


May 19
Built payment receipts that prove themselves. No trusted verifier. No callhome. Just a STARK proof in the x402 PAYMENT-RESPONSE header. Heres what that actually means 🧵
1
2
2
67

The look you make when you're 45 minutes into the call and you still have bonus airtime left. "No you hang up first..." 😂 Valid this week only.
Run!👀
#Ambia #AirtimeBonus #CallHome #kenyansindiaspora #254kenyanairobi 🇰🇪🇰🇪🇰🇪

1
2
47

We’re pumped to be joining the lineup at CallHome 2026 in Brantford, ON on July 25th. We can’t wait to share the stage with this unreal roster 🔥 This one’s going to hit hard. Who’s coming out?
#EconolineCrush #CallHomeFestival #BrantfordOntario

3
60

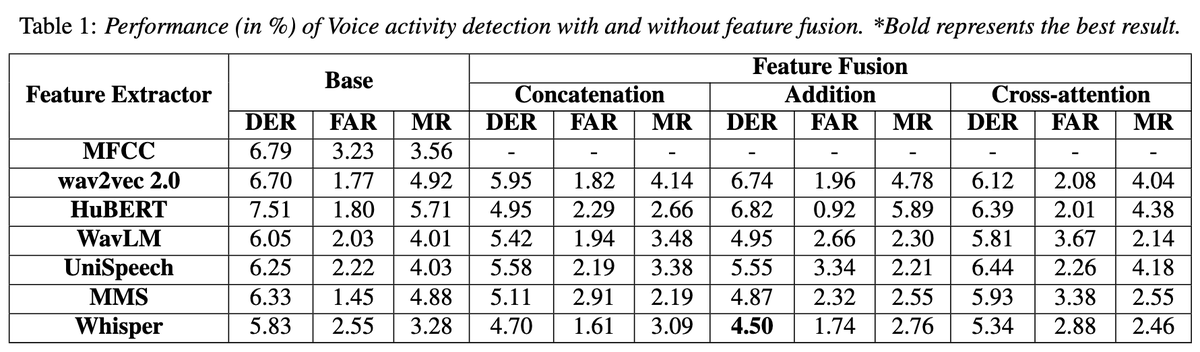
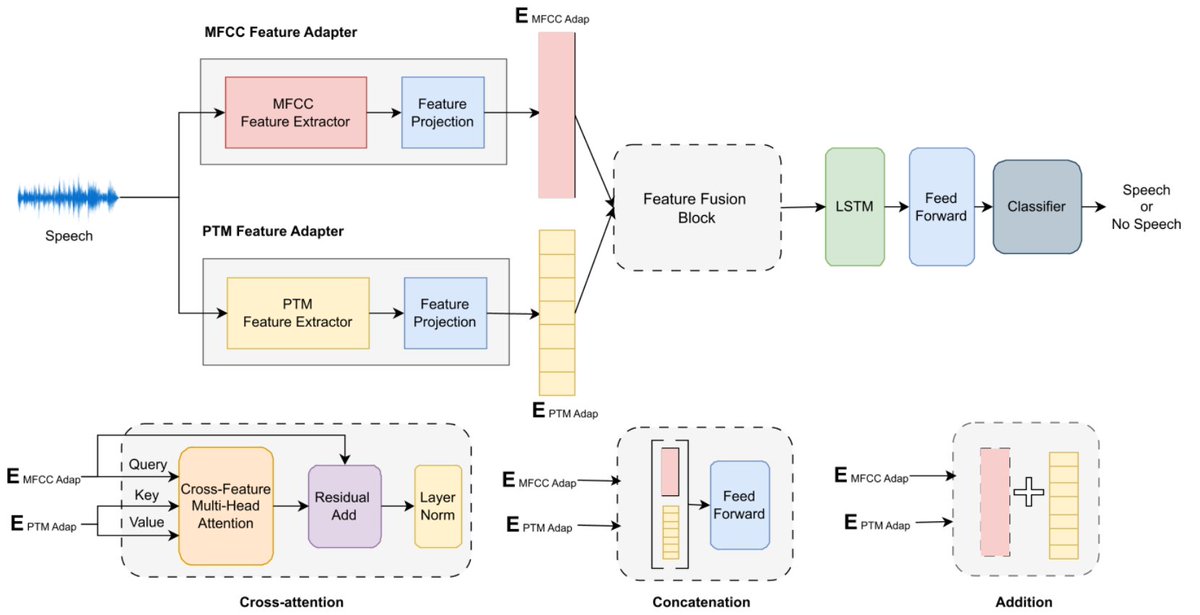
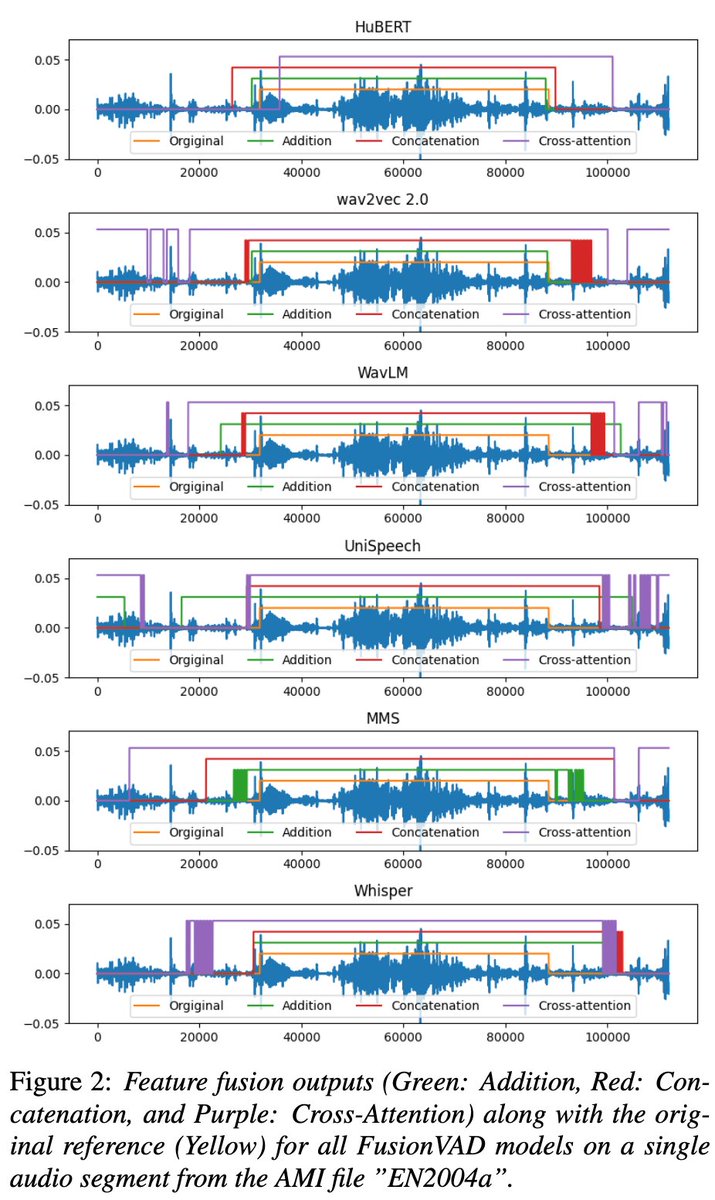
Attention Is Not Always the Answer: Optimizing Voice Activity Detection with Simple Feature Fusion (INTERSPEECH2025)
・MFCC / 事前学習モデルを用いた音声区間検出の網羅的な調査
・3種類のデータセット(AMI・Callhome・VoxConverse)を使った調査の範囲内ではWhisper-baseが最も性能が高く、Pyannoteも大きく上回る
・MFCCはMissing Rateが低くなる傾向があり、ノイズを誤って拾いやすいと考えられる
・MFCCと事前学習モデルの特徴量を両方使えば性能が上がるが、Cross-Attentionは(VADというタスクが文脈情報を必要としないため)非効率
paper: arxiv.org/abs/2506.01365

1
4
31
2,006

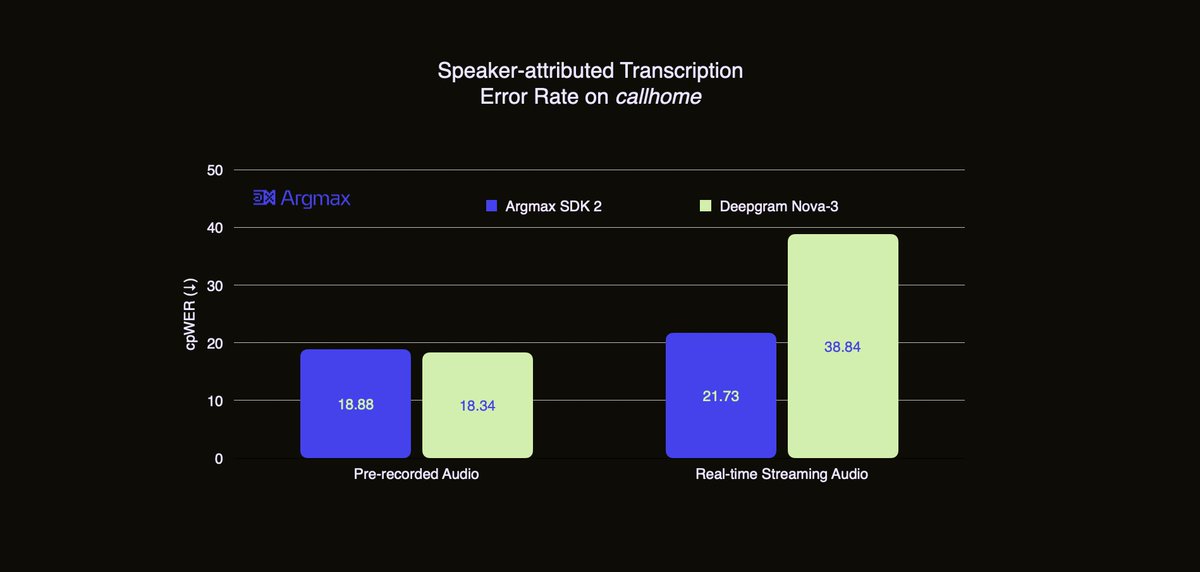
In our benchmark preview, Argmax SDK 2's Real-time Transcription with Speakers surpasses top cloud APIs like Deepgram in speaker-attributed transcription accuracy as measured by cpWER (lower the better) on the callhome dataset comprising telephone conversations.
As usual, we will publish reproducible and open-source final benchmarks in OpenBench along with the general availability of Argmax SDK 2 in February 2026.
In addition to these benchmarks, we have been using this system to transcribe our internal meetings at @argmax and we have observed dramatically improved speaker consistency as well as reduced speaker count errors compared to Argmax SDK 1.x.
1
22
2,657

21 Nov 2025
Canada, we’re coming to Brantford, Ontario next summer to headline CallHome Music Festival on Friday, July 24th. First time in the city. Full show. Big weekend!
See you there.
Tickets: callhomefest.ca

1
7
20
2,818

7 Sep 2025
What I've been reading: 📰 Streaming Sortformer
ELI5 👉 Given audio with multiple people speaking, possibly over each other, how do we get segmentation that says: speaker1: [0-3s], speaker2:[2s-4s].
NVIDIA propose a way to divide up the audio in chunks (e.g. 15s); for every chunk predict a binary mask of when a speaker is ‘on’, and in streaming fashion, stitch the outputs of the chunks in a consistent manner.
💡What I’m thinking:
Voice Agentic AI is hot!
- How does this technique measure up to pyannote, AssemblyAI and other commercial APIs
- A hard-coded limitation of 4 speakers max, nicer if this is learned and dynamic
- Speaker diarization has lot of similarities to object tracking in CV/Robotics, where stitching is known as association
-----
More details:
🔥Important Results:
- Achieve SOTA on several standard diarization datasets (DIHARD, CALLHOME) with latency of 1 second.
- Comparable or better than offline (non-realtime) equivalent!
🔹Model:
A key contribution here is how to do better sticking cross audio chunks, as the order of speaker might be permutated. A cache with acoustic embeddings of the previous chunk is used to figure out the inter-chunk alignment. The embeddings of the speakers are ordered by ‘arrival’ (i.e. the time when a speaker first spoke)
🔹Data:
< 10000 hours of speaker diarization datasets (speech with multiple speakers)
Fisher, AMI, DIHARD, VoxConverse, AISHELL, CallHome.
🔹Compute:
64 V100 GPUs
🔹Key Related Works:
- Softformer (using sorting instead of perm-invariant training)
- SA-EEND (speaker-tracing buffers)
NEST encoders (trained from Mel-spec features)
🔹Interesting Tidbits:
They did not need to use common data aug techniques (SpecAugment, RIR Noise)
-----
☝️May contain omissions or errors, apologies in advance. Let me know your thoughts in the replies!

1
1
202

21 Jul 2025
A crowd of up to 8,000 people jammed Lions Park on Saturday night for headliners, The Glorious Sons at the successful CallHome Music festival.
Photo credit goes to Randy Gilbert.

4
236

17 Jul 2025
playing Revelree Music Festival and CallHome Music Festival this weeeknd who’s coming ?!!! ❤️🔥❤️🔥❤️🔥
3
6
31
783
Diarized transcriptions have 40% lower error rates
SpeakerKit's diarization (who spoke when) accuracy is already leading across cloud-based and on-device systems as described in our Interspeech 2025 paper.
However, diarized transcriptions (word-to-speaker mapping) traditionally required additional algorithms or models to be used in practical applications, e.g. WhisperX.
Argmax Pro SDK 1.6.0 introduces a new model-free algorithm to significantly reduce the word-to-speaker mapping errors!
Specifically, we improved the WDER from 11.2% to 6.8% as measured on the CALLHOME dataset. For comparison, this matches the accuracy of WhisperX without any additional compute or models.
Open benchmarks are posted here: github.com/argmaxinc/SDBench
1
3
368

10 Jul 2025
brantfordexpositor.ca/news/e… Excitement builds for Brantford's CallHome Music Festival
1
339

18 May 2025
Horrible news today about the death of three children at the hands of an alleged impaired driver. We remind all road users that collisions involving alcohol are far more likely to cause serious harm - and that you can’t take it back. #Prevention #PlanAhead #callhome #taxi #DD
1
2
121


13 Feb 2025
#ThrowbackThuesday to 2015! New Mexico’s VLA (Very Large Array). Please call home. #newmexico #VLA #callhome #greggbraden #wisdomtraditions #purehuman

8
8
126
3,420

4 Feb 2025
A mother’s love knows no distance. Call home, share your news, and never miss a moment with FroggyTalk.
Download the FroggyTalk app today froggytalk.sng.link/D2h3p/ew…
#EritreaCalls #StayConnected #CallHome #FroggyTalk

1
12

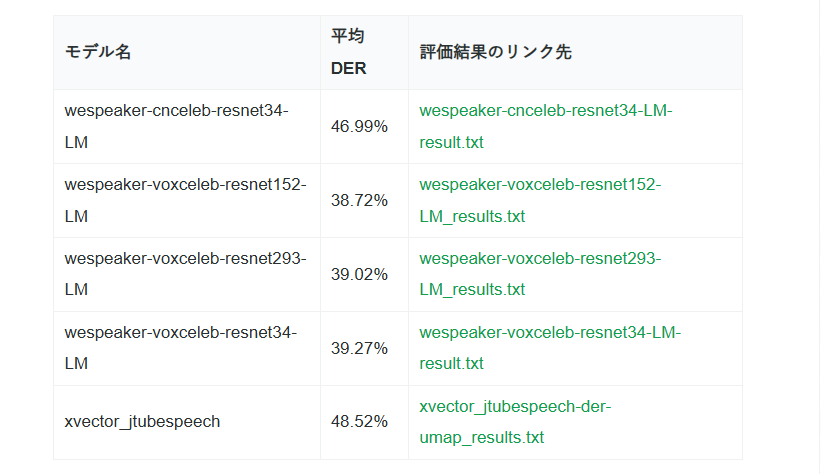
日本語データセット(callhome)で話者ダイアライゼーションの評価をしました!最近モデル?で評価されているものがなかったので参考になれば!
wespeakerとxvectorの話者埋め込みモデルを使った日本語話者ダイアライゼーションの評価 - yousanのメモ ayousanz.hatenadiary.jp/entr…
5
336
話者ダイアライゼーションの評価につかうcallhomeの日本語データセット部分を各ファイルごとにwavに変換・メタデータのjson化、rttmファイルの追加したものをhuggingfaceに公開しました!
huggingface.co/datasets/ayou…
3
11
1,388

15 Sep 2024
HOY, 15 DE SEPTIEMBRE, disfruta de MÁS TIEMPO para hablar con tus SERES QUERIDOS!
Usa el CÓDIGO PROMOCIONAL “CALLHOME” y recibe un BONO DEL 20% en recargas de llamadas entre $5 y $100.
Disponible en la app, en línea o en las tiendas de #BOSSRevolution. Aplican términos.
2
6,148
15 Sep 2024
TODAY, 9/15 ONLY, enjoy MORE TIME to connect with your LOVED ONES!
Use PROMO CODE “CALLHOME” to receive a 20% BONUS on calling recharges between $5 and $100. This offer is available in the app, online, or at BOSS Revolution stores.
4
9,472