
31 Mar 2025
Why debug when you can just ask your code "What’s the probz?" 🤔✨ #NoCodeMagic #ChatWithYourCode #ProbzAI
2
29

26 Sep 2024
🚀 Llama-3.2引领文档聊天新纪元:RAG流程全面解析! 📚🤖
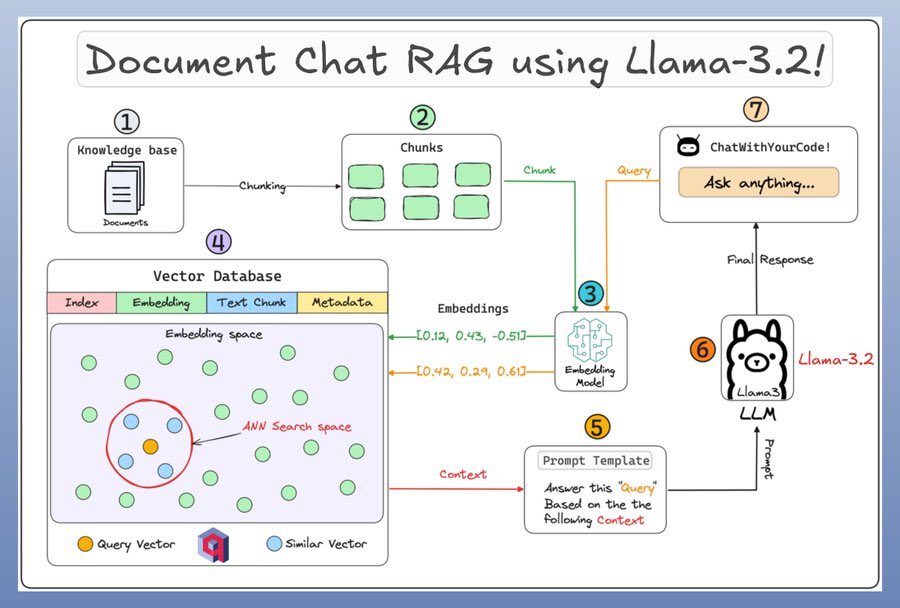
这张图解展示了如何使用Llama-3.2实现文档聊天的检索增强生成(RAG)流程。具体步骤如下:
1. 知识库 (Knowledge Base)
- 首先,我们有一个知识库,其中包含各种文档。
2. 分块 (Chunking)
- 这些文档被分成若干小块,每个块代表文档的一部分内容。
3. 嵌入模型 (Embedding Model)
- 每个块通过嵌入模型转化为向量,这些向量是表示文本内容的高维数据点。
4. 向量数据库 (Vector Database)
- 所有这些嵌入向量被存储在一个向量数据库中。该数据库包括索引、嵌入、文本块和元数据。
- 在数据库中,查询向量与相似向量之间的关系可以帮助检索最相关的信息。
5. 提示模板 (Prompt Template)
- 提示模板根据查询提供上下文,指示需要回答的问题以及相关的上下文信息。
6. Llama-3.2模型 (Llama-3.2 LLM)
- Llama-3.2大语言模型根据提示模板生成响应。这一过程包括从提示中获取上下文,并基于此生成相应答案。
7. 用户界面 (User Interface)
- 最终的响应通过用户界面返回给用户。例如,用户可以通过接口“ChatWithYourCode!”进行提问并接收最终答案。
总结
据Mlion.ai分析,该流程详细说明了如何将文档分块并存储为嵌入向量,通过向量数据库进行高效检索,然后利用Llama-3.2模型生成自然语言响应。这种方法不仅提高了信息检索的准确性,还能提供更智能和上下文相关的答案,使得用户体验更加流畅和高效。
1
1
10
1,194