Leo retweeted

Gemini 3.1 pro can now compress a 60-hour workweek into 15 hours while your boss still believes you’re grinding (for FR££).
Here are 12 prompts that automate reports, emails, and presentations.👇🏼👇🏼
(Save this 🔖 you’ll need it later)

28
40
59
2,301

I am pioneering new software connected to my plumbing business and farm. My world will always be human driven and AI will assist. My ecosystem is built with hands and land and will remain stable. Monetary ecosystems are not stable and AI will compress and destabilize
1
1
4


19m
A flood-planning task that normally takes six minutes in GIS took 46 seconds when a local AI system was allowed to run the workflow.
The system is called TransResAI. Researchers at Old Dominion University built it for Hampton Roads, Virginia, one of the most flood-exposed transport regions in the United States.
That setting matters. Hampton Roads has coastal roads, bridges, tunnels, storm surge, sea-level rise, commuter flows, emergency routes, and vulnerable households layered on top of each other. Every useful planning question cuts across several datasets.
A planner might need to know which road links flood first. Which neighbourhoods lose the most mobility. Which census tracts combine high poverty with high exposure. Which adaptation guidance applies. Which routes need priority treatment.
In a normal workflow, that means opening GIS, loading flood layers, joining road-network data, checking traffic model outputs, adding census indicators, reading policy documents, producing a map, then explaining the answer to people who don’t use GIS.
TransResAI turns that into a text box.
A user can ask it to calculate speed reductions under a flood scenario, or show the areas with the highest mobility loss, etc.
The system then breaks the request into parts:
• location
• metric
• scenario
• operation
• visual output.
It writes code, runs the analysis, retrieves the right data, builds the map, and produces the answer.
The architecture is the interesting part.
The model is connected to MATSim traffic simulation outputs, OpenStreetMap flood-risk networks, census-tract demographic indicators, regional policy documents, and a map-rendering pipeline.
It’s also local. The base model is GPT-OSS:20B, running inside a controlled environment with read-only data, no internet access, whitelisted libraries, bounded memory, process isolation, and full logging.
The results were pretty strong.
Analytical tasks took 29.7 seconds on average. Conventional GIS workflows were estimated at 197.1 seconds.
Visualisation tasks took 46.1 seconds. The manual GIS estimate was 364.0 seconds.
Across all tasks, completion rates were above 94%. Mean accuracy was 4.60 out of 5. The system cut task time by 80 to 88% compared with conventional GIS workflows.
But, that said, the caveat is important. It was just five users is a small study. The manual GIS comparison came from expert estimates rather than a fully timed head-to-head trial.
That said, it's an interesting data point. I find that a big bottleneck is having people who know how to connect different datasets fast enough to support a real planning decision.
Anyway, TransResAI is trying to compress that expertise into an interface ordinary planners can use.
Link to paper: arxiv.org/pdf/2606.00042

1
80
panda🐼爱好者💛 retweeted

Jun 13
I compress you, because I love you!

8
765
4,146
68,538

You don't need to read 50 PDFs.
You need to ingest them with NotebookLM, then think with Claude.
Here are 8 prompts that compress 200 hours of research into one Sunday afternoon:
Save this thread 🧵👇

6
8
9
65

Z.AI has made GLM-5.2 available to all GLM Coding Plan subscribers, including Lite, Pro, and Max users. The model is positioned for complex coding and long-horizon agentic engineering, with support for 1M-token context configurations in supported tools. Open-source weights and general API access are expected next week.
That wording is stronger because the official docs specifically say GLM Coding Plan now supports GLM-5.2 for Max, Pro, and Lite users, and the docs also show how to configure 1M context via glm-5.2[1m] plus a 1,000,000 compact window in Claude Code. OpenClaw’s provider docs also list zai/glm-5.2 as the Coding Plan default with 1M context.
Better version of the announcement
Clean press-style version:
Z.AI has released GLM-5.2, its newest flagship coding model, to all GLM Coding Plan subscribers.GLM-5.2 is built for long, multi-step engineering workflows: large-repository understanding, complex debugging, agentic refactoring, tool-heavy coding sessions, and tasks that require sustained reasoning over extended context.The model supports usable 1M-token context configurations in supported coding tools, making it better suited for full-codebase analysis, multi-file migrations, and long-running development sessions. GLM-5.2 is now available across Lite, Pro, and Max GLM Coding Plans, with open-source weights and broader API access planned for next week.
Developer-first version:
GLM-5.2 is now available for GLM Coding Plan users.Use it when a coding agent needs to understand a large repo, reason across many files, run multi-step tool workflows, or stay coherent through long debugging and refactoring sessions.Supported plan users can select glm-5.2; supported 1M-context configurations use the glm-5.2[1m] model suffix and a 1,000,000-token compact window setting where applicable. Open-source weights and API availability are scheduled to follow next week.
Sharper social post:
Z.AI just rolled out GLM-5.2 to all GLM Coding Plan users.The headline is not just “better coding.” It is long-horizon agentic engineering:full-repo context, multi-step debugging, large migrations, longer tool loops, and 1M-token coding workflows.API access and open weights are planned for next week.
Major missing elements
The current text says the right things, but it does not answer the questions developers immediately care about.
1. Exact model identifiers
Add the actual names users should type:
glm-5.2
glm-5.2[1m] for 1M-context use in compatible setups
zai/glm-5.2 in OpenClaw-style provider notation
This matters because the docs distinguish normal model configuration from the 1M-context suffix, and OpenClaw uses provider/model refs like zai/glm-5.2.
2. Tool compatibility
The announcement should not imply universal availability everywhere. It should say something like:
GLM-5.2 is available through supported GLM Coding Plan tools, including Claude Code-style setups, Cline/OpenAI-compatible tools, OpenClaw, and other officially supported coding environments.
Z.AI’s tool integration docs say the Coding Plan is limited to officially supported tools, with OpenAI-compatible and Anthropic-compatible endpoints depending on the tool.
3. Endpoint details
Add a tiny “how to use” block:
OpenAI-compatible endpoint:
api.z.ai/api/coding/paas/v4
Anthropic-compatible endpoint:
api.z.ai/api/anthropic
Model:
glm-5.2
The docs explicitly list those two Coding Plan endpoints and warn that using the wrong endpoint can prevent subscription quota from applying.
4. Context-window caveat
“Support for usable one-million-token context windows” is promising, but it needs precision. Add:
1M context requires compatible tool configuration. In Claude Code-style setups, users should use the glm-5.2[1m] suffix and set the compact window to 1000000. In OpenAI-compatible tools like Cline, set the context window size to 1000000.
That is much more credible than simply saying “1M context.”
5. Quota and cost implications
This is a big missing piece. GLM-5.2 appears to consume Coding Plan quota faster than lighter models. Z.AI’s FAQ says GLM-5.2 and GLM-5-Turbo are deducted at higher rates during peak and off-peak hours, while also noting a limited-time off-peak 1× benefit through the end of September.
Add this to avoid user frustration:
Because GLM-5.2 is a higher-capability model, it is best reserved for complex engineering tasks. For routine development, Z.AI recommends using GLM-4.7 to conserve quota.
That recommendation is directly aligned with Z.AI’s own FAQ guidance.
6. Exact “next week” timing
“Next week” is too vague. Replace it with:
Open-source weights and API access are planned for the week of [exact date], subject to final release checks.
Also include whether API access means:
General Z.AI API access
Coding Plan API access
OpenAI-compatible endpoint access
Model availability on console
Pay-as-you-go pricing
Enterprise/private deployment access
Z.AI’s current public pricing page I found lists GLM-5.1, GLM-5, GLM-5-Turbo, GLM-4.7, and other models, but not GLM-5.2, so API pricing is a missing launch artifact.
7. Open-weights details
“Open-source weights” is not enough. Developers will ask:
What license? Apache-2.0, MIT, custom, research-only, commercial-use allowed?
What parameter count? Dense or MoE? Active parameters?
What precision? BF16, FP8, INT4?
Where? Hugging Face, ModelScope, GitHub?
What inference stack? vLLM, SGLang, llama.cpp, KTransformers?
Minimum hardware? H100/H200/A100? Multi-GPU only?
Will there be quantized weights?
Will there be a model card?
Will there be eval scripts?
Will there be checksums?
Z.AI’s GLM-5 GitHub repo is a useful precedent: it provides model download links, precision information, and local serving instructions for vLLM/SGLang. GLM-5.2 should launch with the same level of deployment clarity.
“Genius-level” positioning upgrades
1. Stop selling “coding model.” Sell “engineering duration.”
Most coding-model launches say: better benchmarks, better coding, better reasoning. The defensible differentiator here is duration under complexity.
Use this frame:
GLM-5.2 is designed for the point where coding assistants usually break: after the repo gets large, the task becomes ambiguous, the first fix fails, tests reveal new problems, and the model has to keep going.
That is much more compelling than “stronger coding performance.”
2. Replace “long context” with “context survivability”
A 1M-token context window is only valuable if the model can retrieve, prioritize, and act on the right information. The launch should introduce a term like:
Context survivability: the model’s ability to preserve task intent, constraints, repo structure, and prior decisions across long tool loops.
Then show proof:
Full-repo migration
Multi-hour debugging session
100 tool-call trace
Before/after diff
Tests passing
No context reset
No hidden manual intervention
3. Publish a “1M Context Reality Sheet”
A brutal, honest table would earn trust:
QuestionAnswer to publishMax input context1,000,000 tokens in supported configurationsMax outputInclude actual max output tokensRecommended compact window1,000,000 where supportedLatency expectationGive ranges by context sizeTool-call reliabilityInclude eval or internal test resultContext degradationState known limitsBest use caseLarge repo, migration, debugging, planningBad use caseTiny tasks, quota-sensitive workflowsRecommended fallbackGLM-4.7 for routine work
The docs already expose some of this, including OpenClaw’s contextWindow: 1000000 and maxTokens: 131072, so the release can build from there.
4. Ship a “model routing recipe”
This would be extremely useful:
Routine code generation: GLM-4.7
Fast edits / small tasks: GLM-4.5-Air or GLM-4.7
Complex debugging: GLM-5.2
Large refactors: GLM-5.2
Repo-wide migration: GLM-5.2[1m]
Long tool-agent sessions: GLM-5.2, max effort
Quota-sensitive work: avoid GLM-5.2 during peak
Z.AI’s docs already recommend GLM-5.2 for complex tasks and GLM-4.7 for general tasks to conserve quota.
5. Add “effort mode” guidance
The Claude Code configuration docs mention switching effort with /effort and recommend max effort for deeper reasoning and more stable complex task performance. That should be part of the announcement because it directly affects perceived quality.
Suggested line:
For complex coding tasks, Z.AI recommends using max effort mode to improve stability on deeper, multi-step work.
Obscure but high-leverage additions
1. Publish failure-mode examples
Counterintuitive but powerful: show what GLM-5.2 still struggles with.
Example:
Known limits: extremely noisy monorepos, ambiguous requirements without tests, generated-code verification without executable environments, and tasks requiring unsupported external tools.
This makes the launch feel serious, not hype-only.
2. Add a “long-horizon trace”
Do not just show benchmark numbers. Show a compressed trace:
Task: migrate auth middleware from legacy session cookies to JWT
Repo size: 820k tokens
Files touched: 41
Tool calls: 186
Tests run: 23
Failed attempts: 4
Recovered from: 3
Final result: all tests passing
Human edits after model: 2 small naming changes
This kind of proof is far more persuasive than “improved reliability.”
3. Measure “recovery after wrong turn”
Most agentic models look good when the first plan is right. Real engineering needs recovery.
Create a benchmark category:
Wrong-Turn Recovery Rate
The model is intentionally given an incomplete or misleading first hypothesis. Score whether it:
detects contradiction
abandons bad path
reads more evidence
patches correctly
updates its plan
does not spiral
4. Add “context needle with code causality”
A normal needle-in-haystack test is too shallow. Use a coding-specific version:
Place an important invariant in one file, a failing test in another, an implicit API contract in a third, and a misleading comment in a fourth. Score whether the model finds the real causal chain.
This would make the 1M-context claim much more meaningful.
5. Launch with a repo-memory starter kit
Z.AI’s best-practice docs emphasize project context, task context, environment context, project-level guidance files, and reusable workflows. Package that into a “GLM-5.2 Ready Repo” template:
.agent/
project.md
architecture.md
testing.md
security.md
style.md
release.md
debugging-playbook.md
Then give users a command:
glm init-agent-memory
Even if the command is just a docs flow, the launch becomes actionable.
6. Publish memory architecture examples
Z.AI’s memory docs distinguish session, project, semantic, episodic, and procedural memory, and recommend keeping instruction memory separate from learning memory. That could become a killer GLM-5.2 story:
1M context is not a replacement for memory architecture. Use 1M context for active working state, project memory for stable repo rules, semantic memory for docs, episodic memory for past bugs, and procedural memory for repeatable workflows.
That is a much more advanced position than “bigger window.”
7. Include “agent hygiene” rules
This is obscure but valuable:
Use GLM-5.2 for planning-heavy tasks, not every autocomplete.
Start a fresh session per major task.
Compress after major milestones.
Use max effort only when the task justifies it.
Keep stable project rules in files, not prompts.
Run tests after each meaningful change.
Use subagents for exploration, testing, and review.
Do not dump the entire repo unless the task benefits from it.
Z.AI’s own best-practice docs emphasize deliberate session management, planning before execution, environment configuration, and full development-loop participation.
Benchmark and proof checklist
The launch would be much stronger if it included:
SWE-bench Verified
SWE-bench Pro
Terminal-Bench 2.0
LiveCodeBench
Aider polyglot benchmark
Repo-level bug fixing
Long-context repo QA
Multi-file refactor benchmark
Tool-call reliability benchmark
Pass@1 and pass@k
Latency by context size
Cost/quota usage by task type
Long-session degradation curve
Human-eval examples
Ablation against GLM-5.1, GLM-5-Turbo, GLM-4.7
Comparison against Claude Sonnet/Opus, Gemini, GPT, Qwen, DeepSeek, Kimi, etc., where legally and methodologically appropriate
Z.AI’s GLM-5 and GLM-5.1 materials already frame the family around agentic engineering, SWE-Bench Pro, NL2Repo, Terminal-Bench 2.0, and long-horizon tasks, so GLM-5.2 should continue that proof style rather than just making a broad “stronger coding” claim.
Trust gaps to fix immediately
One notable issue: the release-notes page I found showed GLM-5.1 as the latest visible model entry, while separate GLM Coding Plan docs and FAQ pages already reference GLM-5.2. That mismatch creates avoidable confusion.
Fix with:
A dedicated GLM-5.2 release note
A GLM-5.2 model card
A GLM-5.2 migration page
A pricing/quota explainer
A “supported tools” matrix
A status page for API/open-weights rollout
A single canonical announcement URL
Suggested final announcement package
Use this structure:
Headline:
GLM-5.2 is now available to all GLM Coding Plan users
Subhead:
A flagship coding model for long-horizon agentic engineering, large-codebase reasoning, and 1M-context workflows.
What’s new:
Stronger coding performance
More reliable multi-step execution
1M-context support in compatible configurations
Better long-session stability
Available across Lite, Pro, and Max Coding Plans
How to use:
Model: glm-5.2
1M context: glm-5.2[1m] where supported
OpenAI-compatible endpoint: api.z.ai/api/coding/paas/v4
Anthropic-compatible endpoint: api.z.ai/api/anthropic
When to use GLM-5.2:
Large repo understanding
Complex debugging
Multi-file refactoring
Architecture changes
Long-running coding agents
Tasks where GLM-4.7 gets stuck
When not to use it:
Simple edits
Routine autocomplete
Quota-sensitive work
Tiny single-file tasks
Coming next week:
Open-source weights
General API access
Model card
Pricing details
Deployment recipes
Proof:
Benchmarks
Long-horizon task traces
Repo-level case studies
Context reliability tests
Tool-call reliability metrics
Strongest single improved paragraph
Z.AI has released GLM-5.2 to all GLM Coding Plan subscribers, including Lite, Pro, and Max users. The new flagship coding model is designed for long-horizon agentic engineering: large-codebase understanding, multi-file refactoring, complex debugging, and extended tool-driven coding sessions. In supported configurations, GLM-5.2 can use a 1M-token context window, including glm-5.2[1m] setups for compatible Claude Code workflows. Open-source weights and broader API access are planned for next week.
That version is precise, credible, developer-useful, and avoids overclaiming.

Z AI released GLM-5.2, its new flagship coding model, for all users subscribed to GLM Coding Plans.
The model includes stronger coding performance, support for usable one-million-token context windows, and improved reliability on long, multi-step tasks.
Open-source weights and API access are planned for next week.
1
89

That’s the core appeal of prediction markets: they compress news → belief → price signal into one step.
1

Everyone talks about better models.
Fewer people talk about context management.
Too little context → the model loses direction.
Too much context → context rot.
A simple rule:
Progress → Compress → Reset.
That's how you keep LLMs coherent as complexity grows.
1
Christopher Brown retweeted

Jun 14
"But rising wages can compress profit margins. As profits come under pressure, firms become more cautious. Investment slows." This is this the crux of it. Usury. Capital funds and leveraged creditors demanding consistently high returns. Workers and their communities will never be anything more than unit costs. Bollocks to their pandering 'job guarantee' or 'UBI'. We need an updated market socialism with public sector work fulfilling human needs.
2
6
22
467

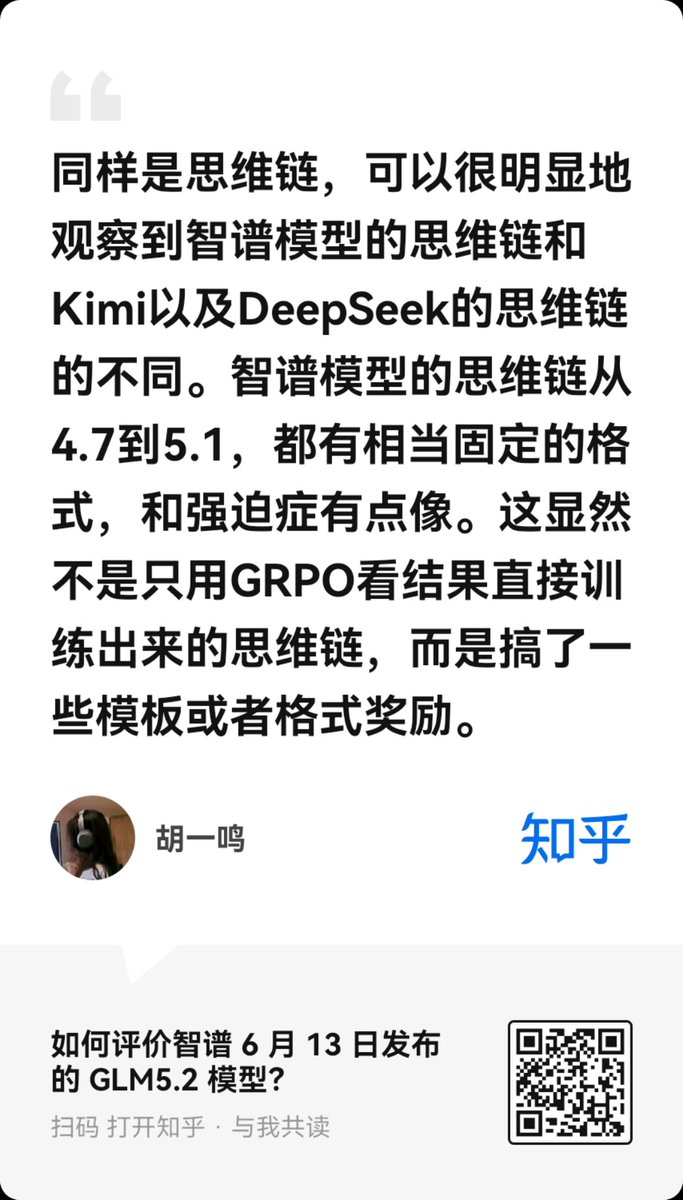
🧠 Why does GLM keep outperforming expectations with relatively modest parameter counts?
Zhihu contributor 胡一鸣 shares an interesting hypothesis about GLM-5.2.
⚡ The Puzzle
GLM models have consistently delivered strong results without relying on massive parameter advantages.
• GLM-4.7: 358B parameters
• GLM-5.1: 744B parameters
• Similar MoE architecture to DeepSeek-V3.x
• GLM-5.2 likely remains in the same ballpark
So where is the extra capability coming from?
Sure, data quality and training scale matter. But Hu proposes there may be something deeper.
🔍 The key difference may not be the model — but the reasoning process
Compared to DeepSeek or Kimi, GLM's Chain-of-Thought has a surprisingly consistent structure.
When given a long context, GLM tends to:
• Extract every key requirement
• Summarize each point explicitly
• Recursively compress and reorganize information
• Only then move on to solving the task
If the context is large enough, it may repeat this compression process multiple times before answering.
⚡ Chain-of-Thought as computation
This costs more tokens, but it's not wasted effort.
The core idea:
Chain-of-Thought isn't just explanation — it's additional compute.
For tasks that exceed what a Transformer can solve in a single forward pass, reasoning traces effectively increase computational depth.
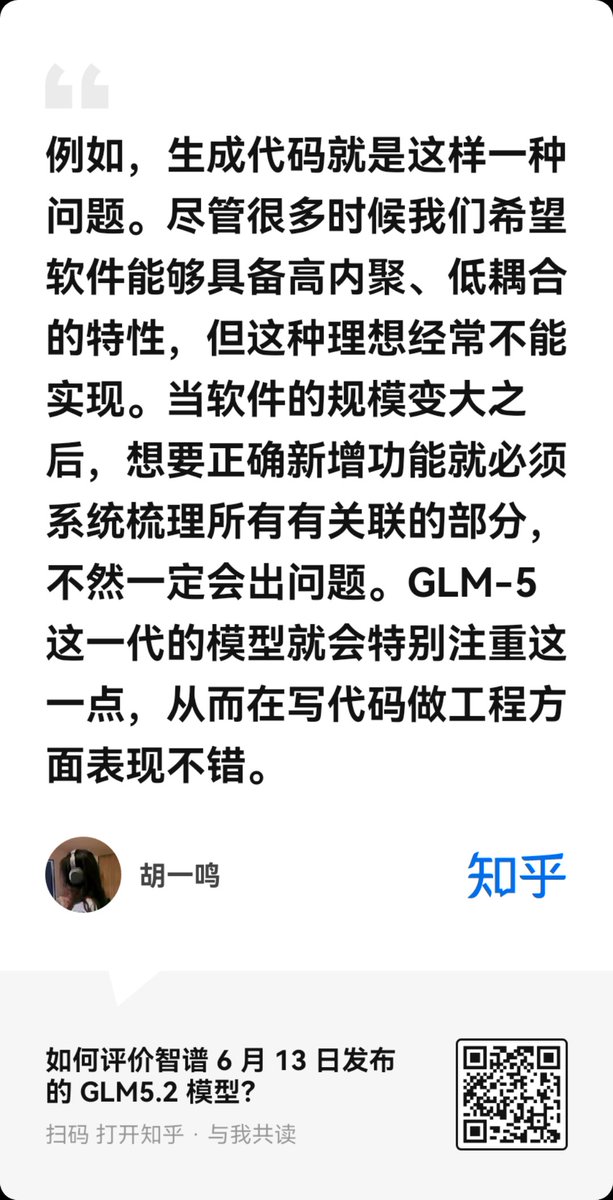
This is especially valuable for coding 👨💻
Large software projects require understanding dependencies across many files and modules. GLM-5.x appears unusually focused on systematically reviewing related components before making changes, which may explain its strong engineering performance.
📦 Compression, not expansion
Many reasoning models spend lots of tokens restating information.
GLM seems to do something different:
👉 Use reasoning to compress information.
Each round produces a smaller, more structured representation of the problem, helping the model maintain state and continue making progress.
🤖 A possible explanation
Hu's hypothesis is that GLM uses Chain-of-Thought almost like a temporary state register.
By storing intermediate summaries inside the reasoning process itself, the model can tackle tasks that would be difficult to solve in a single pass.
💡 The lesson from GLM-5.2 may not be "think longer."
It may be:
Organize information better. Compress before you reason.
🔗 Full answer:
zhihu.com/question/204916166…
#GLM52 #Zhipu #LLM #ChainOfThought #AI #Tech


3
198

This is exactly why format choice matters more than people realize. PDF is a presentation layer where AI has to reconstruct meaning from a visual snapshot.
A .docx file gives models structured, semantic content from the start: clean headings, real tables, actual metadata. At Microsoft Word we think about this deeply in that Copilot works with the document structure, not against it.
The lesson here isn't just "compress your PDFs"... it's that the file format is part of your AI workflow.

Everyone uploading PDFs to Claude is burning 70,000 tokens before asking a single question.
A 20-page document costs between 1,500 to 3,000 tokens per page.
Formatting. Broken tables. Images. Junk metadata. Claude processes all of it before you even type “summarize this.”
There’s a free fix. It’s called Markitdown.
Microsoft built it. 10,000 GitHub stars. Almost nobody in the Claude community is talking about it.
It converts any file PDFs, Word docs, Excel sheets, PowerPoints, YouTube videos into clean Markdown text.
Token usage drops by up to 70%.
Answers get better, not worse. Claude was trained on millions of Markdown documents. It reads the format natively. You’re not compressing quality you’re removing noise.
There’s an MCP server too.
Connect it to Claude Desktop once. Every file you upload auto-converts to .md before Claude touches it. You do nothing. It just works.
Old way: upload PDF → Claude burns 70k tokens on junk → mediocre answer
New way: Markitdown → clean .md → 70% fewer tokens → sharper answer
The tool is free. The MCP setup takes 10 minutes. The token savings are permanent.
You’ve been paying for Claude to read garbage. Stop.
7
SuneetMantri retweeted

Hot take:
AI led backtesting will just compress the sharpes for everyone, of almost all intraday systems to a level it becomes unviable to be trading MFT.
Solution: Go retardmaxxing.
14
1
72
7,556
Jon Sylt retweeted
Jun 14
"But rising wages can compress profit margins. As profits come under pressure, firms become more cautious. Investment slows." This is this the crux of it. Usury. Capital funds and leveraged creditors demanding consistently high returns. Workers and their communities will never be anything more than unit costs. Bollocks to their pandering 'job guarantee' or 'UBI'. We need an updated market socialism with public sector work fulfilling human needs.

The post-Keynesian growth cycle doesn't begin with central banks distorting a mythical natural interest rate. It begins with the normal functioning of capitalism itself.
Businesses invest because they expect profits. Investment creates income, income creates demand, and demand encourages further investment. Growth feeds on itself.
As the expansion continues, unemployment falls and labor markets tighten. Workers gain bargaining power. Wages begin rising faster as firms compete for scarce labor.
Higher wages are not a distortion. They are a predictable consequence of successful growth. But rising wages can compress profit margins. As profits come under pressure, firms become more cautious. Investment slows.
At the same time, businesses and households often turn to debt to maintain growth. Banks are eager to lend because recent success makes risk appear low. Credit expands, asset prices rise, and optimism becomes self-reinforcing.
The longer stability persists, the more fragile the system becomes.
What began as productive investment gradually shifts toward speculation. Rising debt commitments require continued growth to remain sustainable. The economy becomes increasingly dependent on expectations that cannot all be fulfilled.
Then reality intervenes. A slowdown in profits, rising debt burdens, falling asset prices, or declining investment can trigger a wave of deleveraging. Spending falls. Layoffs begin. Income declines. The boom turns into a bust.
The crisis was not caused by an external distortion imposed on an otherwise stable system.
The boom itself created the conditions for the bust.
This was the insight of Richard Goodwin. It was the insight of Hyman Minsky and formalized by @ProfSteveKeen Cycles emerge from the interaction of wages, profits, investment, employment, and debt.
Capitalism does not require policy mistakes to become unstable.
Its internal dynamics are often enough.

12
45
126
5,407