
What’s the best alternative to Premiere (besides the Avid) , Media Encoder and PhotoShop/Illustrator—genuine question I would like to unsubscribe
1
1,117




built an API gateway in Go that routes RAG queries across three retrieval tiers based on query complexity. simple queries hit BM25, complex ones go through cross-encoder reranking, multi-hop gets iterative retrieval.
the routing accuracy came out at 85% for complex queries across 180 test questions.
#golang #RAG #buildinpublic
1
3

The setup pairs a digital encoder with a passive diffractive decoder that routes image content to different depths during propagation. In tests, measured patterns also beat a free-space baseline without the decoder.
5
1,325

How LinkedIn scaled LLM semantic search to hundreds of thousands of QPS without missing latency SLAs.
Running LLM cross-encoders for real-time search ranking is usually a non-starter for massive scale. Cross-encoders provide superior query-document interaction, but their inference costs scale horribly with high request volumes. I recently reviewed LinkedIn's new paper detailing how they broke this bottleneck to replace their keyword and DLRM-based stack, and the engineering behind it is extremely clever.
Here are the highest-impact takeaways from their new two-stage architecture:
They bypassed Approximate Nearest Neighbor indices entirely. For the retrieval stage, LinkedIn built a GPU-accelerated exhaustive retriever that directly scans billion-scale indices using an LLM-based bi-encoder.
They achieved a 75x throughput increase for the ranking stage. Instead of deploying a massive frontier model, they used a highly optimized 0.6B parameter Small Language Model ranker. They hit their strict latency budgets at hundreds of thousands of queries per second by utilizing offline context summarization and model pruning.
They stopped treating model training and infrastructure as separate problems. The massive latency reduction came from aggressively co-designing the two, specifically by utilizing multi-teacher distillation and deploying a custom prefill-only inference stack.
The paper gets into some fascinating nuances regarding the exact loss functions required to make this work. There is a very specific way they mix InfoNCE and pairwise margin loss with explicit engagement features, like network proximity, to ensure the exhaustive retriever remains highly accurate at a billion-scale.
Read the full deep dive in the newsletter, link below. ⬇️

1
2
90

Ein Yaskawa UAJPEE-08DK2KU aus einem Werkzeugwechsler kam mit Problemen an der Haltebremse zu uns.
Nach der Untersuchung zeigte sich, dass der Bremsbelag noch in gutem Zustand war. Ursache war eine defekte Magnetspule innerhalb der Bremse SNB 0.5ZG-01.
Zusätzlich wurden Lager, Dichtungen und Encoder erneuert, der Motor gereinigt, neu lackiert und auf unserem Prüfstand getestet.
Nach erfolgreicher Endprüfung konnte die Einheit wieder an den Kunden ausgeliefert werden.
Im Blog mehr: industrypart.com/de/post/yas…
#Yaskawa #Industriemotor #Werkzeugmaschine #Reparatur #Maschinenbau #Instandhaltung #industrypart



1

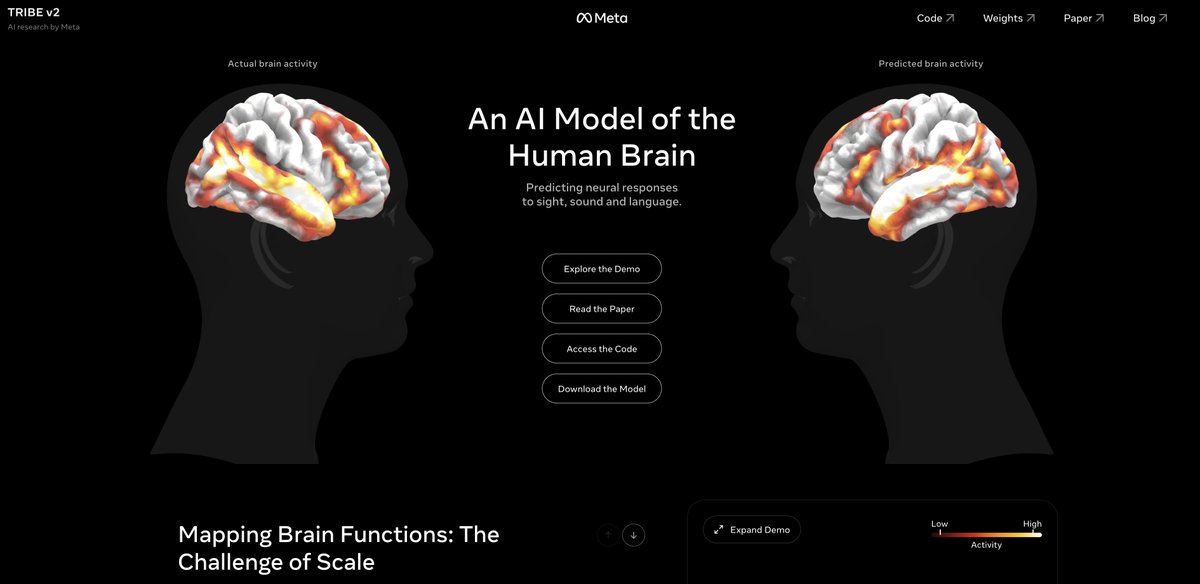
Meta’s TRIBE v2 is not a “unified model of human cognition.”
That’s not a dunk. It’s the floor. 🕳️
What it does pay is more interesting: a released multimodal fMRI encoder for predicting BOLD responses from video, audio, and language — with held-out generalization and recovery of known localizer effects.
Under #ÆrrGrammar𓆄:
Correct-Paper / Ambitious-Frame.
Strong paid object. Ambitious boundary. Prospective discovery still unpaid.
That boundary is the piece.
aidemos.atmeta.com/tribev2
12

Also for my use case I need French English
A good old BERT model may outperform all recent encoder architectures. Tokenization is often the issue as we see with ModernBERT
1
11
Walid Marei retweeted

On the left:
A 0-5v string potentiometer ($107)
On the right:
A hall effect rotary encoder that outputs 48,000 pulses to get to full open. ($53)
Switched to get my BOM cost down and have overhead in the budget to mount lights in a separate enclosure.


2
1
18
612

昨日配布したばかりですが、1個だけカスタムノード追加したので、v2.0 → v.2.1へアップデートしてます😇
v2.1 Update版は昨日の記事内にアップロードしてます🙇
✅追加点
・Text Encoderデバッグノード追加
Text Encoder (CLIP)のメタ情報など、詳細な内容を取得するためのデバッグノードです。

Jun 13

ComfyUIの全自動ワークフローを考えるなら、ほぼ必須なリソース管理や論理フロー、遅延処理分岐などを盛り込んだカスタムノードができました😊
是非記事だけでも見てみてください🫡
ComfyUIカスタムノード限定配布「ComfyUI_KPCustomScripts_v2.0」
note.com/konapieces/n/n96f6c…
5
210
It's a string rotary encoder. It has an open gate npn output. ~48k pulses over 1200mm of distance. Uses a hall effect sensor on a magnet. It runs on 5 volts, and the output can be direct to my microcontroller, no voltage dividing necessary.
5

The Franconic- GalloLatin got triggered!!
And Get out my country too!!
Allez vous faire encoder!!
Salope!!

2

i’m gonna give you my key ones that aren’t k-pop 🙂↕️bruises by fox stevens, the summoning & euclid by sleep token, ain’t it fun & rose coloured boy by paramore, encoder by pendulum, disconnected & valentine by 5sos, mama by mcr, doom riff & kill the power by skindred
1
1
116

4h
In this case I just did it to keep the text scaling at a pleasant level. It wasn’t a technical measure.
Though the background was. I filled as much space as possible with same-color pixels to make really sure that the output wins against Twitter’s JPEG encoder.
2
1
11


4h
Testing the new Gemma 4 12B (QAT) vision and OCR capabilities locally with LM Studio.
# The setup:
- GPU: NVIDIA RTX 4060 (8GB VRAM)
- CPU: Intel i7
- Runner: LM Studio
- Config: 32k context, 38 layers offloaded, Flash Attention enabled
- Speed: ~14 tokens/sec decode throughput
# The test:
I gave it a screenshot of Google AI Studio.
Prompt: "clone this. give me a single html file"
# The result:
A solid one shot replication. It successfully mapped out the layout, recognized the UI text, and structured the divs correctly, with only minor differences from the original. Results available at the end of the video.
Quite capable for a 12B model running on budget consumer hardware. A gpu that costs only $300.
# Why the architecture under the hood is notable:
Unlike traditional models that rely on heavy, separate vision and audio encoders, Gemma 4 12B uses a unified, encoder free architecture.
It bypasses separate multi stage encoders.
Uses a 35M parameter vision embedder to project raw 48x48 pixel patches directly to the LLM hidden dimension.
Local multimodal development is becoming highly accessible on standard hardware.
If you've spun up Gemma 4 12B locally, what setup are you using and what kind of throughput are you seeing?
Jun 3

i just ran Google's brand new Unsloth Gemma4 12B dense GGUF on my RTX 4060 using llama.cpp CUDA 13.2
21 tokens per second. on a budget consumer GPU. locally.
no API. no cloud. no subscription.
and the benchmarks are absolutely cooked
# first let's talk architecture because this is genuinely different
every multimodal model you've used has a frozen vision encoder frozen audio encoder LLM backbone glued together
Gemma 4 12B is different
it's a single decoder only transformer. that's it. vision? raw 48×48 pixel patches → one matmul → projected directly into the LLM
audio? raw 16kHz signal sliced into 40ms frames → linear projection → same LLM input space
no encoder tax. no latency penalty. no fragmented memory
to put the encoder savings in perspective:
old Gemma 4 26B approach:
- 550M param vision encoder (frozen)
- 300M param audio encoder (frozen)
- LLM backbone
Gemma 4 12B:
- 35M param vision embedder (a single matmul)
- no audio encoder at all
- LLM backbone handles EVERYTHING 550M → 35M for vision alone. that's a 15x reduction
this is why the gemma-4-12b-it-Q4_K_M.gguf is just 6.6 GBs!!!
and it has 256K native context context
# Benchmarks:
AIME 2026 (math olympiad): 77.5%
GPQA Diamond (expert science): 78.8% LiveCodeBench v6 (real code): 72%
Codeforces ELO: 1659
MMLU Pro: 77.2%
MATH-Vision: 79.7%
BigBench Extra Hard: 53%
inference → llama.cpp, LM Studio, vLLM, SGLang
llamacpp flags:
-m "gemma-4-12b-it-Q4_K_M.gguf" -ngl 99 -c 8000 -v --port 8080
Available on huggingface now! Link below
8
10
97
9,930

6. Encoder-Decoder Architecture
Discover how machines translate languages and summarize texts.
Learn the building blocks of modern language processing.
Build your own text generator with simple code examples.
cloudskillsboost.google/cour…
1
8
713

🚀 Week 1 – Part 2 done!
Dived into Unsupervised Learning, covering Dimensionality Reduction, Encoder-Decoder Architectures, Reconstruction Error, Density Modeling, and NLL.
Building stronger ML foundations one concept at a time.
#MachineLearning #AI #DataScience

25