
Next #MilitaryAdvisor, #NSCS 🇮🇳 - Lt Gen Rajiv Gahi (SYSM, UYSM, AVSM, SM), Currently the Deputy Chief of Army Staff (Strategy), Former DGMO during India's successful decisive #OperationSindoor , will be the first SERVING three-star officer to hold the Military Advisor post in India’s National Security Council Secretariat (NSCS) under NSA #AjitDoval
Next #IndianArmy Chief - Lt Gen Dhiraj Seth (PVSM, UYSM, AVSM), currently the Vice Chief of the Army Staff, will succeed General Upendra Dwivedi upon his retirement on June 30, 2026. Lt Gen Seth is Armoured corps officer, commanded 21 Corps (Strike corps), South Western Command and was GOC-in-C Southern Command during #OperationSindoor. Played a pivotal role in the shift from #ColdStart to #ColdStrike Doctrine and the raising of the Bhairav Light Commando Battalions.

New #CDS - Gen NS Raja Subramani (PVSM, AVSM, SM, VSM), Former Military Adviser at the National Security Council Secretariat, Former Vice Chief of the Army Staff and GOC-in-C, Central Command - Commander who played a key role in planning and executing or #OperationSindoor . He has taken over after CDS General Anil Chauhan completed his tenure on 30 May 2026.
New #IndianNavy Chief - Admiral Krishna Swaminathan* , (PVSM, AVSM, VSM), Former FOC-in-C, Western Naval Command, commanding Arabian Sea theater during #OperationSindoor . He succeeded Current Indian Navy Chief Admiral Dinesh Kumar Tripathi who retired on 31 May 2026.
20

Sometimes it takes 13 seconds to start a hotrod after it’s been about a month.
#shelby #shelbycobra #milesthroughtime #coldstart
1
6


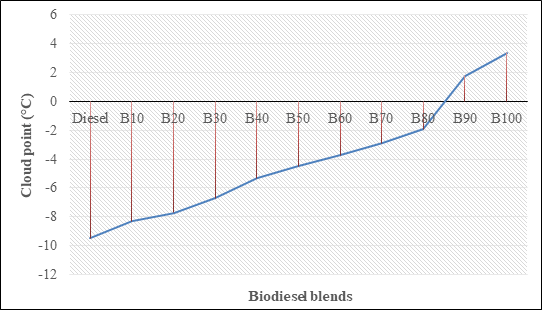
Blm tentu, minyak indomie itu 100% transfat & b50 bkn transfat.
Contoh B20 aja cuma selisih 2-7° f (1.1 - 3.9° C) diatas titik keruh pure petro diesel.
Kl suhu di Dieng sampe < -5° barulah akan jadi mslh coldstart.
Itupun bbm B50nya ga beku kaya minyak indomie diatas 😌

373

Check out my new video! Desperate Cold Engine Cranking while stuck in the deep snow during a Frigid winter Blizzard ❤️❤️🏁🏁
youtube.com/watch?v=9FaaxjUH…
#coldstart #brrrr #engine #cranking #vehicles
9
Check out my new video! Desperate Engine Cranking on my best friend @dtduro_offical KTM Motorcycle ️️❤️❤️🏁🏁
youtube.com/watch?v=ocOO3U1t…
#coldstart #brrrr #engine #cranking #vehicles
13
Check out my new video! Desperate Cold Engine Cranking while stuck in the deep snow during a Frigid winter Blizzard ❤️❤️🏁🏁
youtube.com/watch?v=WxuC2zTK…
#coldstart #brrrr #engine #cranking #vehicles
7
Check out my new video! Desperate Cold Engine Cranking while stuck in the deep snow during a Frigid winter Blizzard ❤️❤️🏁🏁
youtube.com/watch?v=b0RVUILY…
#coldstart #brrrr #engine #cranking #vehicles
7
Check out my new video! Desperate Cold Engine Cranking while stuck in the deep Swamp ❤️❤️🏁🏁
youtube.com/watch?v=qoMi4E_5…
#coldstart #brrrr #engine #cranking #vehicles
7
Check out my new video! Desperate Cold Engine Cranking while stuck in the deep Swamp ❤️❤️🏁🏁
youtube.com/watch?v=_jPYsxrM…
#coldstart #brrrr #engine #cranking #vehicles
2
Check out my new video! Desperate Cold Engine Cranking ❤️❤️🏁🏁
youtube.com/watch?v=QDjLGadE…
#coldstart #brrrr #engine #cranking #vehicles
14
Check out my new video! Desperate Cold Engine Cranking ❤️❤️🏁🏁
youtube.com/watch?v=VY79DFRW…
#coldstart #brrrr #engine #cranking #vehicles
10

It's a joy to start, a pleasure to ride, a blessing to own, a ritual to maintain.
#kawasaki #ninja500 #coldstart #hindle #sportsbike
108


India Just Changed its Battle Plan for Pakistan, Cold Start 2.0, Ajit Do... youtu.be/q6Y1J-Hnm3Y?si=vNnV…
Crisp outlining of Coldstart 2.0 by @AadiAchint
@ajaykraina @BPanIndian
@LtGenDPPandey @KlRajiv @mjavinod @FlyerGS
@LevinaNeythiri @live_pathikrit
5
15
2,042

May 28
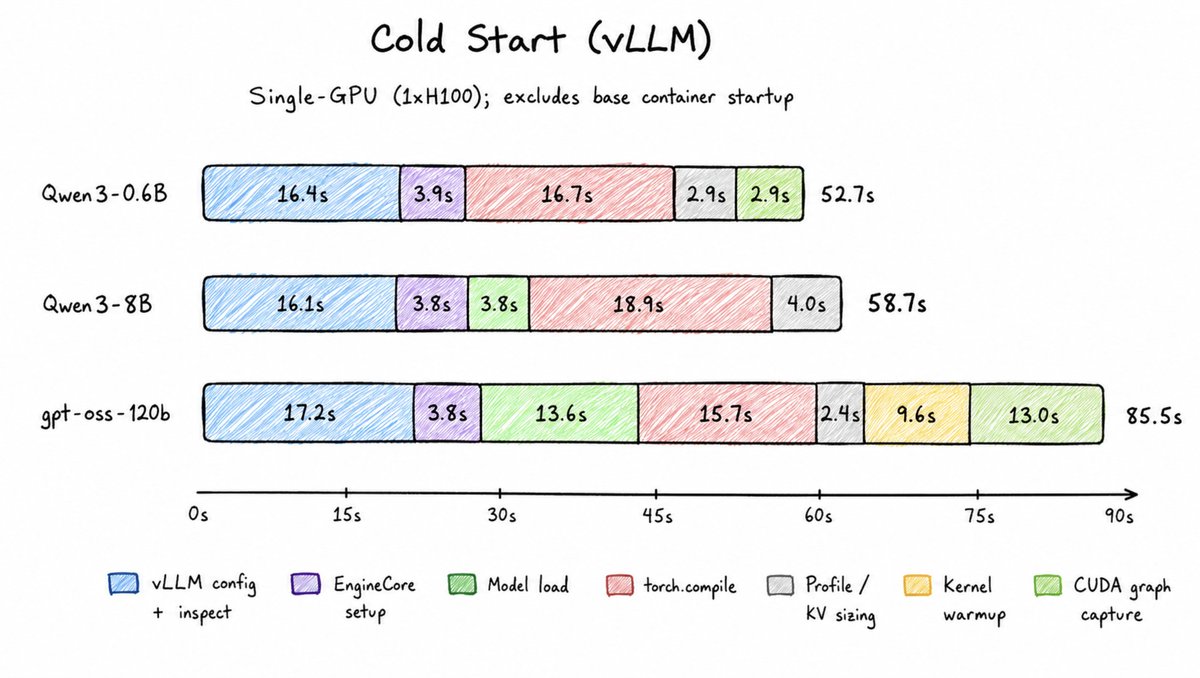
Recently when I was trying to increase the rollout throughput of my RL fine tuning pipeline, I noticed that the GPU stayed idle for long periods of time instead of actually serving the LLM.
After profiling, I realised there are several coldstart issues when you try to serve a model on vLLM (inference engine).
Two largest contributors to coldstart are vLLM inspect and torch.compile.
vLLM inspect - This inference engine supports a lot of different architectures and models - dense, MoE, multi-modal, speculative decoding, BF16, FP8, etc.
In order to create a reasonable executing plan it has to inspect all the layers of the model it is running, - layer shapes, attention heads, rotary embeddings, hidden dimensions, KV structure.
vLLM precomputes KV cache sizes, block allocation strategy, paged attention metadat, batching scheduler limits.
For large models like gpt-oss- 120b this becomes substantial.
Next is torch.compile = PyTorch compiles model graphs into optimized kernels. Most of the time it is pretty hard to beat these kernels on performance basis (although if you are good at GPU programming, can beat).
But in order to generate these optimised kernels, torch takes substantial time as it has to observe tensor shapes, control flow, operator patterns to generate stable graphs. These graphs are then used by the compiler to fuse matmuls, layernorm, activations and attention ops into fewer kernels. This is obviously expensive.
My next goal is to reduce this time as much as possible. Perhaps by techniques like cuda checkpointing and snapshots.
Will update with progress.
2
115

May 23
All the people saying you want efi and abs at minimum are wuzzes, this was my daily for a year -25°c to 30°c never touched the carb ran just fine, coldstart just fine.
Learn to drive !

May 21


17
3
84
2,821

May 22
Sharing, Coldstart, how I am building software with agents. It changes every week.
You will probably not like it.
There is no one-shot.
There is not solution.
You have to read and think a lot.
More of a pattern than anything else.
2
3
130

May 21
New release!
smolvm 0.7.2 is live!
Big impact for a smol release.
Highlights!:
- coldstart time <200ms on most modern hardware.
- stability improvements thanks to open source contributors
10
6
52
5,965