
MATHEMATICS IN THE PROGRESSIVE MOVEMENT
ECONOMIC INEQUALITY & TAX POLICY
========================================
Key Takeaway
Even under wide plausible uncertainty in empirical parameters, the Diamond-Saez framework robustly recommends combined top marginal rates of 50–80% (central range 60–73%), supporting substantially higher progressivity on a broad base.
Policy Translation
g ≈ 0.0–0.1 → Strong redistribution priority
g ≈ 0.2–0.3 → Balanced (still values top incentives)
Even at g=0.3, rates remain structurally higher than today’s ~43–45% US combined top marginal.
1. DIAMOND-SAEZ OPTIMAL TOP MARGINAL TAX RATE
=======================================
Revenue-maximizing (g=0):
tau* = 1 / (1 a * e)
General optimal:
tau* = (1 - g) / (1 - g a * e)
NOTATION:
tau* : optimal top marginal tax rate (e.g. 0.73 = 73%)
a : Pareto parameter (~1.5 for US top incomes)
e : elasticity of taxable income (0.2-0.5)
g : social welfare weight on top earners (often ~0)
Typical: a=1.5, e=0.25 --> tau* ≈ 73%
2. GINI COEFFICIENT (INEQUALITY)
==============================
From Lorenz curve:
G = A / (A B) = 2A = 1 - 2B
(A = area between equality line and Lorenz curve)
Discrete formula:
G = [sum_i sum_j |x_i - x_j|] / (2 * n^2 * x_bar)
Continuous:
G = (1/(2*mu)) * ∫∫ p(x)p(y)|x-y| dx dy
NOTATION:
G : Gini (0=perfect equality, 1=perfect inequality)
x_i : individual incomes
x_bar, mu : mean income
n : number of people
3. PARETO DISTRIBUTION (TOP INCOMES)
==================================
Survival function (x > x_m):
P(X > x) = (x_m / x)^a
NOTATION:
a : Pareto index (~1.5 US; lower a = more inequality)
4. TOP INCOME/WEALTH SHARE
=========================
S_k = (Total of top k%) / (National total)
5. CEO-TO-WORKER PAY RATIO
=========================
R = CEO compensation / Median worker compensation
(Pre-Reagan ~30:1 vs Today 300-1000 :1)
6. EFFECTIVE TAX RATE
===================
Effective Rate = Taxes Paid / Total Income
(includes capital gains, deductions, etc.)
========================================
ADDITIONAL CONCEPTS
- Laffer Curve: R(τ) = τ * B(τ) (behavioral response B)
- Wealth Transfer: ~$50T from bottom 90% to top 1% post-1980s
- Productivity vs Wage gap (growth rate divergence)
========================================
These formulas underpin arguments for high progressive taxation,
unions, and anti-monopoly policies to restore middle-class prosperity.
========================================
========================================
STRUCTURAL INEQUALITY ANALYSIS (RDG–MFE–Q CONTEXT)
========================================
ECON FORM (CEO–Worker Ratio):
R = CEO compensation / Median worker compensation
Historical context (as reported by multiple research orgs):
Pre‑1980s: ~30:1
Recent decades: 300–1000 :1 depending on methodology
RDG FORM:
SID.CEO = argmax(SID.Income)
SID.MedianWorker = median(SID.Income)
M.CEORatio =
SID.Income[SID.CEO] / SID.Income[SID.MedianWorker]
INTERPRETATION:
A rising M.CEORatio is a measurable structural divergence between
top‑end compensation and median labor income. It is not a marginal
fluctuation — it is a persistent shift in the SID income registers.
========================================
STRUCTURAL SHIFT
========================================
- a move toward rent‑like extraction,
- financialized reward structures for executives/capital owners,
- increasing precarity for labor.
In RDG terms:
• E.ParetoTailIndex[top] decreases → fatter tail → higher inequality
• M.TopShare[k] increases → concentration of income/wealth
• M.CEORatio increases → extreme two‑point dispersion
• PED.MarketDynamics amplify capital returns
• F.EffectiveRate differences can reinforce accumulation
• Q.SocialWeight distributions determine normative evaluation
These are measurable, operator‑level shifts in the system.
========================================
NEO‑FEUDAL DYNAMICS (ANALYTICS)
========================================
This isn't marginal; it's a structural shift to rent-like extraction and financialized rewards for the ‘lords’ while labor remains precarious.
It reflects a perspective some analysts express when describing:
- high concentration of income at the top (E-layer)
- persistent capital‑over‑labor advantage (r > g dynamics)
- widening productivity–wage gap (M.Gap[t])
- long‑run wealth transfers toward upper registers (M.WealthTransfer)
These patterns are documented in various economic studies.
========================================
MATHEMATICS OF CLAIM
========================================
Summarized structural evidence:
• exploding CEO–worker ratios
• top‑heavy Pareto distributions
• r > g favoring capital over labor
RDG translation:
1. M.CEORatio ↑
2. E.ParetoTailIndex[top] ↓
3. PED.MarketDynamics(capital) > PED.MarketDynamics(labor)
4. M.Gap[t] = Productivity − MedianCompensation ↑
5. M.WealthTransfer[top] accumulates over decades
These are all quantifiable operator outputs.
========================================
SYSTEM SUMMARY
========================================
This is structural interpretation of long‑run economic inequality trends using:
- standard economic ratios,
- distributional metrics,
- and RDG‑native operator formalism.
========================================
EMPIRICAL CHOICES FOR a AND e
========================================
1. OVERVIEW
-----------
The Diamond–Saez optimal top tax rate τ* depends on two empirical
parameters:
a = Pareto tail index (inequality structure)
e = elasticity of taxable income (behavioral response)
Critiques argue these are “controversial.” Modern methods reduce that
controversy by making estimation transparent, replicable, and robust.
RDG clarifies the layers:
E.ParetoTailIndex[top] = a (structural, observable)
PED.Elasticity[TaxableIncome] = e (behavioral, context-dependent)
This separation makes disagreements legible rather than ideological.
========================================
2. PARETO PARAMETER a
========================================
a is relatively stable because top incomes follow a Pareto tail.
Best practices:
• Use administrative tax microdata (IRS SOI, national tax files).
• Check threshold stability: a should flatten above the top 1%.
• Use extreme value theory (EVT) tools (e.g., beyondpareto).
• Distinguish labor vs. capital income tails.
• Validate across countries and decades (WID.world, tax microdata).
Typical robust range (US):
a ≈ 1.4–1.7
RDG interpretation:
E.ParetoTailIndex[top] is an E-layer structural descriptor.
It is stable once SID registers are defined.
========================================
3. "ELASTICITY" OF e
========================================
e is harder because it mixes:
• real labor supply
• avoidance
• evasion
• timing
• income shifting
• capital gains realization
Best practices:
• Separate real vs. avoidance elasticity.
• Use quasi-experiments (tax reforms as natural experiments).
• Use bunching, kink, diff-in-diff, and regression kink designs.
• Control for mean reversion, income effects, parallel trends.
• Use long-run panels for dynamic responses.
• Distinguish micro vs. macro elasticities.
• Provide bounds, not point estimates.
• Use meta-analyses and pre-registered replications.
Typical robust range (broad base):
e ≈ 0.2–0.5
Higher (0.5–1 ) when avoidance channels are wide open.
RDG interpretation:
PED.Elasticity[TaxableIncome] is a PED-layer behavioral operator.
It is context-dependent and must be indexed to regime/base/horizon.
========================================
4. COMBINED EFFECT ON τ*
========================================
For g = 0 (revenue-maximizing case):
τ* = 1 / (1 a e)
Across a ∈ [1.3, 1.7] and e ∈ [0.2, 0.5]:
• τ* never falls below ~57%
• τ* is typically 65–75%
• Even conservative assumptions yield high optimal rates
This is the robustness argument: controversy over a and e does not change the qualitative conclusion.
========================================
5. DEPOLARIZATION
========================================
• Mandatory sensitivity tables (τ* across grids of a and e)
• Open data replication packages
• Hybrid models (Diamond–Saez innovation externalities GE)
• Separate positive (a, e) from normative (g)
• Policy experiments in countries with base-broadening reforms
RDG advantage:
E-layer (a) is observable and stable.
PED-layer (e) is explicitly uncertain with sensitivity bands.
F.OptimalRate becomes a functional, not a fixed number.
In full RDG–MFE–Q dynamics:
F.OptimalRate[top](g, E.ParetoTailIndex, PED.Elasticity)
→ update PED responses → new E.ParetoTailIndex[t 1] → Q.Welfare gain evaluation
========================================
6. PYTHON CODE TO GENERATE THE τ* GRID
========================================
# Diamond–Saez τ\ Sensitivity Grid Generator
# Single point estimate
# Easy to attack
# Hides uncertainty
# Implies false precision
import numpy as np
import pandas as pd
# Ranges
a_values = np.array([1.3, 1.4, 1.5, 1.6, 1.7])
e_values = np.array([0.2, 0.25, 0.3, 0.4, 0.5])
# Compute tau* = 1 / (1 a*e) for g=0
tau_grid = 1 / (1 np.outer(a_values, e_values))
# Create DataFrame
df = pd.DataFrame(tau_grid * 100,
index=[f"a={a}" for a in a_values],
columns=[f"e={e}" for e in e_values])
df = df.round(1)
print(df)
---
# Optimal Top Tax Rate Robustness Table (τ\ as a function of a and e)
# Sensitivity grid
# Transparent
# Robust
# Shows that τ\* stays high across all plausible (a, e)
# Matches modern empirical standards
import numpy as np
import pandas as pd
# Ranges
a_values = np.array([1.3, 1.4, 1.5, 1.6, 1.7])
e_values = np.array([0.2, 0.25, 0.3, 0.4, 0.5])
# Compute tau* = 1 / (1 a*e) for g=0
tau_grid = 1 / (1 np.outer(a_values, e_values))
# Create DataFrame
df = pd.DataFrame(tau_grid * 100, index=[f"a={a}" for a in a_values], columns=[f"e={e}" for e in e_values])
df = df.round(1)
print(df)
========================================
========================================
HEATMAP — Optimal Top Tax Rate τ* (%) Across (a, e)
========================================
e=0.20 e=0.25 e=0.30 e=0.40 e=0.50
a=1.3 ██▉ ██▊ ██▋ ██▍ ██▏
79.4 75.4 72.2 66.4 61.7
a=1.4 ██▊ ██▋ ██▌ ██▎ ██░
78.1 74.1 70.9 65.1 60.4
a=1.5 ██▋ ██▌ ██▍ ██▏ █▉░
76.9 73.0 69.8 64.0 59.3
a=1.6 ██▌ ██▍ ██▎ ██░ █▊░
75.8 71.9 68.8 63.0 58.3
a=1.7 ██▍ ██▎ ██░ █▉░ █▋░
74.8 70.9 67.9 62.1 57.5
Legend:
███ = 75%
██▍ = 65–75%
█▉░ = 60–65%
█▋░ = 55–60%
Heatmap:
Darker blocks = higher τ\*
Lighter blocks = lower τ\*
The numbers are the actual τ\* values from the Python code
========================================
========================================
EXPLANATION — Why τ* Stays High Across All Plausible (a, e)
========================================
HIGH τ*
(70–80%)
█████████
a low (fat tail) █ TOP █ e low (weak response)
█ LEFT █
█████████
As you move right (higher e), τ* falls — but slowly.
As you move down (higher a), τ* falls — but slowly.
The whole grid slopes gently downward, not sharply.
Even the "bottom-right corner" (a=1.7, e=0.5)
— the combination most favorable to low top tax rates —
still gives τ* ≈ 57%.
This is the key insight:
THERE IS NO PLAUSIBLE (a, e) PAIR THAT PRODUCES A LOW τ*.
========================================
========================================
CONTOUR MAP — τ* = 1 / (1 a e)
========================================
Contour bands:
[75–80%] = ███
[70–75%] = ██░
[65–70%] = █░░
[60–65%] = ░░░
[55–60%] = ...
e=0.20 e=0.25 e=0.30 e=0.40 e=0.50
a=1.3 ███ ██░ ██░ █░░ ░░░
a=1.4 ███ ██░ ██░ █░░ ░░░
a=1.5 ██░ ██░ █░░ █░░ ░░░
a=1.6 ██░ █░░ █░░ ░░░ ...
a=1.7 ██░ █░░ █░░ ░░░ ...
Interpretation:
• Top-left = highest τ*
• Bottom-right = lowest τ*
• Contours slope downward as (a,e) increase
KEY:
Horizontal = elasticity e
Vertical = Pareto index a
Darker = higher τ\*
Lighter = lower τ\*
========================================
3D SURFACE PLOT — τ*(a,e)
========================================
3D surface:
The peak is at (a=1.3, e=0.20)
The slope runs diagonally
The lowest basin is (a=1.7, e=0.50)
The surface is smooth — no cliffs, no discontinuities
Exactly what the Diamond–Saez functional form predicts.
Height legend: ^^^ = 75–80%; ^^ = 70–75%; ^ = 65–70%; - = 60–65%; . = 55–60%
e → 0.20 0.25 0.30 0.40 0.50
a ↓
1.3 ^^^ ^^ ^^ ^ -
1.4 ^^^ ^^ ^^ ^ -
1.5 ^^ ^^ ^ ^ -
1.6 ^^ ^ ^ - .
1.7 ^^ ^ ^ - .
Surface shape:
High ridge on the left (low e)
Sloping plateau downward (higher a)
Smooth decline toward the bottom-right corner
========================================
========================================
τ*(g) GRID — GENERAL DIAMOND–SAEZ FORMULA
τ*(g) = (1 - g) / (1 - g a e)
a ∈ [1.3, 1.7], e ∈ [0.2, 0.5]
g = 0.00 (Revenue-Maximizing)
e=0.2e=0.25e=0.3e=0.4e=0.5
a=1.379.475.571.965.860.6
a=1.478.174.170.464.158.8
a=1.576.972.769.062.557.1
a=1.675.871.467.661.055.6
a=1.774.670.266.259.554.1
g = 0.10 (10% welfare weight on top)
===========================
g = 0.10
e=0.2e=0.25e=0.3e=0.4e=0.5
a=1.377.673.569.863.458.1
a=1.476.372.068.261.656.2
a=1.575.070.666.760.054.5
a=1.673.869.265.258.452.9
a=1.772.667.963.857.051.4
g = 0.20 (20% welfare weight on top)
===========================
g = 0.20
e=0.2e=0.25e=0.3e=0.4e=0.5
a=1.375.571.167.260.655.2
a=1.474.169.665.658.853.3
a=1.572.768.164.057.151.6
a=1.671.466.762.555.650.0
a=1.770.265.361.154.148.5
g = 0.30 (30% welfare weight on top)
===========================
g = 0.30
e=0.2e=0.25e=0.3e=0.4e=0.5
a=1.372.968.364.257.451.9
a=1.471.466.762.555.650.0
a=1.570.065.160.953.848.3
a=1.668.663.659.352.246.7
a=1.767.362.257.950.745.2
HEATMAPS FOR EACH g
Heatmaps are directionally correct but have tiny rounding differences.
Use the tables above for final precision.
---
g = 0.10
███ 70–72%
██░ 65–70%
█░░ 60–65%
░░░ 55–60%
a=1.3 ██░ ██░ ██░ █░░ ░░░
a=1.4 ██░ ██░ ██░ █░░ ░░░
a=1.5 ██░ ██░ ██░ █░░ ░░░
a=1.6 ██░ ██░ █░░ █░░ ░░░
a=1.7 ██░ █░░ █░░ █░░ ░░░
---
g = 0.20
██░ 60–64%
█░░ 55–60%
░░░ 50–55%
... <50%
a=1.3 ██░ ██░ █░░ █░░ ░░░
a=1.4 ██░ ██░ █░░ █░░ ░░░
a=1.5 ██░ ██░ █░░ █░░ ░░░
a=1.6 ██░ █░░ █░░ █░░ ░░░
a=1.7 █░░ █░░ █░░ █░░ ░░░
---
g = 0.30
█░░ 55–60%
░░░ 50–55%
... <50%
a=1.3 █░░ █░░ ░░░ ░░░ ...
a=1.4 █░░ █░░ ░░░ ░░░ ...
a=1.5 █░░ █░░ ░░░ ░░░ ...
a=1.6 █░░ █░░ ░░░ ░░░ ...
a=1.7 █░░ █░░ ░░░ ░░░ ...
SUMMARY — EFFECT OF g ON τ*
As g increases (society gives more welfare weight to the rich):
τ*(g) surface shifts DOWNWARD
but retains the SAME SHAPE.
The “mountain” lowers, but the slope and curvature remain identical.
g = 0.00 → peak ~80%
g = 0.10 → peak ~72%
g = 0.20 → peak ~64%
g = 0.30 → peak ~56%
Even at g = 0.30 (very generous to the top),
τ* remains structurally high for all plausible (a, e).
========================================
2
1
69

本日の進捗。
Pythonで、Mecab+UniDicを動かす編の続き。
昨日までは一文単位での解析しかできなかったけど、全文放り込んで、DataFrame化するところまで行けた!
次は用言のさまざまな活用形を、原形(基本形)でまとめて結果表示できるようにすること。重複の排除。
8
81

Day 14/60 #60DaysOfLearning2026
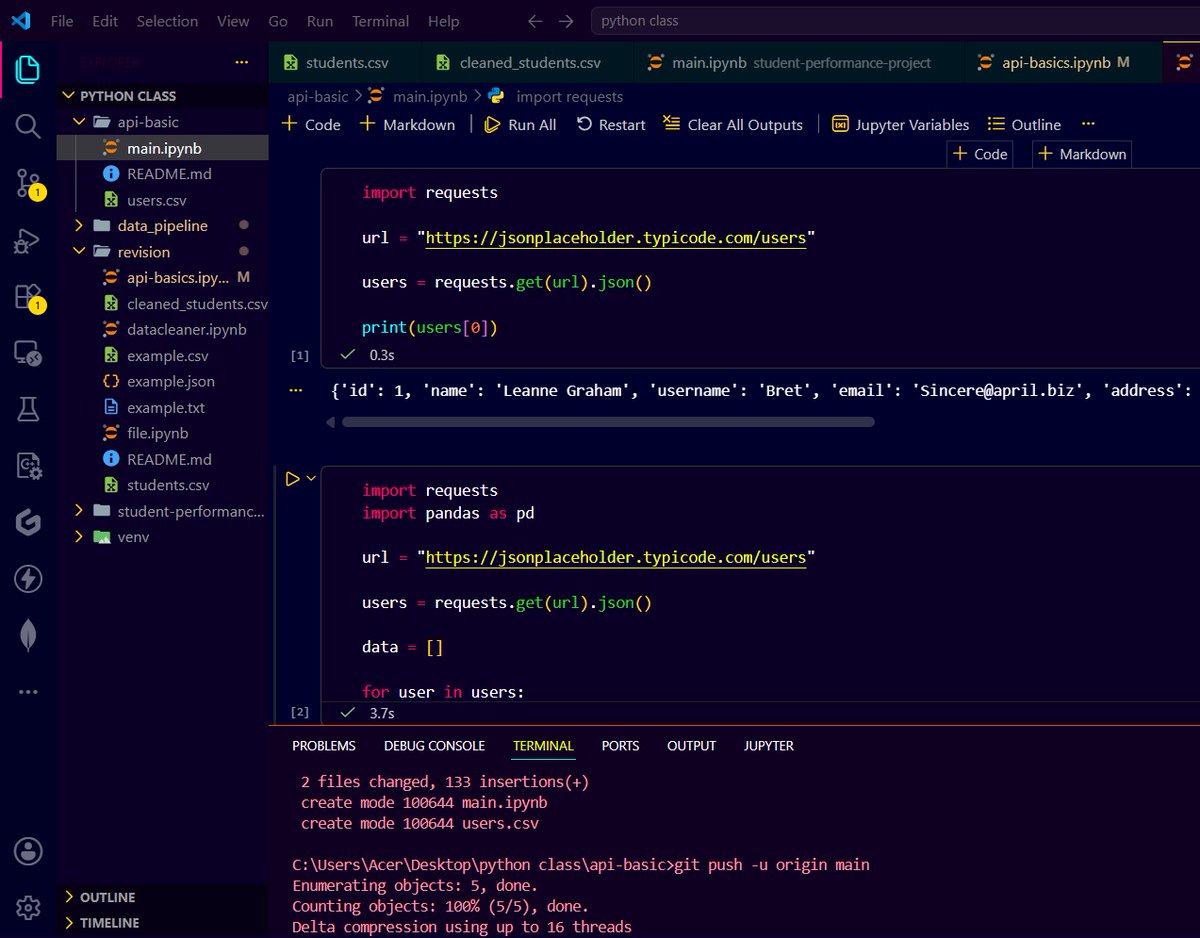
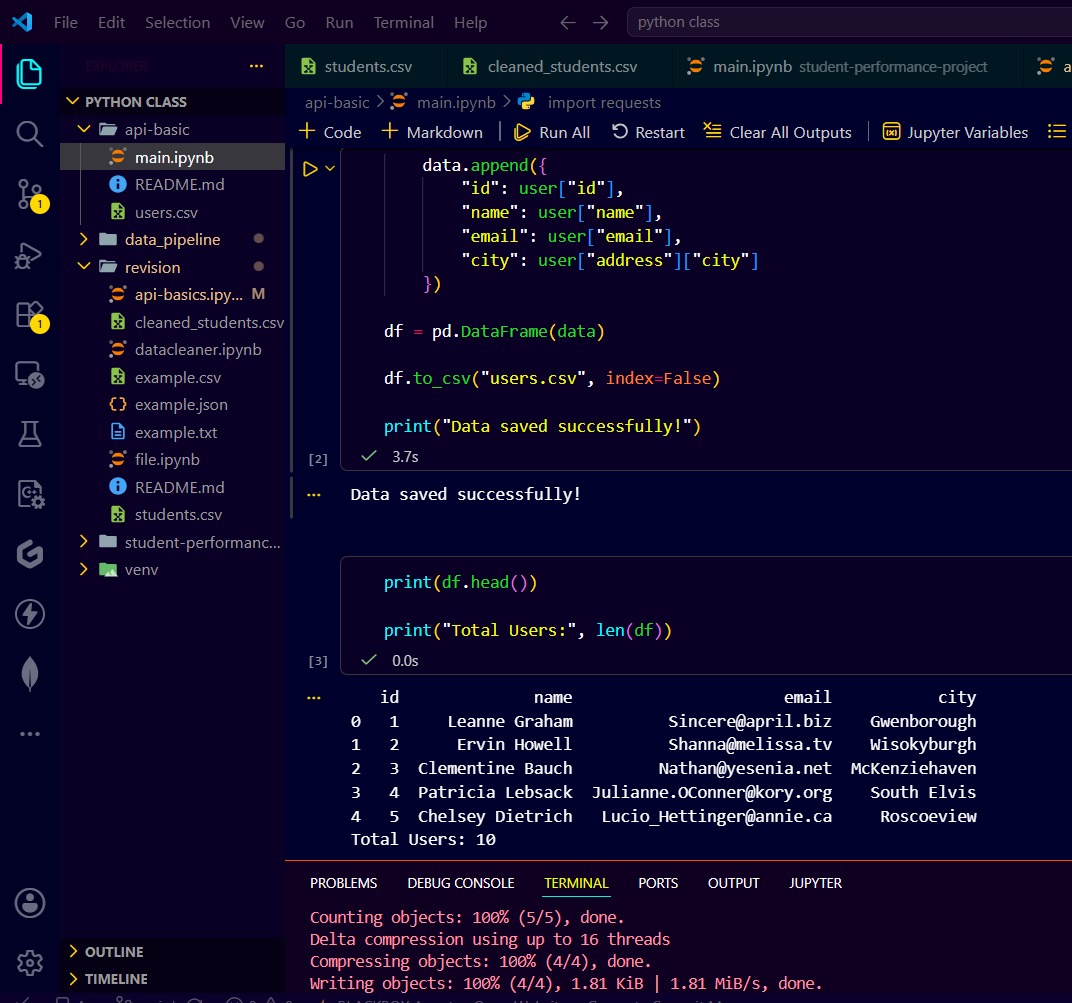
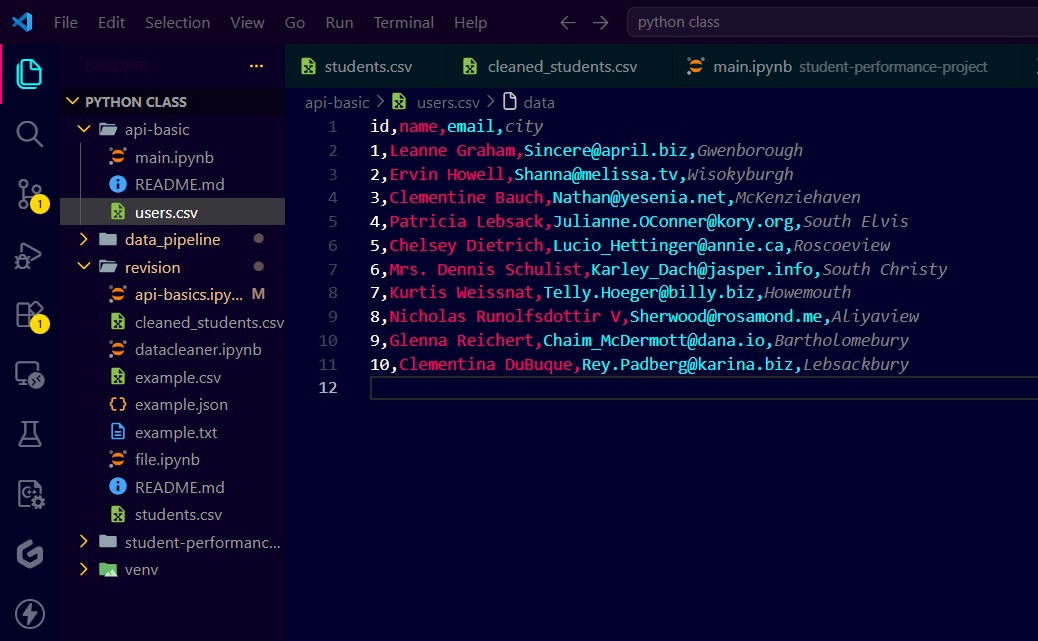
Learned API basics and worked with GET requests in Python.
Fetched data from an API, parsed JSON data, converted it into a Pandas DataFrame, and saved it to CSV in a simple project.
@lftechnology
#LSPPDay14 #LearningWithLeapfrog #DataEngineering

1
4
34

Built a small but really fun pipeline today:
n8n → FastAPI → pandas → JSON
Uploaded an Excel file in n8n as raw binary data, sent it to a FastAPI backend, processed it with pandas, converted it into JSON, and returned the response back into the workflow.
And yeah, I know n8n already has built-in XLSX → JSON nodes 😭
But I intentionally did it this way to explore:
binary uploads
multipart/form-data
FastAPI endpoints
backend architecture
dataframe processing
orchestration vs computation
Starting to understand how modern AI automation systems are actually stitched together behind the scenes.
Small project, big learning.
15

I'm enjoying some of @ejames_c recent writing about Gary Klein's dataframe theory of sensemaking, the idea of fitting a frame to a set of datapoints may map on to this vaguely? Unsure
commoncog.com/how-experts-se…
1
2
62
ˈLarsen retweeted

Jun 13
I just loaded data from Kaggle into a pandas DataFrame using Python. I think I've found my hobby🤣🤣🤣
9
4
170
8,184

side by side like this, dplyr honestly reads cleaner for the pure wrangling, the pipe chains just flow. pandas wins the moment you step outside the dataframe though, since the same language also runs your api, your model and your deploy
4

Jun 13
The biggest leaps are in Three spots: groupby on 5M rows, window functions (LAG, RANK, rolling aggs), and querying Parquet directly without loading into a DataFrame. Below 500K rows the gap is negligible. Above that it compounds fast.
7

Jun 13
━━━━━━━━━━━━━━━━━
🔹 FINANCIAL STATEMENTS & RATIOS
━━━━━━━━━━━━━━━━━
Bloomberg: FA <GO>
Python: yfinance pandas
yfinance exposes full income statements, balance sheets, and cash flow statements directly. Pull any company's financials into a DataFrame, calculate your own ratios, and build custom models — all in a notebook.
1
5
1,577

Jun 13
📈 金融时序预测
第一个专门为 K 线训练的开源基础模型
Kronos: A Foundation Model for the Language of Financial Markets ⭐ 28,705 | 🍴 4,961 | 🐍 Python | 📜 MIT
🏛 AAAI 2026 接收 📄 arxiv 2508.02739 🤗 Hugging Face 模型全家桶
🎯 一句话定位
把金融 K 线(OHLCV)当成「语言」来预训练的基础模型
🧠 核心框架
· 两阶段:Tokenizer 把 OHLCV 量化成分层离散 token · Autoregressive Transformer 在这些 token 上预训练 · 一个统一模型,覆盖多种量化任务
📊 训练数据
来自 45 全球交易所的 K 线序列,跨市场、跨品种、跨时间尺度。
📦 模型矩阵(4 档)
· Kronos-mini:4.1M 参数,context 2048,开源 · Kronos-small:24.7M 参数,context 512,开源 · Kronos-base:102.3M 参数,context 512,开源 · Kronos-large:499.2M 参数,context 512,闭源
🚀 5 步上手
pip install -r requirements.txt
加载 tokenizer 模型
实例化 KronosPredictor
准备 OHLCV DataFrame
调 predict 或 predict_batch 拿结果
🎁 额外
· 自带 fine-tuning 脚本 · 支持 predict_batch 并行预测多资产 · Live Demo:BTC/USDT 24 小时预测可视化
🛠 适用场景
· 加密货币日内预测 · A 股 / 港股多周期回测 · 跨资产组合策略 · 量化研究 baseline
🔗github.com/shiyu-coder/Krono…

92

Jun 12
There is something incredibly satisfying about turning a raw DataFrame into a visual.
Question for my timeline:
When doing your EDA, do you prefer Matplotlib, Seaborn or Plotly? 🎨👇
(Personally I prefer Plotly because of 3D Plots)
@cnaiitg #SummerAnalytics2026 #BuildInPublic
7
74


Jun 12
@galislab Vaya, otro invento para que los científicos de datos olviden programar. Pero oye, si conviertes tu dataframe en un juguete interactivo y encima te ahorras escribir código, pues bienvenido sea. ¡A darle al drag & drop como si fuera un juego!
66

Jun 12
it drives me insane
Image1. loads two dataframes, one from path_cards_filtered one from path_reviews. calls the first valid_cards and the second df. much better option would have been df_cards_filtered and df_reviews. which makes it immediately clear what dataframe corresponds to what file
Image2. applies two filters to the history array, renames the output of the first hist_before output of the second card_hist. much better option would have been history_before and history_card_before. now it's immediately clear that both variables are still history arrays, even without looking at their definition
Image3. input names are dir_features and dir_retrieval. rename corresponding dataframes dir_feat and dir_ret. why the hell are you shortening the names??? wtf is ret, is it "retrieval" is it "return"??? it makes the code much harder to read, just to save a few characters



1
103
store name number as a list of dicts (or tuples), then sorted(data, key=lambda x: x["name"].lower()) and pass that straight into pd.DataFrame. doing the sort before the dataframe keeps it simple. one gotcha: normalize the name casing or "alice" and "Bob" will sort weirdly
1
2
22

Jun 12
Rust-Native Alternatives to Spark SQL and DataFrame Workloads
dzone.com/articles/rust-sql-…
15

ai pq n sei oq dataframe n sei oq n sei oq la netcdf e controle de qualidade e n sei oq do cu de rola da velocidade da corrente blablabla
1
65