
My favorite was probably hawkgirl saying flash cant getva date cuz hes too fastv🤣🤣🤣.
Flew right by me as a kid but when I got older I couldn't believe that made it in
1
29

May 26
Previously, in our work on token merging/pruning methods like VisionZip, FastV, LLaVA-PruMerge, ToMe, etc., we always tried to drop / merge the redundant tokens.
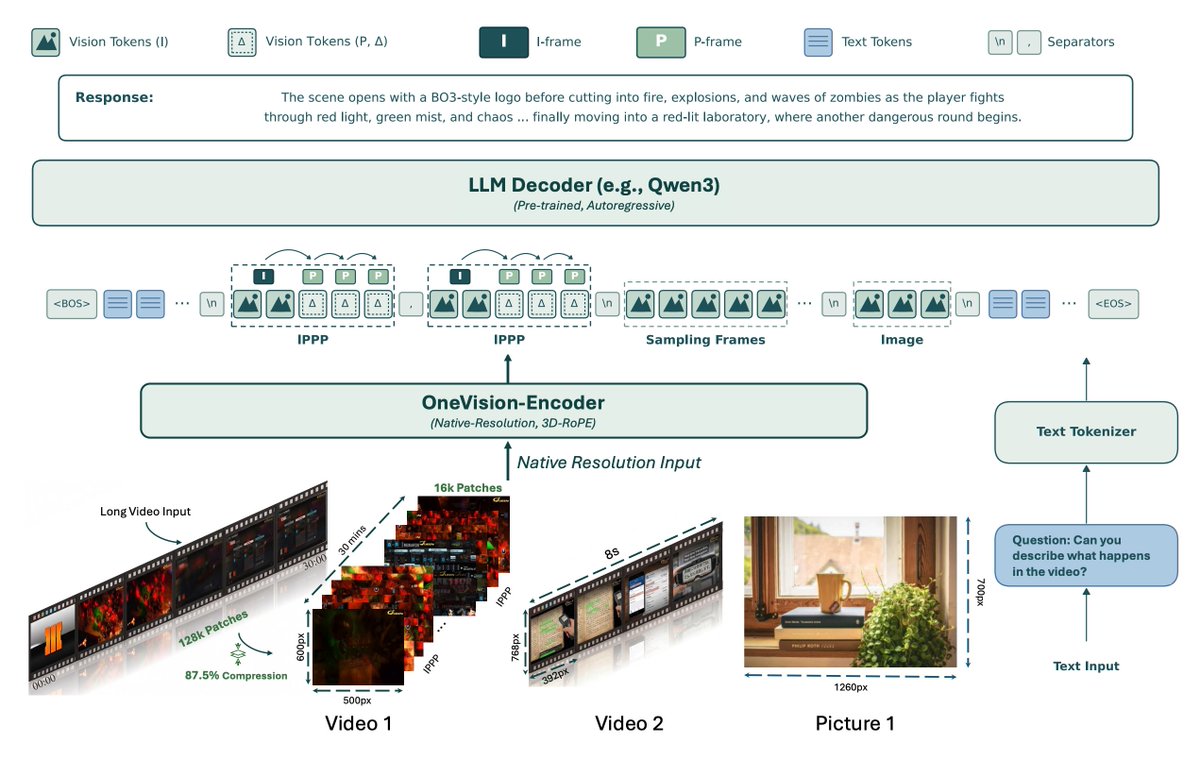
LLaVA-OneVision-2.0 takes a much more native route — directly leveraging video codec knowledge to treat highly dynamic video as a continuous bit-cost stream. Surprisingly, it handles redundant information better and delivers stronger results.
This feels like a cleaner, more fundamental way forward. Really nice shift! 🔥
May 26

🔥LLaVA-OneVision-2.0 Open Sourced🔥
LLaVA-OneVision series @lmmslab now upgrades to 2.0 with its key advance on *codec-stream tokenization*, which treats highly dynamic video as a continuous bit-cost stream
- Tech Report: arxiv.org/pdf/2605.25979
- Code: github.com/EvolvingLMMs-Lab/…
1
9
1,765

#fastv の「丸ごと九州ch」で、
『#ノーカットホテイソン』配信中です😆🩵
何もできずに大反省していた「鹿児島マラソンおもてなし広場の回」や、「業界最速8月に来年の抱負を語る回」配信中です。
懐かしむも良し、今から見て古参になるも良し。
ぜひご覧ください👀
fastv.jp/
May 4

GWの【丸ごと九州ch】は毎日新作あり!
5/5(火)は「バイク女子ひとり旅」「ノーカットホテイソン S2」「池尻和佳子のトコワカ」!!
📺【V FASTch】にて24時間配信中です! 【丸ごと九州ch】を選択してぜひご覧下さい→ fastv.jp
#丸ごと九州チャンネル #Vファストチャンネル #九州
3
8
1,287







17 Dec 2025
Many recent methods (e.g., VisionZip, FastV, HIRED, and our SparseVILA) rely on column-wise attention reductions to estimate token salience for KV compression, token pruning, and sparse inference.
Until now, the lack of an efficient primitive has made these ideas hard to productionize. Flash-ColReduce fills that gap. 👇
Github: github.com/z-lab/flash-colre…
Paper: arxiv.org/abs/2510.17777
4
311

oomf sufggestd i try to do all my school relly fastv so i can go back 2 bed. wishme luck ......
1
26







12 Sep 2025
It was imisi he was talking about ive known him to be a classist he jst wants to to sue her for his game but she clocked him fastv
5
1,826


23 Aug 2025
If you feel sick
And you’re starting the fast
Your expresso shots are not recommended
While you’re sick.
If you’re doing a water fast,
You can switch it to a cold pressed juice feast/fastv
Vegetables/fruits
70/30 %
At least 4 liters of juice
Then water if you want
2
1
722


