
📈 Top Libraries & Learning Resources for Time Series Analysis
If you're serious about forecasting, anomaly detection, demand prediction, quantitative finance, or sensor analytics, these are the tools and resources worth learning.
Python Libraries
1. Pandas
The foundation of almost every time series workflow.
Use it for:
• Time indexing
• Resampling
• Rolling windows
• Missing value handling
• Feature engineering
Every time series project starts here.
---
2. NumPy
Provides efficient numerical operations for large-scale time series data.
Useful for:
• Mathematical transformations
• Signal processing
• Statistical computations
---
3. Statsmodels
The classic library for statistical time series analysis.
Includes:
• ARIMA
• SARIMA
• Holt-Winters
• Statistical tests
• Decomposition
A must-learn for understanding forecasting fundamentals.
---
4. Prophet
Designed for business forecasting.
Handles:
• Seasonality
• Holidays
• Trend shifts
• Missing data
Great for sales, traffic, and operational forecasting.
---
5. Darts
One of the most comprehensive modern forecasting libraries.
Supports:
• ARIMA
• Prophet
• XGBoost
• LSTMs
• Transformers
Excellent for experimentation.
---
6. sktime
Scikit-learn for time series.
Provides:
• Forecasting
• Classification
• Regression
• Anomaly detection
Ideal for building production pipelines.
---
7. NeuralForecast
State-of-the-art deep learning forecasting library.
Includes:
• N-BEATS
• NHITS
• TFT
• DeepAR
Widely used for large-scale forecasting systems.
---
8. GluonTS
Amazon's open-source forecasting toolkit.
Built for:
• Probabilistic forecasting
• Large datasets
• Deep learning models
Popular in enterprise environments.
---
9. Kats
Meta's time series toolkit.
Features:
• Forecasting
• Change point detection
• Anomaly detection
• Diagnostics
Useful for monitoring systems and business metrics.
---
10. tsfresh
Automatically extracts hundreds of features from time series data.
Perfect for:
• Predictive maintenance
• Sensor analytics
• Feature engineering
---
11. PyTorch Forecasting
Build advanced forecasting models using:
• LSTM
• GRU
• Temporal Fusion Transformer
Ideal for deep learning practitioners.
---
12. River
Designed for streaming and real-time machine learning.
Useful for:
• Online learning
• Streaming forecasts
• Continuous updates
Important for IoT and event-driven systems.
---
📚 Best Learning Resources
Beginner
• Time Series Analysis with Python Cookbook
• Hands-On Time Series Analysis with Python
• Pandas Documentation
---
Intermediate
• Forecasting: Principles and Practice
• Hyndman & Athanasopoulos
• Time Series Analysis and Its Applications
These are considered industry classics.
---
Advanced
• Deep Learning for Time Series Forecasting
• Probabilistic Forecasting
• Temporal Fusion Transformers Paper
• N-BEATS Paper
• NHITS Paper
Research papers become increasingly important as model complexity grows.
---
🎯 Learning Roadmap
Pandas
↓
Visualization
↓
Time Series Decomposition
↓
ARIMA / SARIMA
↓
Prophet
↓
Feature Engineering
↓
Machine Learning Forecasting
↓
Deep Learning Forecasting
↓
Anomaly Detection
↓
Probabilistic Forecasting
Most people learn machine learning first.
The strongest analysts learn how time changes data.
1
12
430

Jun 13
sou novo nessa coisa de futebol, que horas eles começam a deepar a wave antes de avançar pro drake e pegar high tempo no mapa?
11
🚀 Designing & Training Deep Learning Models for Large-Scale Time-Series Cross-Sectional Prediction
In finance, retail, healthcare & IoT, we deal with massive datasets combining time-series (temporal dynamics) and cross-sectional features (static attributes). Classic models break at scale.
Here's how to build production-grade DL systems.
Architecture Choices:
- Use
Temporal Fusion Transformers (TFT) or Informer for long sequences variable selection.
- Hybrid: LSTM/GRU Attention TabNet-style cross-sectional encoders.
- For ultra-scale: N-BEATS, DeepAR, or modern TimeGPT -style foundation models.
Key Training Challenges & Solutions:
- Scale: Use distributed training (Horovod, DeepSpeed, FSDP). Mixed precision gradient checkpointing.
- Temporal dependencies: Sliding windows, dilated convolutions, or reversible architectures.
- Missing data & irregularity: Impute via SAITS or model directly with masking.
- Concept drift: Online learning continual fine-tuning.
Data Pipeline Tips:
- Feature stores (Feast) for real-time serving.
- Chunked loading with Dask/Ray for TB-scale data.
- Normalization per entity/group robust scaling (QuantileTransformer).
Evaluation & Production:
- Time-based CV, walk-forward validation.
- Metrics: MASE, CRPS, Quantile loss for uncertainty.
- Deploy with ONNX/TensorRT monitoring (drift detection via Alibi).
Building these systems powers accurate forecasting at billions of rows.
What domain are you applying this to? Drop your challenges below 👇
2
72


Jun 9
ये ट्रक ड्राइवर के लिए ही चली थी एक स्कीम use deepar at night ऐसे नहीं चला था
1
1
152

June 2, 2026 Daily Court Digest highlights crucial NGT rulings on environmental issues: stone blasting near ACTREC in Navi Mumbai, alleged violations in Deepar Beel Wildlife Sanctuary linked to railway track doubling, and a Gujarat Pollution Control Board–approved carcass incinerator in Anand.
downtoearth.org.in/environme…

1
8
632

May 28
Remaining Useful Life Prediction of Rolling Bearings Using GRU-DeepAR with Adaptive Failure Threshold
mdpi.com/1424-8220/23/3/1144
#rolling_bearing #life_prediction
1
3
84

May 25
Our freindship is Higher than Chichu Ki Maliyaan and deepar than Hasilpur & Malsi
 Ammar Solangi
Ammar Solangi
8
37
333
6,852

冷知识:2027年,也就是明年,就是时序模型发明 100 周年了。
1927年,英国统计学家 乔治·尤尔(George Udny Yule) 在1927年发表了一篇里程碑式的论文,研究太阳黑子数据的周期性。—— 时序模型的现代鼻祖
这些模型运行比大模型更高效,甚至可以在 CPU 上跑得非常快速💨 不过他们不太通用,我们要为特定应用选择不同的模型。
当今(2026年),我们常用的时序模型有:
一、量化交易与金融
波动率预测:GARCH(1,1)、EGARCH、GJR-GARCH、HAR-RV、随机波动率模型(SV)。
统计套利:Engle-Granger 协整检验、Johansen 协整检验、VECM、Ornstein-Uhlenbeck 过程、卡尔曼滤波。
趋势与价格预测:ARIMA、LSTM、GRU、Informer、PatchTST、XGBoost、LightGBM。
高频交易:卡尔曼滤波、Hawkes 过程、ACD 模型。
市场状态识别:HMM(隐马尔可夫模型)、Markov Switching GARCH。
二、能源与电力
ARIMA、SARIMA、Prophet、LSTM、GRU、N-BEATS、N-HiTS、TFT、Chronos-2、TimesFM、状态空间模型。
三、供应链与零售
ETS(指数平滑)、ARIMA、Prophet、DeepAR、LightGBM、N-HiTS、TSMixer、TimeMixer、Chronos-2。
四、医疗健康
ARIMA、Prophet、LSTM、Transformer、卡尔曼滤波、TimesNet、HMM、Chronos。
五、工业制造与预测性维护
LSTM、GRU、TCN、TimesNet、Anomaly Transformer、Autoencoder(AE/VAE)、状态空间模型、XGBoost。
六、气象与气候
ARIMA、SARIMA、LSTM、GraphCast、Pangu-Weather、FourCastNet、ClimaX。
七、网络安全与IT运维
TimesNet、Anomaly Transformer、LSTM-Autoencoder、Isolation Forest、Prophet、DeepAR。
八、语音与音频
WaveNet、Whisper、Conformer、LSTM、GRU。
九、交通运输
STGCN、DCRNN、LSTM、Prophet、ARIMA。
十、农业
SARIMA、LSTM、Prophet、Random Forest、XGBoost。
4
1
4
427

🔥☀️⛅ Advanced #DeepLearning Approaches for #Forecasting High-Resolution #Fire #Weather Index (FWI) over CONUS: Integration of GNN-LSTM, GNN-TCNN, and GNN-DeepAR
✍️ Shihab Ahmad Shahriar et al.
🔗 brnw.ch/21x2j0P
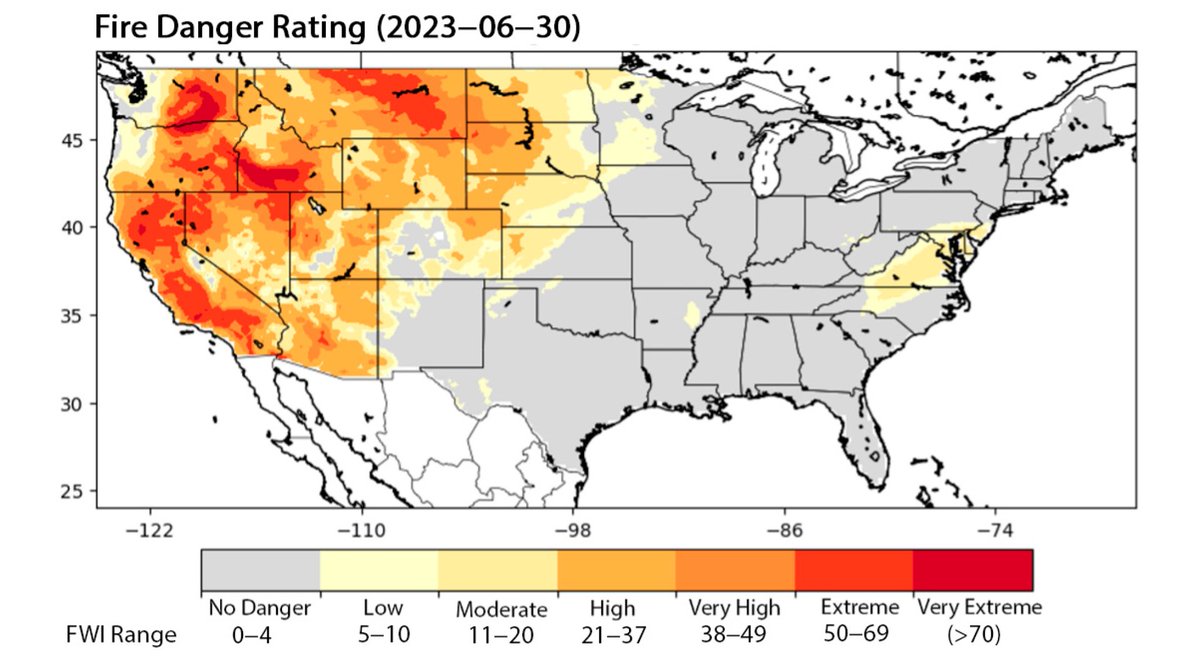
3
200

Par Deepar chahar ko match mein kya ho jaata hai, i mean he struggles so badly. Condition based bowler ban k rah gya hai
6
1,541

 IANS
IANS

#InPics | Trees cut down around Deepar Beel amid railway doubling work connecting Kamakhya Railway Station and New Bongaigaon Railway Station via Rani Reserve Forest.
#trees #TheAssamTribune




1
2
208

Apr 25
Just dig little deepar. ... and keep digging
Where there is no one there is Shiva and he is everywhere…!
16
72
147
2,778

Apr 15
FLAIR v0.6.0 Release!
FLAIR v0.6.0: Zero-hyperparameter forecasting that beats deep learning and foundation models.
We outperformed all of them (Fig. 1):
PatchTST (Princeton), Chronos-Large (Amazon), Moirai-Large (Salesforce), iTransformer (Tsinghua), TFT (Google), N-BEATS (ServiceNow / Yoshua Bengio), DLinear (HKUST), DeepAR (Amazon), TimesFM (Google).
These are large models with millions to hundreds of millions of parameters. FLAIR wins with 5.
There are models that score higher on individual benchmarks, but FLAIR remains #1 in accuracy-vs-compute and #1 in MASE on the Chronos Benchmark.
Here is a brief explanation of how FLAIR works (Fig. 2):
(a) Raw waveform data is noisy and high-dimensional.
(b) Reshape the series by its natural period into a matrix, and a rank-1 structure emerges.
(c) The Shape (periodic pattern) was traditionally a learning target. We proved, both theoretically and experimentally, that learning a repeating structure yields little accuracy improvement; it either slows the model down or makes accuracy worse.
(d) What remains is the Level: a rough summary of total magnitude per period. Strip away the Shape, and a smooth, slowly-varying signal appears. Predicting it requires no rich model. Moreover, the Level has only 1/P the dimensionality of the original series (P = period length), which improves both performance and noise robustness.
(e) The result: a model with just 5 parameters produces forecasts that surpass time series foundation models and deep learning.
There is one more advantage. With deep learning models, interpreting why a forecast looks the way it does has always been difficult. The signal is buried in layers of nonlinear transformations, and it is unclear what periodic structure, trend, or variance the model has learned. FLAIR's structure makes interpretation self-evident: users can explain every forecast.
pip install flaircast
github.com/TakatoHonda/FLAIR
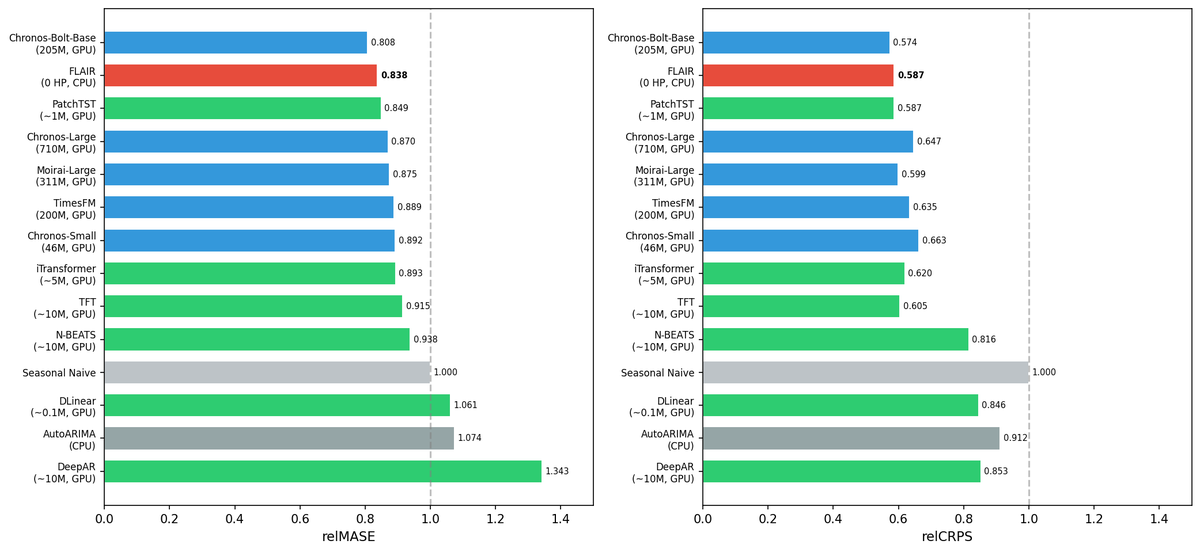
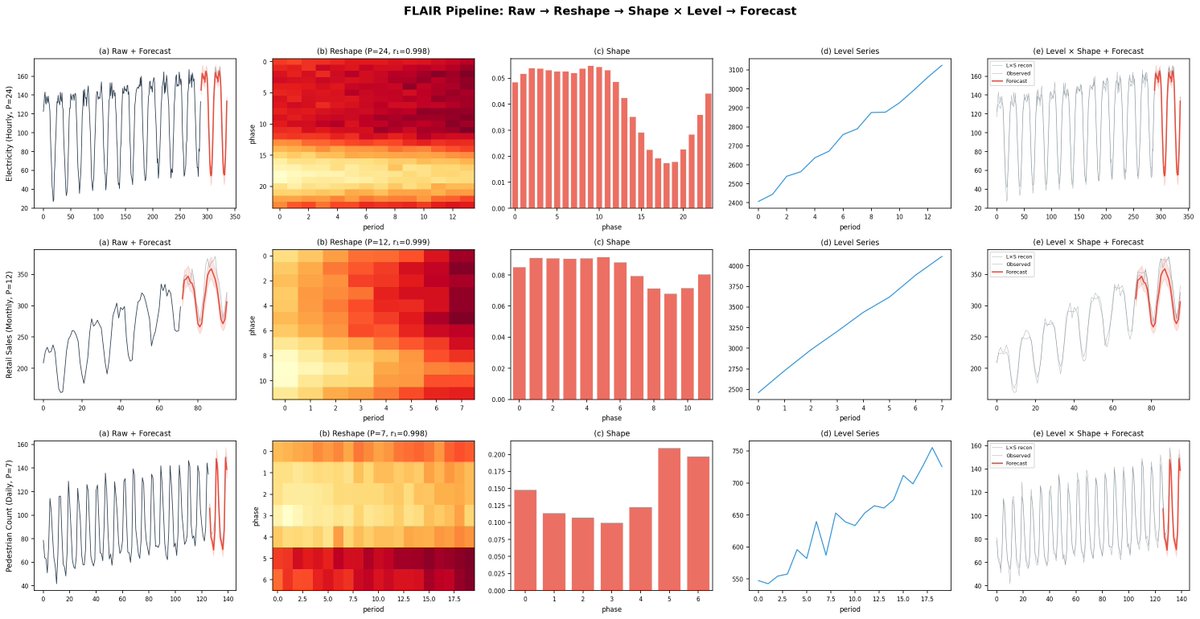
5
13
4,411

Apr 12
有一篇2024年的论文作为基座arxiv.org/pdf/2310.10688
我用gemini中文总结了一下:
这份由 Google Research 发表的论文介绍了一个名为 TimesFM (Time-series Foundation Model) 的时间序列预测基础模型。
它旨在改变过去针对每个数据集单独训练模型的传统模式,实现“开箱即用”的高精度预测。
以下是该论文的核心总结:
1. 核心目标
研究团队希望利用类似于自然语言处理(NLP)中大模型(LLM)的思路,构建一个预训练的基础模型。
该模型在面对从未见过的时间序列数据时,无需进一步训练(即 Zero-shot,零样本学习),其预测精度就能接近甚至超过专门针对该数据训练的有监督模型 。
2. 模型架构:TimesFM
TimesFM 采用了**仅解码器(Decoder-only)**的 Transformer 架构,并针对时间序列特性做了特殊设计 :
分块处理 (Patching): 将时间序列切分成类似“单词”的补丁(Patch)。
输入补丁长度通常为 32 。
非对称补丁长度: 这是该模型的一大创新。
其输出补丁长度(如 128)大于输入补丁长度(如 32)。这样做不仅提高了长程预测的精度,还减少了自回归生成时的步骤,提升了推理速度 。
掩码策略 (Masking): 在预训练中使用随机掩码,使模型能够处理从 1 到最大长度(如 512)的任何上下文长度 。
模型规模: 相比于动辄千亿参数的语言模型,TimesFM 相对轻量,最大版本为 2 亿(200M)参数 。
3. 海量预训练数据
为了让模型具备通用性,研究者构建了一个包含 1000 亿个时间点 的庞大语料库 :
真实数据: 主要来自 Google Trends(搜索趋势)和维基百科页面浏览量 。
合成数据: 使用 ARMA 过程、正弦/余弦波形、线性/指数趋势等物理模型生成,以弥补真实数据中某些频率(如每季度、每年)样本的不足 。
其他公开数据集: 如 M4 竞赛数据等 。
4. 实验结果
在 Darts、Monash 和 ETT 等多个公开基准测试中,TimesFM 的表现令人印象深刻:
零样本战胜有监督: 在许多任务中,TimesFM 的零样本预测效果优于专门训练的 DeepAR 或 Informer 等模型 。
碾压 LLM 适配方案: 相比于通过 Prompt 诱导 GPT-3 或 LLaMA-2 进行预测(如 llmtime),TimesFM 精度更高,且计算成本仅为前者的极小部分 。
微调潜力: 如果只用 10% 的数据进行微调,TimesFM 的表现能进一步大幅提升,显著优于同样微调过的 GPT-2 。
5. 结论与意义
TimesFM 证明了时间序列领域同样存在缩放定律(Scaling Laws):随着模型参数和数据量的增加,预测误差会持续下降 。
研究团队计划开源模型权重,以促进社区在各种下游预测任务中的应用 。
这为零售预测、能源管理、交通预测等领域提供了一个高效、低成本的通用解决方案。
4
1,153

Mar 16
o negócio é strongar a side pra dar slowpush e crashar a wave stackada daí você walka pra jungle e dá o proximity pra skirmish do buff pra deepar a vision e ter tempo na frente pra garantir a soul point e quebra o freeze da enemy wave
3
8
181

Mar 9
#GodMorningMonday
Before taking initiation
from Sant Rampal Ji Maharaj,
we and children were getting deepar and deepar into the quagmire of between culture,
even if we followed other Gurus.
Visit Sant Rampal Ji Maharaj YouTube Channel
#MondayMotivation

7
7
51

Big Tech Is Not Your Friend (and DeepAR Was the Proof)
If you’re a data scientist worth your salt, you should never forget one basic fact:
Read more: valeman.substack.com/p/big-t…
6
1,452
If you’re a data scientist worth your salt, never forget this:
Big Tech is not here to serve you with open source. Their purpose is to make money off you.
A prime example is the hype wave Amazon pushed 5–6 years ago, when “deep things” were marketed everywhere.
The reality?
DeepAR turned out to be a nothing-burger—routinely outperformed by ARIMA and simple statistical ensembles at a tiny fraction of the cost. (Remember the Nixtla study: roughly $1K to run DeepAR versus a few cents for a stats ensemble.)
But the issues goe deeper.
DeepAR was presented as “probabilistic forecasting.”
In reality, its prediction intervals were often several times wider than they needed to be, rendering them unusable in practice.
Wide intervals aren’t “better uncertainty”—they’re bad calibration disguised as sophistication.
And yes, it’s the forecasting team from the same company that tried to put down conformal prediction, while pushing “deep things” that conveniently encourage users to burn GPU hours—and boost their bottom line.
So here’s the question:
Do you want to be a lemming driven by hype, or do you want to do things based on math and science?
If it’s the latter, my book is for you: valeman.gumroad.com/l/probab…
#timeseries #forecasting

1
18
1,596