
Jun 1
Osee Mega 22S4, 22” Multi-View Production Monitor Review by Keith Knittel @keith-knittel
youtu.be/aKC_Y0HRASk
.
.
#oseemonitor #oseetech #moviemaking #Mega22S4 #filmproduction #cameracontrol
#cameragear #Multiview #PIP #PBP #QuaterDisplay
#cinematography #filmmaking #producer

3
55

If you make that with MagSafe and a cover for the CameraControl button, I would buy one immediately
8
2,302

May 6
Precise camera control in LTX 2.3 is finally here. 🎬🚀
The new "Camera Man" IC LoRA allows you to transfer cinematic motions—Zoom, Pan, Orbit—directly to your AI videos.
⚠️ The golden rule: Keep your prompts SIMPLE. Detailed action descriptions will actually LOCK the camera movement.
Full workflow & deep dive: 👇
🔗 youtu.be/Msa6xujg4jA
#LTX23 #ComfyUI #AIVideo #GenerativeAI #CameraControl
2
21
159
9,657
Apr 27
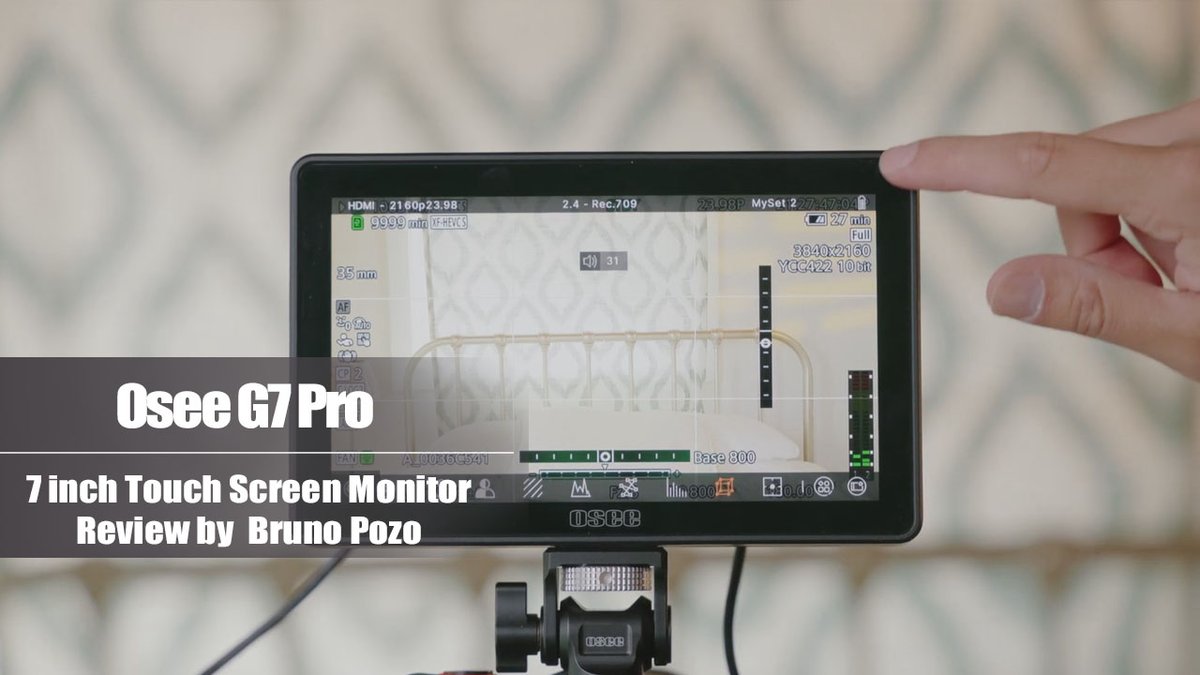
Osee G7 Pro Camera Control Touchscreen Field Monitor Review by Bruno Pozo
@BrunoPozo4Real
youtu.be/WmUeUebohFc
.
.
#moviemaking #touchsreen #filmproduction #cameracontrol #cameragear #cameragear
#artdirector #filmlife #G7pro #filmmakers #oseemonitor #oseetech
2
319


Mar 26
⭐️mini MV [ Boom! Boom! ]
WAIFF京都のワークショップで
STUDIO異次元さん@CreepyTheater_K
が言ってたよ…
Hailuoの爆発は最強だって!
CameraControl機能も初めて試したらめっちゃ効いた!
created by Hailuo2.3
Edit:@capcutapp_jp at Mobile app
Music:SUNO
#HailuoCPP @Hailuo_AI
4
9
74
4,212

Jan 21
En dan hebben we het nog niet gehad over de paradepaardjes van @de_NVA: na CameraControl en MoneyControl gaan ze ook voluit voor ChatControl.
@Bart_DeWever is de ondergraver ca onze vrijheden.
3
14
191

31 Dec 2025
#POTD | #SIGGRAPHAsia2025 | Customizing Camera-Controllable Video Diffusion Models with Multi-View Performance Captures
📍@Yuancheng_Xu0, @wenqi_xian, @maleewahaha et al. (Eyeline Labs × Netflix)
🎥 Why do customized video diffusion models lose identity as soon as the camera moves?
Because most personalization relies on single-view data and weak camera control. Once viewpoints change, identity consistency collapses—making cinematic use nearly impossible.
🔷 Method
The paper introduces a new customization pipeline built on multi-view performance capture 4D Gaussian Splatting (4DGS). 4DGS is repurposed as a data generator, producing identity-consistent videos with precise 3D camera trajectories and relightable conditions. A two-stage training strategy separates camera-conditioned video generation from subject-specific multi-view identity learning.
🔷 Results
The model achieves strong multi-view identity preservation under full 3D camera motion, accurate camera controllability, and robust lighting adaptation. It further supports multi-subject generation, scene customization, real-life video adaptation, and motion/layout control—key requirements for virtual production.
By decoupling camera learning from identity learning, this work bridges volumetric capture and video diffusion for filmmaking-ready generation.
Why it matters:
This paper moves video diffusion closer to real virtual production 🎬—where identity, camera motion, lighting, and interaction must all work together. It shows how generative models can move beyond single-view personalization toward cinematic, controllable video synthesis.
More in comments 👇
#PaperOfTheDay #VideoDiffusion #VirtualProduction #CameraControl #MultiView #GaussianSplatting #GenerativeAI #ComputerVision
1
1
4
156
29 Dec 2025
Osee G7 Pro 7 Inch Camera Control Touchscreen Field Monitor Review by Your Filmmaker @iudosen
youtu.be/RcGTe81-Ph0
.
.
#moviemaking #touchsreen #filmproduction #cameracontrol
#cameragear
#directorofphotography #G7pro #filmmakers #productionlife #oseemonitor #oseetech

1
3
204

9 Dec 2025
The 16e is not a bad phone
It cuts features no one needs such as MagSafe, Dynamic Island and Cameracontrol. Removing all of that junk made it the definitive iPhone. It looks unique and is exactly what 99.9% of people need.
If i'd gotten an iPhone it would be the 16e
*Im on S25
1
2
675

7 Dec 2025
いえいえ、たいした協力もできませんで…
しかし、昨日まで1.0を使っていたので、LED?…CAMERACONTROL?…FPVerの夢がたくさんつまってましたねw
こんど、jsonのぞいてみます😁
3
133

24 Nov 2025
Camera M now supports Camera Control.
Adjust:
• Focus,
• EV
• ISO
• Exposure duration
• White balance
More info here:
camera-m.com/blog/camera-m-9…
#CameraM #iOS26 #CameraControl #iPhone17 #iPhone17Pro #AppStore #Apple

ALT Camera Control on Camera M app.
4
396

22 Nov 2025
Control your phone with no burden. Enjoy the seamless camera control experience with
aulumu A17 series.
#aulumu #aulumucase #linkinbio👆 #cameracontrol
#iphone17 #apple #tech




6
824

12 Nov 2025
Hailuo 2.3 from @Hailuo_AI makes motion feel easy! 🎬✨ Dynamic poses performe nice, and camera moves hit just right! No drift, no jitter. Action, dance, and sports look smoother and cleaner! 🚀 You don't want to miss this!!! 🤩
#Hailuo23 #AIVideo #CameraControl #MotionConsistency #Filmmaking #WaveSpeedAI
2
4
19
835



21 Sep 2025
tornem a l'edat mitjana? #Fotor #AIArt #FotorAIChallenge #CameraControl via @fotor_com fotor.com/referrer/77ajckx9
2
15
21 Sep 2025
✨divertteix-te fen coses increibles #Fotor #AIArt #FotorAIChallenge #CameraControl via @fotor_com fotor.com/referrer/ax4mbory
3
12

A Camps Bay couple will have to comply with a previous court order, which compels them to reposition their 24-hour CCTV cameras, which currently invade the privacy of their neighbour.
#CCTVBoundaries #CameraControl #CampsBay
Read on tinyurl.com/ms3zd44f

7
1,437

15 Sep 2025
London's New Facial Recognition Cameras are USELESS! #fypdong #fypppppppppppppp #fypppppppppppppp #london #camera #news #crime #trendingnow #viralvideos #viralvideotiktok #recognition #cameracontrol #camera #police #SkyNews #GBnews #BBCNEWS
2
94