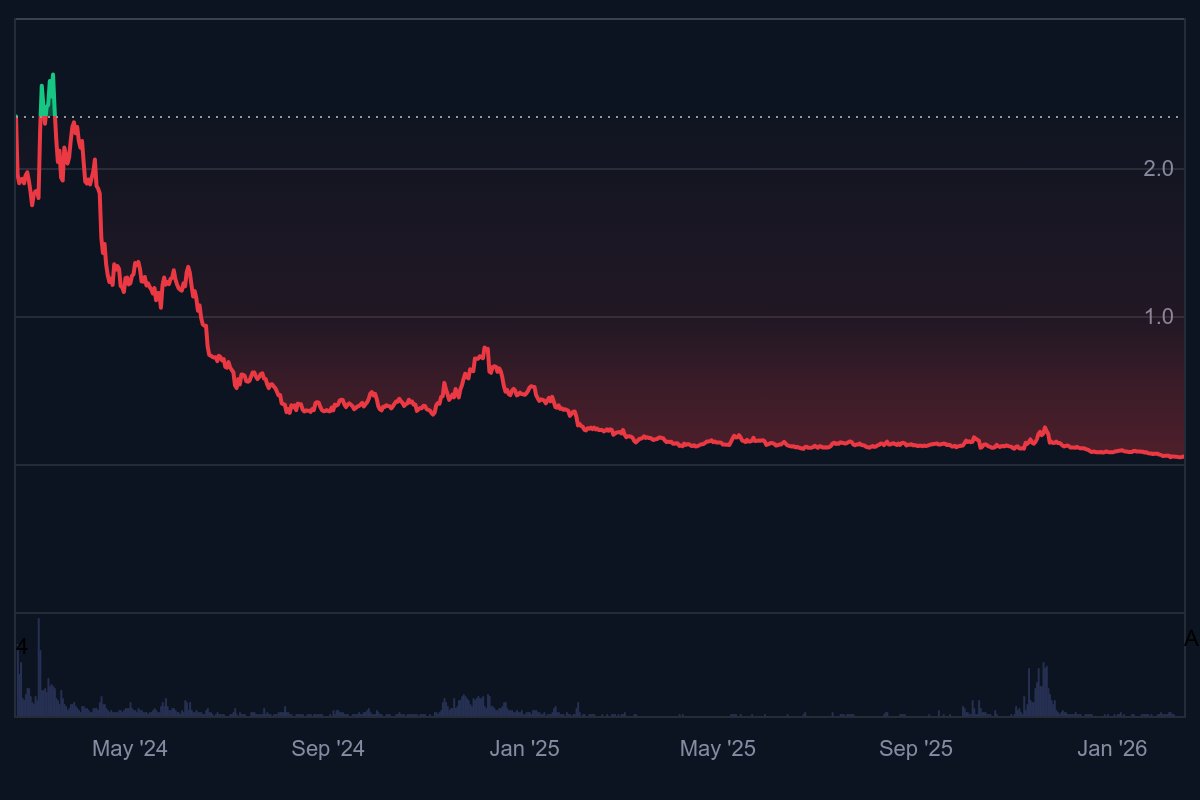

Feb 7
From underserved streets to global liquidity.
Byte XC bridges the gap. One token. Endless possibilities.
BEXC 🔥 bytexc.io
#FinancialInclusion #DeFi #ByteChain

10
14
102
Feb 3
$BEXC LISTED LIVE – Feb 1, 2026! ✅
ByteChain Nodes win big: Max 2,000 supply, revenue share from fees & burns 🔥, chain security.
Feb 15 unlocks NFT staking more perks.
Diamond hands on nodes! 💎 #BEXC #ByteChain #Node

2
12
18
198

Jan 30
- Gelirin �'ı LP larla paylaşılan Perp DEX (#ByteMX)
- Farklı ülkelerde kurulacak yerel borsalarda @ByteExchange ve #Bytechain altyapısı ile sınır ötesi para transferleri
- Likidite kiralama ile elde edilecek kardan pay alma.
gibi ürün ve hizmetler geliştirdi.
1
4
40
Jan 30
- Güçlü, hızlı ve güvenli borsa altyapısı kurdu.
- Cosmos EVM uyumlu kendi blokzincirini aktif etti (#bytechain).
- 100 validatör, 3sn blok hızı, ultra düşük fee.
- Nod işletmecilerine 120 ay ödül teşvik programı
- Bytechain üzerinde #Rwa tokenizasyonu
1
1
6
89
Jan 30
Bu projeyi 2021'den beri takip ediyorum. O dönem bir miktar yatırım yapmıştım. Ciddi bir ayı dönemi geçirmemize rağmen, yatırımımdan zarar ettirmedi. Bu süreçte proje resmen evrim geçirdi. Kripto markette 4 yıldır yaşanan fırtınadan;
#byteexchange #bexc #bytechain #Bitcoin
Jan 30
🚀 ByteChain is coming.
The foundation of the Byte Ecosystem is going live.
🗓 ByteChain Mainnet: 01.02.2026
⚡ Cosmos EVM
⏱ 3s block time
💸 Ultra-low network fees
Let’s build real value on-chain. 🌍
#ByteChain #BEXC #Blockchain
2
11
19
212
Jan 30
📌 ByteChain Mainnet:
01.02.2026
🌐 Cosmos EVM
🪙 Native coin: BEXC
The infrastructure is ready.
The ecosystem is growing.
Welcome to ByteChain. 🚀
#ByteChain #BEXC #ByteEcosystem
3
15
222
Jan 30
🤝 Support for projects building on ByteChain
Projects may receive:
• Listing support on Byte Exchange
• Pre-sale opportunities via BytePad
• Ecosystem & community exposure
• Long-term collaboration opportunities
Let’s grow together.
#StartupSupport #Web3Builders
2
3
15
222
Jan 30
🧠 Calling all builders & teams
Developing on ByteChain means: • EVM compatibility
• Fast & low-cost execution
• RWA-friendly infrastructure
We invite Web3, DeFi & RWA projects to build on ByteChain.
#BuildOnByteChain #Developers
1
2
11
65
Jan 30
🚀 BytePad & early opportunities
With BytePad, users can:
• Earn tiers
• Access early-stage projects
• Join ecosystem launches & pre-sales
ByteChain BytePad = full lifecycle support for Web3 projects.
#BytePad #Launchpad #Airdrop
1
3
12
88
Jan 30
🪙 BEXC — Native coin of ByteChain
• Fixed supply: 150,000,000 BEXC
• Entire supply created at genesis
• ❌ No inflation
• ❌ No future minting
BEXC powers:
⚙️ Network fees
⚙️ Nodes & validators
⚙️ Ecosystem incentives
⚙️ Governance participation
#BEXC #Tokenomics
1
2
9
129
Jan 30
🌍 Built for RWA & real economy
ByteChain is optimized for: • RWA tokenization
• On-chain financial products
• Institutional & real-world use cases
• Long-term sustainable Web3 projects
Our focus:
➡️ Bringing real assets & real businesses on-chain.
#RWA #Tokenization #BEXC
1
2
12
169
Jan 30
🚀 ByteChain is coming.
The foundation of the Byte Ecosystem is going live.
🗓 ByteChain Mainnet: 01.02.2026
⚡ Cosmos EVM
⏱ 3s block time
💸 Ultra-low network fees
Let’s build real value on-chain. 🌍
#ByteChain #BEXC #Blockchain
5
33
145
14,438
Jan 30
5/5**
Quick summary:
📅 Mainnet: Feb 1, 2026
🌐 Cosmos EVM, fast & cheap
🪙 BEXC: 150M fixed supply
Goal: RWA sustainable real-world projects
The foundation layer of the Byte Ecosystem is coming…
You ready? 👀
#ByteChain #BEXC
1
4
41