

What I was thinking more about is constructing the weights in a moe block xₒᵤₜ = 𝒇(xᵢₙ) = ∑_{top-k} 𝒘ᵢ( xᵢₙ ) FFNᵢ( xᵢₙ ) such that 𝒇 is continuous, including across expert switches. There are things like DSelect-k, but I have barely seen anything useful
2
2
41

Apr 7
Yes, I also started with Slackware in 1994. It was simple and straightforward, but it didn't have any dependency management whatsoever, so that's not really a good example.
Debian dpkg and dselect were a huge improvement.
4
186

18 Oct 2025
コマンドベースなのにGUIみたいなGitツール
昔愛用してたDebianのdselectコマンドみたい
zenn.dev/aishift/articles/d1…
> マウス不要!Git 操作を爆速化する「lazygit」が手放せない
1
2
170



18 Mar 2025
Super Saver Deal
DSelect by Dell DS111 Wired Optical Mouse (USB 2.0, Black)
Rs. 169
fkrt.co/ApFeiG

3
8
399
21 Jan 2025
DSelect by Dell DS111 Wired Optical Mouse (USB 2.0, Black)
₹199/-
fkrt.co/Rm8qIA

3
8
307

21 Jul 2024
BTW, the desktop is on testing, while the server is on stable. And the command is apt full-upgrade (we were using dselect when we started, follow by apt-get and apt). Always able to upgrade, even during the libc5 to libc6 transition. Full disclosure: I was Debian Dev back then.
1
2
49


25 Mar 2024
Firewall restricted to my remote access IP until I finish setup
"PermitRootLogin no" and "PasswordAuthentication no" into local sshd config
apt update && apt upgrade && apt dist-upgrade && apt autoremove
apt install debfoster dselect sudo && debfoster -q
6
967

11 Mar 2024
14
1,599

11 Mar 2024
Canonical 20 年かー。Ubuntu のおかげで Debian もいろいろ変わったというか、sarge の時みたいにリリース遅れなくなったしインストーラーも使いやすくなったしな。dselect と格闘させられていたのが懐かしいw
1
2
227

14 Jan 2024
I'm thinking of doing either a webinar or a blog post called "All about MoEs". Would this be interesting? Which format? Which other topics should I include?
Topics that could be covered:
- What are sparse models and MoEs?
- Sparsely activated MoEs and Top-k gating
- MoEs and transformers
- Load balancing
- Overview of OS MoEs (Mixtral, Switch Transformer, OpenMoE)
- Quantization and MoEs
- What is an "expert"?
- Expert parallelism and why MoEs are interesting for pre-training
- MoEs for local usage vs high usage deployment
- Challenges of fine-tuning MoEs
- DeepSeekMoE
- How to compare MoEs to dense models?
- Training MoEs from dense checkpoints
- Model merging and MoE merges
Papers to cover: Outrageously Large NN (2017), ZeRO (2019), GShard (2020), GLaM (2021), DSelect-k (2021), Hash Layers (2021), BASE layers (2021), Switch Transformers (2022), ST-MoE (2022), FasterMoE (2022), MegaBlocks (2022), A Review of Sparse Expert Models (2022), Unified Scaling Laws for Routed Language Models (2022), Sparse Upcycling (2022), Mixture-of-Experts Meets Instruction Tuning (2023), QMoE (2023), Mixtral (2023), DeepSeekMoE (2024)
17
9
202
26,388


10 Sep 2023
Great article covering six papers on Mixture of Experts, of which one is ours 🙂 (DSelect-K with @hazimeh_h, @achowdhery, and others): arxiv.org/abs/2106.03760
9 Sep 2023

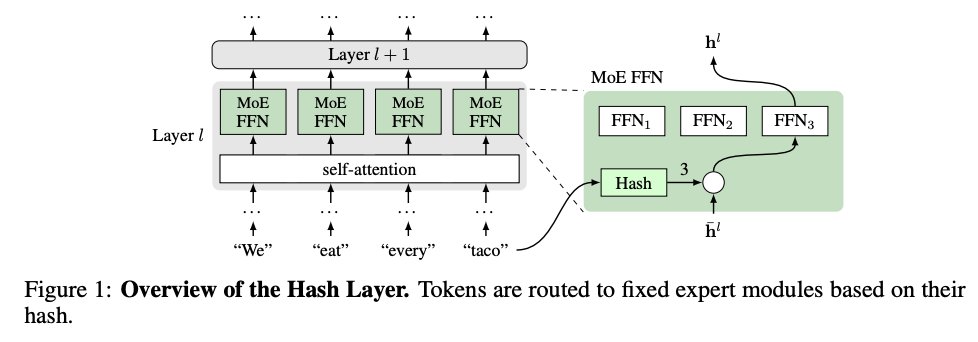
my article about MoE routing layers is out!
I took it down to 6 routing papers:
1
10
75
15,253

5 Sep 2023
4. Differentiable Select-K, which is a fully differentiable version of the standard sparsely gated MoE layer (arxiv.org/abs/1701.06538).
DSelect-K: arxiv.org/abs/2106.03760
1
1
3
266

12 Jun 2023
It’s not suppose to be perfect. It’s a process over time. That’s the fun part, watching the development. It’s the journey! DSelect Year 16. #ProcessDriven #KhakiCulture #TxLaxCo




9
2,794


11 Dec 2022
Una vecchia fortune recita:
Ubuntu in Zulu significa "non so usare Debian" 😜
Anche se, essendo passato da quello Istrumento di Lu Dimoniu chiamato dselect, potrei leggermente dissentire 😅😅
2