
@ProbogotaRegion , @transparenciaco, @FEDe_Colombia_ y @Datasketch lanzaron Rayos X, una herramienta que utiliza inteligencia artificial y reconocimiento facial para identificar a los candidatos a la Cámara por Bogotá.
Conócela: infoelecciones.co/rayosx


1
2
130

🩻 Hoy lanzamos Rayos X, una herramienta con inteligencia artificial para escanear a los candidatos a la @CamaraColombia por Bogotá.
Es una iniciativa conjunta de @ProbogotaRegion, @transparenciaco, @Datasketch y @FEDe_Colombia_ para poner a disposición de la ciudadanía información clave antes de votar este 8 de marzo de 2026.
📸 Escanee una foto o búsquelo por nombre y conozca:
✔️ Investigaciones activas
✔️ Financiación de campaña
✔️ Propuestas para Bogotá
✔️ Su posición frente a la Constituyente
Antes de poner la X en la urna 🗳️, pásele los Rayos X a su candidato o candidata.
👉 Conoce aquí nuestra herramienta infoelecciones.co/rayosx

1
4
12
451

Datasketch 1.8.0 is out today!
Since my last post calling for collaborators, many developers stepped up and delivered incredible improvements. I want to highlight and thank them (ordered by first name):
Arham Khan (GH: 123epsilon) introduced LSHBloom, a new MinHash index built on Bloom Filters that dramatically reduces space usage compared to traditional MinHash LSH.
Bhimraj Yadav (@bhimrazyadav, GH: bhimrazy) modernized the entire build CI using uv, enabling releases directly from GitHub and making numerous quality-of-life improvements to our development workflow.
Dipesh Babu (@dipesh1701, GH: dipeshbabu) contributed GPU-accelerated MinHash batch updates. On 256 permutations with a batch size of 50,000, this delivers a 5× speedup—a huge win for large-scale data processing.
Varun Edachali (GH: Varun0157) added robust integration tests, fixed a long-standing Cassandra storage bug related to non-string key serialization, and introduced MinHashDeleteSession for batch deletion.
I’m incredibly grateful to everyone who contributed this month. This is open source at its best.
1
2
335
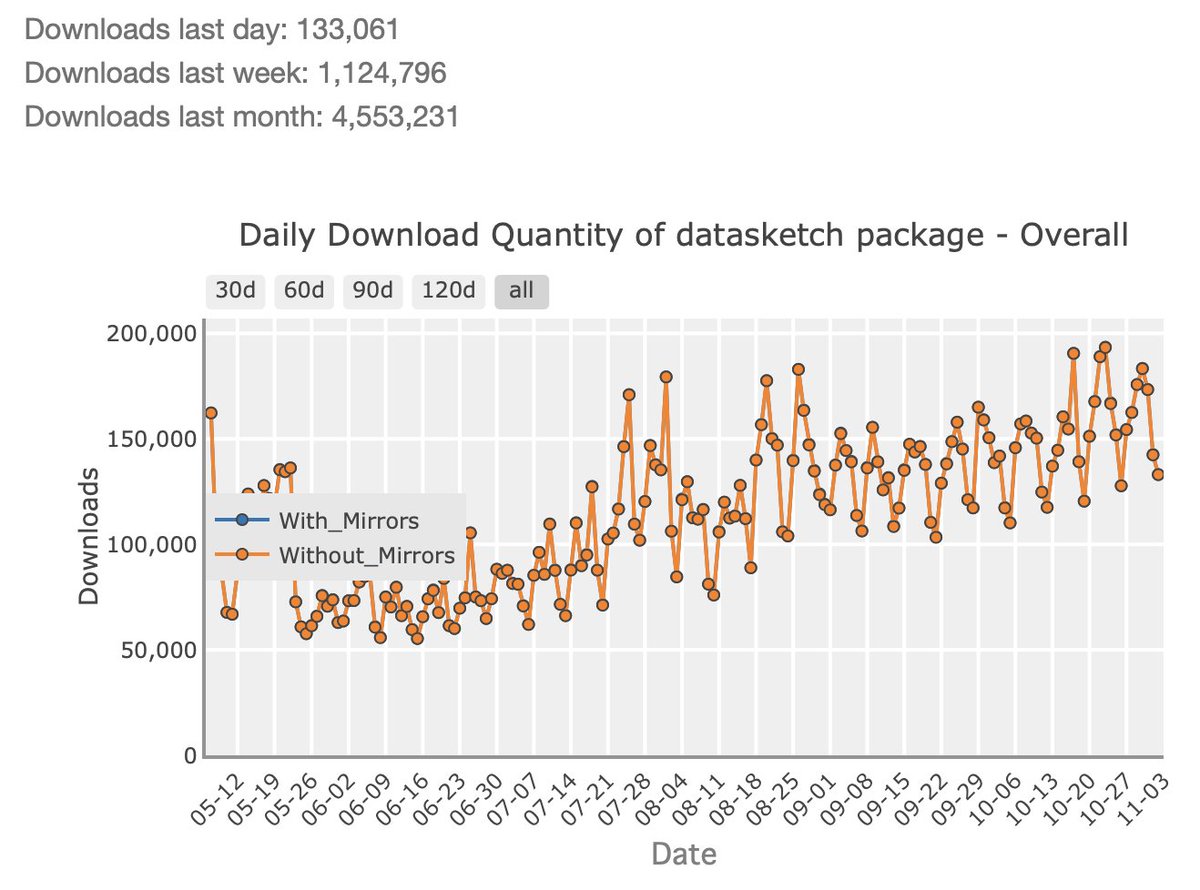
Looking for open-source collaborators for the datasketch project (2.8K stars, 4.5M monthly downloads).
I created datasketch (github.com/ekzhu/datasketch) 10 years ago to open source the code I wrote for my PhD work in dataset search. Now, it is downloaded 4.5M times per month on PyPI -- driving about 1% of all numpy downloads. At this point, datasketch is a foundational block of the Python ecosystem. It is used in many scenarios like content filtering, document similarity search, and data deduplication in LLM pre-training.
There are several things I think would be good for the project:
- Modernize the build using pyproject setup and uv
- Async API for indexes
- Refactor the storage backend abstraction to better support batch loading directly from disk file utilizing the underlying storage's API
- Better benchmark utility and comparison of different arithmetic tricks to speedup MinHash signature computation and improved compression.
- Better benchmark utility to measure performance of various storage backends, and propose optimization.
- GPU-based algorithms.
How to become a collaborator: github.com/ekzhu/datasketch/…
4
5
1,625

30 Sep 2025
Agradecemos la participación de expertos de SocialTic, DataMorfosis, DataSketch, y Red Ciudadana, en la impartición de la capacitación para socieda civil del Ministerio de la Presidencia con la OEA y el Open Data Charter con colaboración de ILDA
9
5
9
2,253

24 Sep 2025
🇨🇷 Invitando a todas las organizaciones de sociedad civil de #CostaRica a esta capacitación gratuita de datos el 30 de septiembre con expertos internacionales de @socialtic @DatamorfosisMx @Datasketch y @RedxGuate
24 Sep 2025

Invitamos a las Organizaciones de Sociedad Civil de Costa Rica 🇨🇷 a participar de la capacitación virtual gratuita de #DatosAbiertos a realizarse el próximo martes 30 de Septiembre para aprender cómo usar y aprovechar datos abiertos en tu organización
Registrate. Dale clic 👇

ALT https://www.oas.org/ext/es/principal/calendario/evento/id/1103
4
3
276

29 Aug 2025
🚨 Pipol, se viene el gran lanzamiento de la Pipol Bot 🤖🔥
El 4 de septiembre de 6 a 8 PM nos vemos en @Datasketch (Calle 71 # 10-47, Bogotá – Colombia) pa’ contarles todos los detalles detrás de su creación, probarlo en vivo y parcharnos con cafecito, aromática o sodas.
La entrada es gratis, los cupos son limitados y el parche va a estar buenísimo.
Link de registro 🫶🏼✨
luma.com/rjjp1fbm
1
10
1,189
27 Aug 2025
Gracias a nuestros aliados y partners tecnológicos @Datasketch @jpmarindiaz 🧡
Y gracias a @GoogleNewsInit @PolisLSE #InnovationChallenge de Journalism Ai
En nuestra página web pueden ver a La pipol Bot en la parte inferior derecha 💖🫶
economiaparalapipol.com/
3
10
971
27 Aug 2025
Entendimos que la única manera de alcanzar nuestras metas era con constancia, y así ha sido todo 🫶🏻.
Cada día vemos reflejado un pedacito de nuestra esencia en cada cosa que hacemos 💕. Darle vida a cada proyecto nos llena de orgullo y por eso hoy queremos presentarles a La Pipol Bot, un chat que les ayudará a entender temas económicos en lenguaje sencillo, y lo más importante, con la confianza de que cada respuesta está curada por nuestro equipo.
Durante más de un año hemos estado trabajando junto a Datasketch (gente tesa en datos) para cumplir con nuestro propósito: llevar la economía a toda la pipol desde diferentes herramientas.
Comenten la palabra "Chatbot" y les enviamos el link para que lo prueben 💫.
47
26
182
11,861

22 Aug 2025
El medio Economía para la Pipol se unió con la firma tech Datasketch para crear un bot con IA, basado en datos verificados, que hace más fáciles de entender las noticias económicas.
latamjournalismreview.org/es…

2
124

¿Puede la #Innovación #GovTech mejorar el acceso a información en las ciudades?
En @ciudaddemendoza 🇦🇷, un piloto con la #Startup @datasketch redujo barreras para acceder a normativas y oportunidades comerciales, clave para su visión de “Ciudad de 15 minutos”.
🎧 Escucha el nuevo episodio de #FuturoPúblico: youtube.com/watch?v=PtKFoUgS…

1
2
4
334

27 Jun 2025
En el próximo videopodcast de Datasketch, Juan Pablo Marín (CEO de Datasketch) y Claudia Báez (cofundadora de Cuestión Pública) dialogan sobre los retos, oportunidades y transformaciones que trae la IA al periodismo de datos.
🔗 Regístrate aquí → lu.ma/wsajy85q

1
5
164
26 Jun 2025
Queremos invitarles a probar una nueva herramienta que estamos creando junto a Datasketch y Google. 🚀💬 (asistencia gratuita)
Comenten esta publicación si quieren recibir más información y ser parte de la prueba. ¡Les leemos! 👀✨
60
4
106
13,529

From Nigeria 🇳🇬, @TheICIR shares their progress and lessons learned in developing an AI-powered tool designed to transcribe and translate news content into Igbo, Hausa and Yoruba.
🗨️Read their article by Eunice Enoch: journalismai.info/blog/7w7qb…

1
4
6
394

7 May 2025
En #DataALaLata exploramos el efecto anaglifo 3D para hacer visibles las desigualdades territoriales que a menudo pasan desapercibidas.
Aprende metodologías de diseño, explora ejemplos de @Datasketch y crea visualizaciones que revelan.
Inscríbete acá 👉 bit.ly/44kd23m

1
3
47
27 Mar 2025
Contento y orgulloso con esta, la primera generación de #LideresDeDatos de un proceso regional emprendido desde @OEA_oficial con @DatamorfosisMx - Gracias
@ildalatam
@sikkut
@GobDigitalCL
@DNP_Colombia
@derechosdigital
@opendatacharter
@Datasketch
@GlobalIndexRAI
@hotosm
27 Mar 2025

👏🏼 👏🏼 👏🏼 Felicitamos a la primera generación de 4️⃣6️⃣ #LíderesDeDatos comprometida con una gobernanza de datos efectiva, participativa y centrada en las personas.
💡Los datos son un insumo fundamental para el diseño de políticas públicas ➕ eficientes y eficaces.
#EscuelaOEA

6
22
1,433

13 Mar 2025
🔹.@jpmarindiaz CEO & Cofundador de @Datasketch nos explica cómo construir historias a través de datos y la importancia de la comunicación para el engagement:

2
9
274


17 Jan 2025
¡Mil gracias por compartir, amigaaaaas! ¡Les echamos un 👁️ para compartirlo y socializarlo con toda la comu datera #LATAM! 🤓🫰📊❤️🔥
174

10 Jan 2025
I finished the data scrape of all Local US News sources.
I built the source, with all newspapers, and then I scraped each site, 10 pages deep on news articles.
Now, I have a dataset of newspaper articles,
about 1 million rows.
The problem is that the news scraper failed on some sources, and these will need to be excluded from production_news.
I am looking at different options for efficient deduplication, and so far I am liking
"datasketch" , which is described as "datasketch gives you probabilistic data structures that can process and search very large amount of data super fast, with little loss of accuracy."
we shall see!
1
4
130