
[483102963] assimp:assimp_fuzzer_gltf: Heap-buffer-overflow in unsigned long glTF2::Accessor::ExtractData<aiVector3t<float>>
crbug.com/483102963
1
6
1,167

31 Jul 2025
I have built a small utility that generates TypeScript types and a typed client for HelixDB (@helixdb) schemas and queries. Response types still need a few workarounds to extract correctly using the extractData util we are exporting (because the /introspect endpoint returns the variable name of the returned value, and not the actual type), but request bodies are fully typed.
Give it a try 👉 github.com/harshdoesdev/heli…
1
5
255

8 Aug 2024
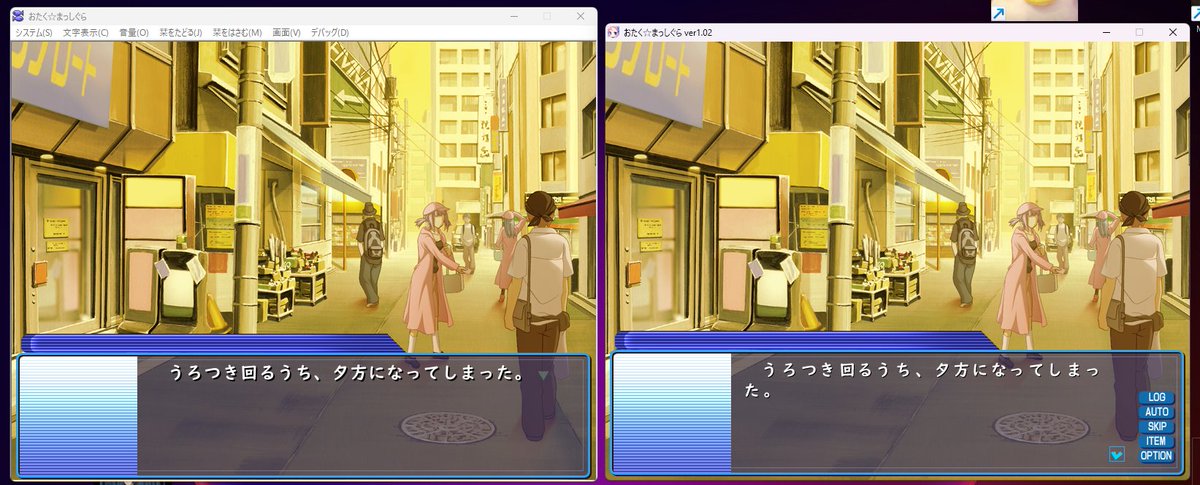
あといろいろ読む限りver1.02でほとんど読めるらしいですね...攻略が面倒くさいだけで。
ExtractDataを探すのが本当に大変だった。2時間近くかかった。というか良く見つかったなって思う。
4
402
8 Aug 2024
おたく☆まっしぐら 最果て化(おそらく)成功しました!めっちゃ大変だった。
一つだけ言い残せるなら検索したら出てくExtractDataと 最果てへ☆まっしぐら で必要なExtractDataは(たぶん)別物だということを言い残したい。(説明読んだらわかるでしょとか言わないでね。効くから。)#エロゲ

1
11
868

15 Apr 2024
🐒 Explore the vast jungle of web scraping with us! Easily retrieve text from any site. Contact us now by filling out our online form: buff.ly/3B2nEDI 📩 #WebScraping #ExtractData #WebJungle

1
42

3 Aug 2023
Who knows how to extract calendar data from a PDF? I have a client with such documents but didn't find yet any library that could properly read such tricky data.
Maybe some indiehacker already created such a library or an API? 🤔
#buildinpublic #parsepdf #extractdata
1
3
551

俺もExtractDataの技術を全て教えるプログラミングスクールやるか(やらない
“漫画村”創設者がプログラミングスクール開設へ 「漫画村の技術全て教える」 ネット上では賛否 - ITmedia NEWS itmedia.co.jp/news/articles/…
2
156


Every major industry today leverages #data in some way. The right data however, is usually found in unstructured formats, and in multiple disparate documents.
So how do you efficiently & effectively #extractdata?
A thread 🧵
1
4
3

4 Nov 2022
📌 Participants have to explore & extract publicly available Healthcare #Data around the Globe, with special emphasis on the #USA region & also come up with unique methods and tools to #extractdata from the web!
➡️Register now:🔗 bit.ly/Healthathon
#healthathon #hack2skill




22 Oct 2022
When it comes to #DataExtraction from Documents, far too often #accuracy is not what it sounds like. We need better #metrics for better decision-making. bit.ly/3SFK0BP
#data #ai #ml #uniqreate #uq #data #automatedataextraction #extractdata #SaaS #businessusers

3

10 Aug 2022
Chain your Bolts together to merge or extract data from one pipeline to another. 😃😃
Try Now- boltic.io/
#data #pipeline #extractdata #nocode #etl #DataAnalytics

1
3

30 May 2022
Nowadays people use #PDF on a large scale for reading, presenting, and many other purposes. But it is difficult to edit a PDF file and export data from it.
Fortunately, there are some solutions that help #extractdata from PDF into Excel.
hubs.la/Q01cnm9c0
2

28 Feb 2022
Octoparse is a great #webscraper that can be used to #extractdata from websites.
bit.ly/3K10BvF
Here is a Step By Step Guide on How to Use the Octoparse,
bit.ly/octoparse-tutorials

2

24 Jan 2022
TensorIoT's Artificial Intelligence develops innovative #AI technology solutions to extract, transfer, and transform your company's data: youtube.com/watch?v=17DAOt0o…
.
.
.
#tensoriot #artificialintelligence #ai #aipractice #technology #extractdata
1
2

14 Aug 2020
Geolocalized Open Data Extraction with thedatapond.net
For small businesses, entrepreneurs, freelancers, individuals...
#webscraping #data #extractdata #scraping #extract #prospecting #contactscraping
1

23 Jun 2020
minoriがExtractData(エロゲの暗号化解読ツール)の開発者を訴訟してたよなぁと思ったけど、あれは不正競争防止法に基づくもので、リバースエンジニアリング禁止とはまた別の話なのかな
22 Jun 2020

知財関係をずっとやってると、リバースエンジニアリング禁止条項ってお守りのように挿入されているのはよく見かけつつ、入っていて役に立ったという話は全く聞いたことがないので、正直、知財観点でも要らないのではと最近は思いつつあります。
1
2

24 Feb 2020
Most businesses today depend on affordable web data scraping services to fetch data that is important to their key decision making processes.
If you too have data extraction needs, contact us today - botscraper.com
#dataextraction #datascraping #webscraping #extractdata

1

2 Feb 2020
When running an ExtractData job (one of the ones we just dispatched), we run SELECT * from site_stats WHERE site_id = :site_id AND id > last_id_exported AND id <= export_to_id. And obviously we chunk it up.
1
4