
Feeling and building multimodal intelligence.
Joined May 2024
- Tweets 33
- Following 41
- Followers 353
- Likes 54
5 Photos and videos






safely engram❤️

Agents are mind-blowing.
But they don't remember things consistently.
Or when they do — it's not safe.
We built Engram.
AES-256 encrypted.
Keys stay on your device.
Zero-knowledge sync.
No cloud. No middleman.
Use it.
Your agent memory is yours.
@lmmslab
github.com/EvolvingLMMs-Lab/…
youtu.be/I6xVuNRMkVc
1
2
1,524

Agents are mind-blowing.
But they don't remember things consistently.
Or when they do — it's not safe.
We built Engram.
AES-256 encrypted.
Keys stay on your device.
Zero-knowledge sync.
No cloud. No middleman.
Use it.
Your agent memory is yours.
@lmmslab
github.com/EvolvingLMMs-Lab/…
youtu.be/I6xVuNRMkVc
1
3
10
4,856

lmms-lab retweeted

Jan 2
🥳Year-End Reflection on the Growth of LMMs-Lab🥳
2025 has been a fruitful year for 🧠LMMs-Lab🧠 @lmmslab (lmms-lab.com/), a non-profit open-source research organization dedicated to feeling and building the future of multimodal intelligence with:
🌟 > 12,000 Total GitHub Stars
🍴 > 2,000 Forks
🧑💻 > 30 Core Repositories
3
27
224
9,819
lmms-lab retweeted
20 Sep 2025
🔥LLaVA-OneVision upgraded to V1.5🔥
We @lmmslab present 🌋LLaVA-OV-1.5🌋, a fully open framework for democratized multimodal training
* Superior Performance surpassing Qwen2.5-VL
* High-Quality Data at Scale
* Ultra-Efficient Training Framework
- Repo: github.com/EvolvingLMMs-Lab/…
6
37
156
17,856
lmms-lab retweeted

24 Jan 2025
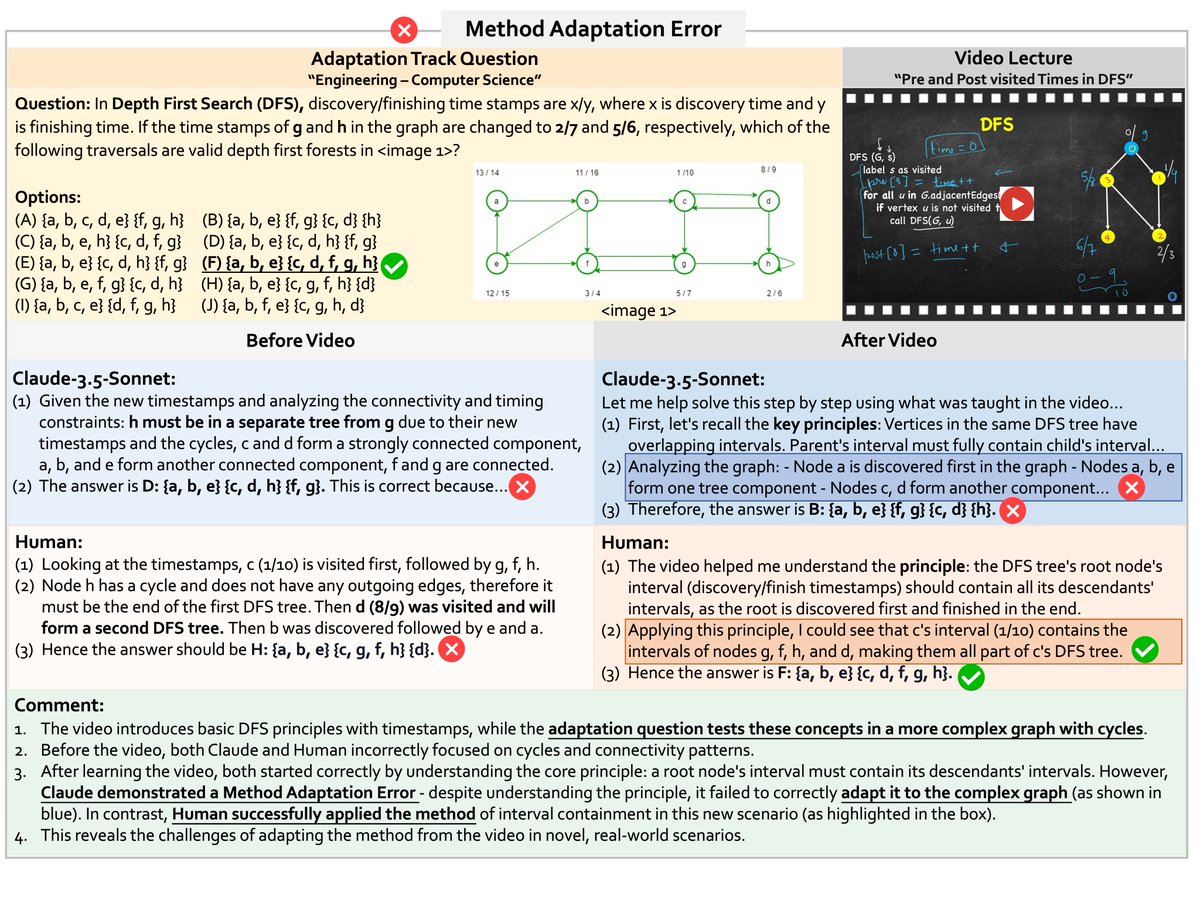
VideoMMMU is a meticulously crafted benchmark designed to evaluate multimodal models’ video understanding abilities for college-level videos.
Videos have tremendous knowledge and learning from them remains challenging for current models, but it is expected to become a crucial capability on the path toward achieving AGI.
24 Jan 2025

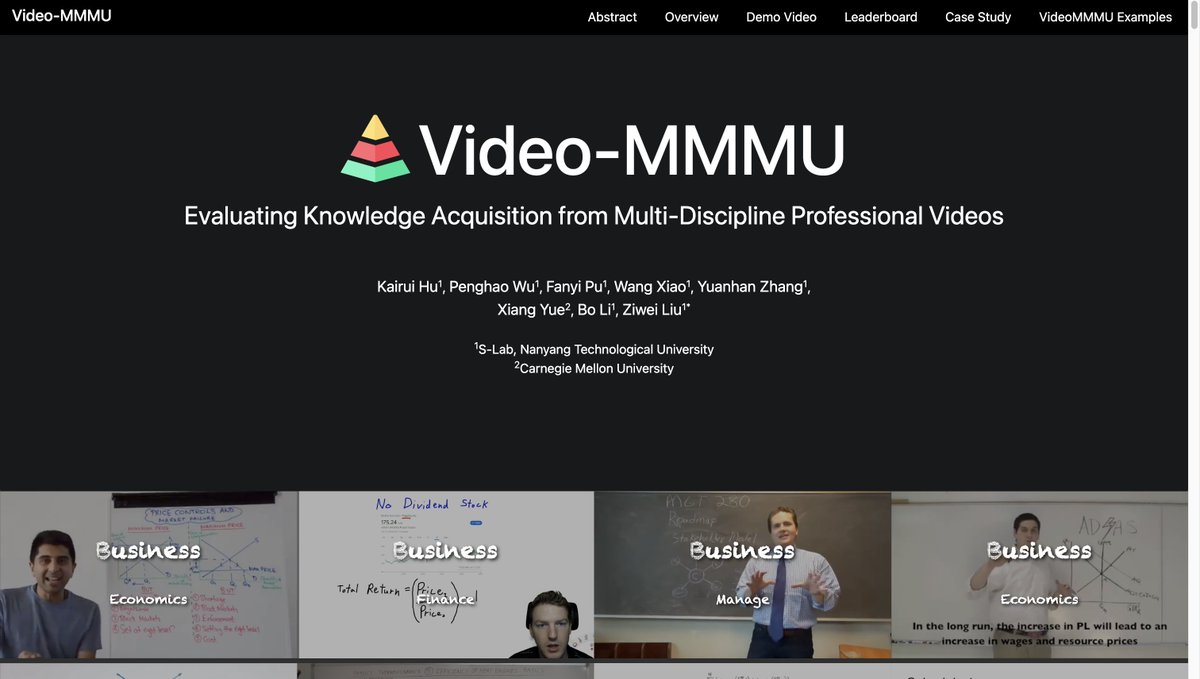
🚀Introducing Video-MMMU: Evaluating Knowledge Acquisition from Professional Videos
🎥 Knowledge-intensive Videos:
Spanning 6 professional disciplines (Art, Business, Science, Medicine, Humanities, Engineering) and 30 diverse subjects, Video-MMMU challenges models to learn and apply college-level knowledge from videos.
❓ Knowledge Acquisition-based QA Design:
QA pairs are aligned with the three stages of cognitive learning:
· Perception: Identifying knowledge.
· Comprehension: Understanding the underlying concepts.
· Adaptation: Applying the knowledge to practical scenarios.
📊 Quantitative Knowledge Acquisition Assessment (Δknowledge):
A novel metric that quantifies how much a model improves after watching a video, providing unique insights into its knowledge acquisition capability.
Why It Matters?
🚀 Pushing the Boundaries
Video-MMMU moves beyond perception and understanding of video to knowledge acquisition from video, positioning videos as a powerful medium for transmitting knowledge.
📚 Cognitive-Level Insights
Video-MMMU introduces three cognitive tracks—Perception, Comprehension, and Adaptation—that mirror human learning stages, providing a structured framework to evaluate how effectively models acquire, understand, and apply knowledge.
🧠 Bridging the Gap
Video-MMMU uncovers critical limitations in current LMMs and provides insights for advancing LMMs’ capabilities in knowledge acquisition from video.
Project Page:
videommmu.github.io/
ArXiv:
arxiv.org/html/2501.13826v1


2
5
28
2,952
lmms-lab retweeted
28 Nov 2024
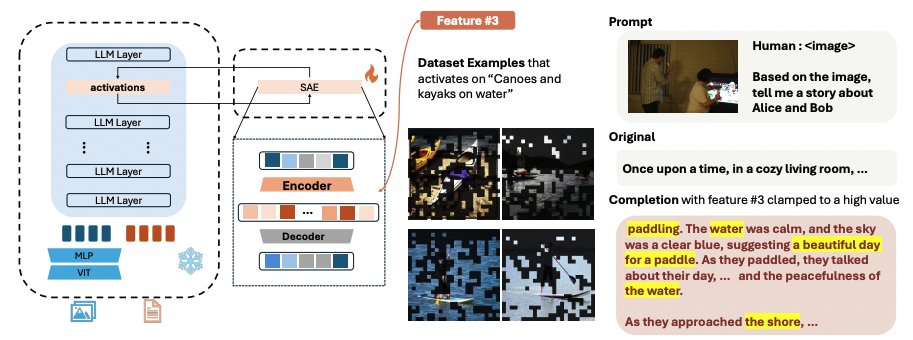
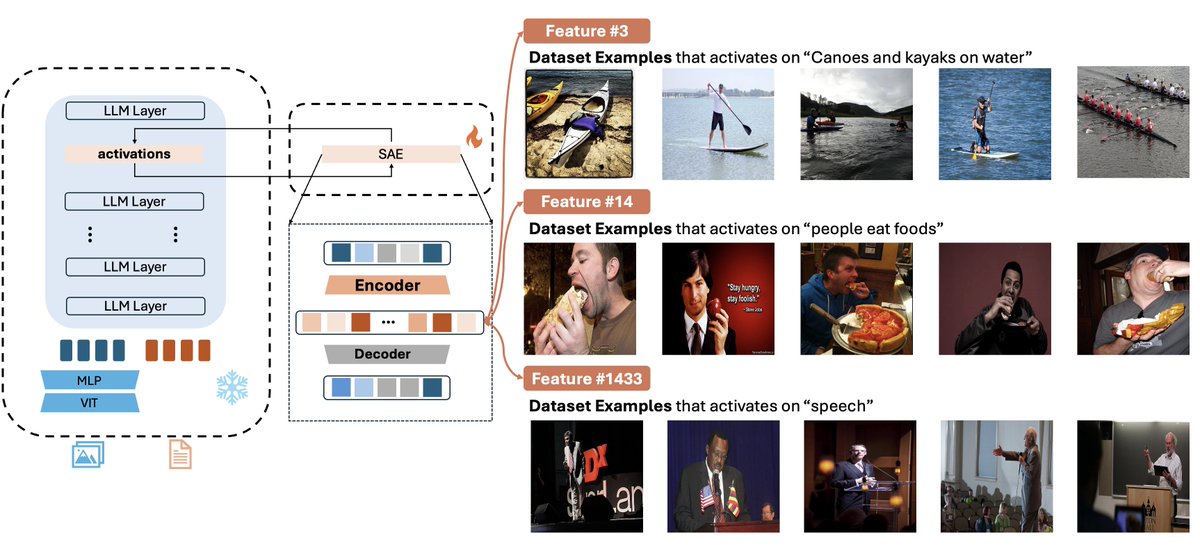
🤖Interpreting Large Multimodal Models (LMM)🤖
We present an automatic framework to identify, interpret and steer neurons within LMM for safe AGI
- Paper: arxiv.org/pdf/2411.14982
- Code: github.com/EvolvingLMMs-Lab/…
- Model @huggingface : huggingface.co/collections/l… . Thanks @_akhaliq !

New work from LMMs-Lab!
This time we present our latest research on the interpretation and safety of multimodal models
2
40
271
31,628
New work from LMMs-Lab!
This time we present our latest research on the interpretation and safety of multimodal models
27 Nov 2024

TL;DR
We present Large Multi-modal Models Can Interpret Features in Large Multi-modal Models
We successfully use a 72B large model to interpret the open-semantic features of an 8B small model, uncovering numerous important thought patterns inside multimodal models.
Paper: arxiv.org/abs/2411.14982
Code: github.com/EvolvingLMMs-Lab/…
Examples: huggingface.co/datasets/lmms…
5
20
34,355
lmms-lab retweeted

29 Oct 2024
🔥 We just submitted some baselines and benchmarks to lmms-eval @lmmslab (LLaVA team) — evaluation is now just one line of code away! We call for the reporting of visual token numbers when evaluating LMM performance!
- lmms-eval repo: github.com/EvolvingLMMs-Lab/…
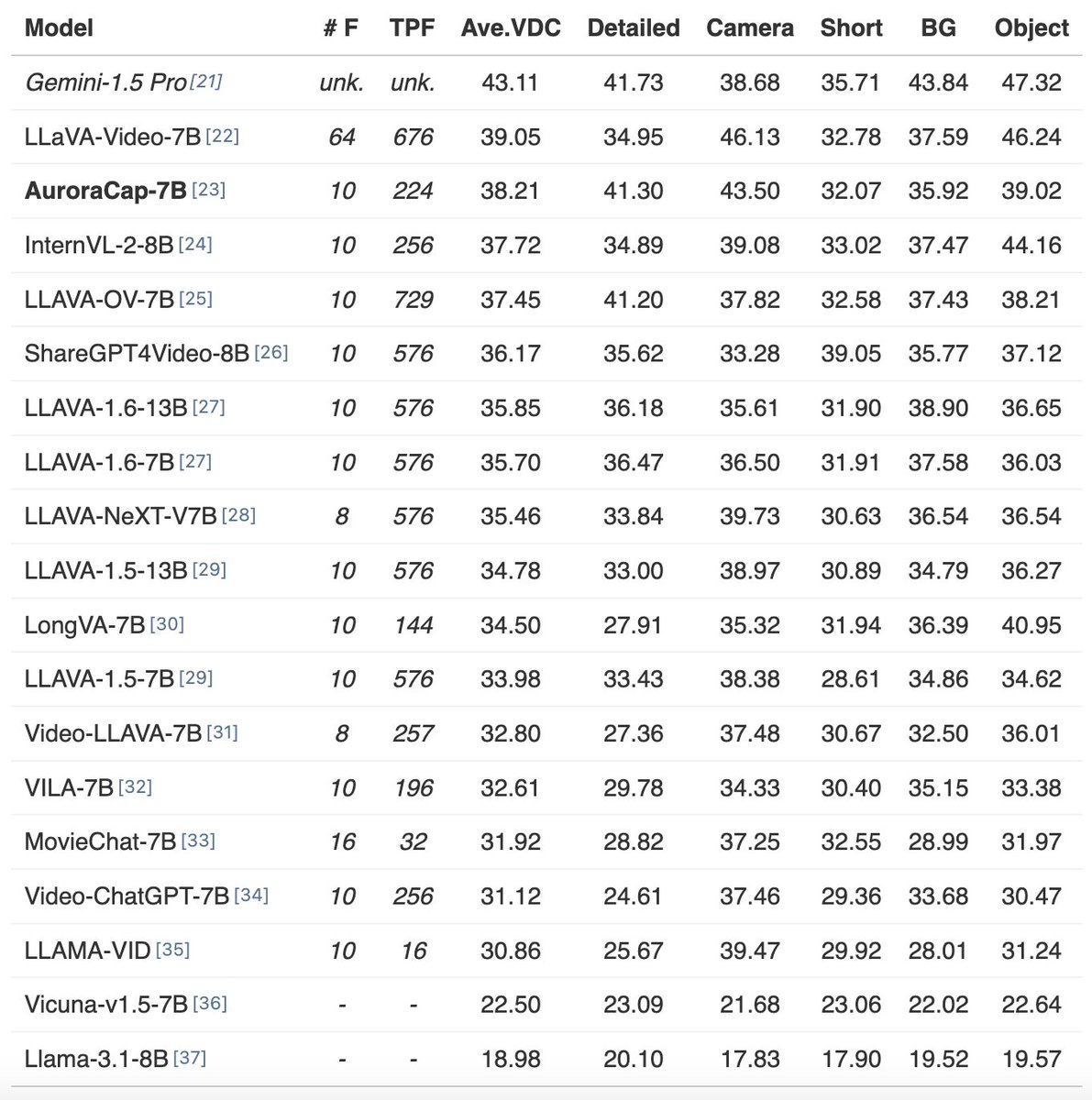
- VDC, first benchmark for detailed video captions: rese1f.github.io/aurora-web/…
- AuroraCap (VDC baseline): github.com/rese1f/aurora
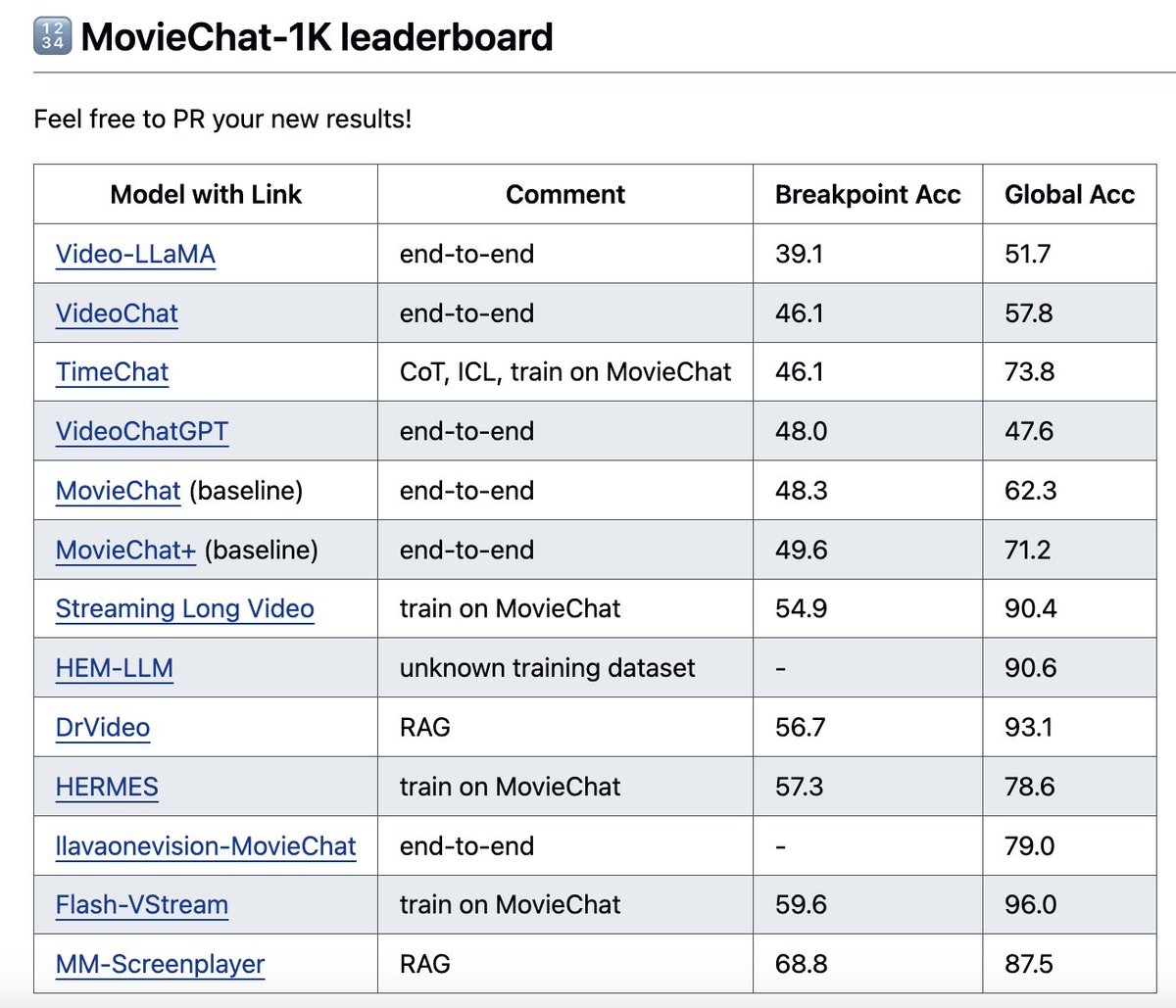
- MovieChat, first long-video understanding benchmark: github.com/rese1f/MovieChat?…
- MovieChat baseline: github.com/rese1f/MovieChat
1
4
20
3,259
👍 OpenAI's CriticGPT, not opensourced, language only
🤯 LMMs-Labs LLaVA-Critic, opensourced, for multimodal tasks
mindblown_meme.gif
4 Oct 2024

🚀🔥Introducing LLaVA-Critic--the first open-source large multimodal model designed to assess model performance across diverse multimodal tasks!
LLaVA-Critic excels in two primary scenarios:
- 👨⚖️LMM-as-a-Judge: It provides pointwise scores and pairwise rankings that closely align with human and GPT-4o preferences across multiple evaluation tasks, offering a viable open-source alternative to commercial GPT models.
- 🩷Preference Learning: It offers reliable reward signals that significantly enhance the visual chat capabilities of LMMs through preference alignment.
To develop the "critic" capacity, we curate LLaVA-Critic-113k, a high-quality critic instruction-following dataset tailored to provide quantitative judgment and the corresponding reasoning process across a range of complex evaluation settings.
Explore more:
- 📰Paper: arxiv.org/abs/2410.02712
- 🪐Project Page: llava-vl.github.io/blog/2024…
- 📦Dataset: huggingface.co/datasets/lmms…
- 🤗Models: huggingface.co/collections/l…
Try our released models and dataset👆

3
14
1,269
👍 SOTA Level Video Models
🤯 With Open-sourced Data and Training Recipes
mindblown_meme.gif
4 Oct 2024

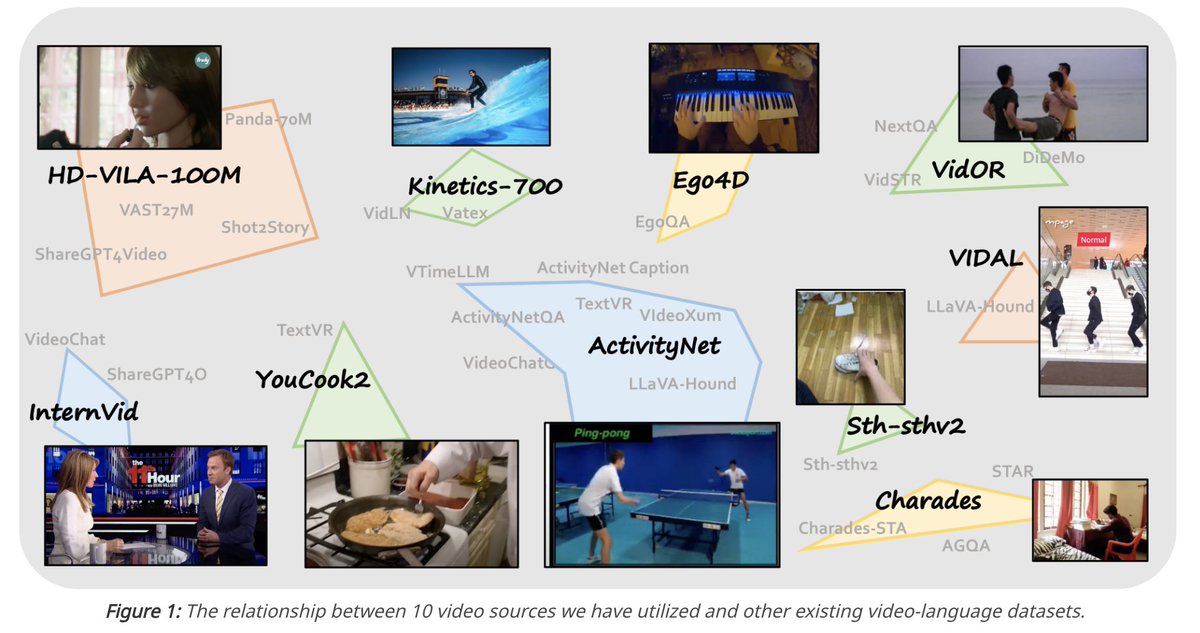
(1/4)🚀 Ready to supercharge your Video LLMs? 🎥Meet LLaVA-Video-178K, a high-quality dataset for video instruction tuning with 1.3M samples in captions, Q&A!
💡Perfect for further boosting Video LLMs, on top of strong capability transfer from image/language shown in LLaVA-OV🤖


4
15
2,032
lmms-lab retweeted

27 Sep 2024
We are organizing a new workshop on "Knowledge in Generative Models" at #ECCV2024 to explore how generative models learn representations of the visual world and how we can use them for downstream applications.
sites.google.com/ttic.edu/kn…
📅30 September 2024, 2 PM
27 Sep 2024

We are organizing a new workshop on "Knowledge in Generative Models" at #ECCV2024 to explore how generative models learn representations of the visual world and how we can use them for downstream applications.
For the schedule and more details, visit our website:
🔗Website: sites.google.com/ttic.edu/kn…
📅 Date: 30 September 2024, 2 PM
📍 Location: Brown 1, MiCo Milano, Italy 🇮🇹
🎤 Speakers: Amazing lineup to provide diverse perspectives: @davidbau, David Forsyth, @shalinidemello, @YGandelsman, @phillip_isola and @liuziwei7
Organizing with @DuXiaodan, @nickKolkin, @graceluo_, @ShuangL13799063 and @grshakh
See you all in Milano!

1
3
35
6,839
lmms-lab retweeted
5 Sep 2024
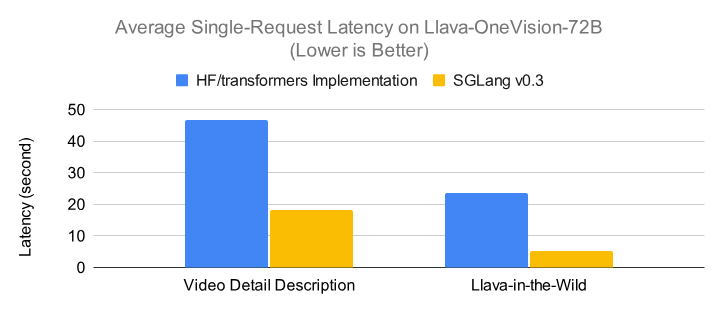
Great experience working with Lianmin to integrate LLaAV-OneVision into SGLang, and huge thanks to @PY_Z001 and @KaichenZhang358 to help finish this.
Try it on: github.com/sgl-project/sglan…
Directly try our demo (with SGLang SRT API service):
llava-onevision.lmms-lab.com…

We worked with the LLaVA team to integrate LLaVA-OneVision into SGLang v0.3. You can now launch a server and query it using the OpenAI-compatible vision API, supporting interleaved text, multi-image, and video formats.
8
22
2,438
lmms-lab retweeted
20 Jul 2024
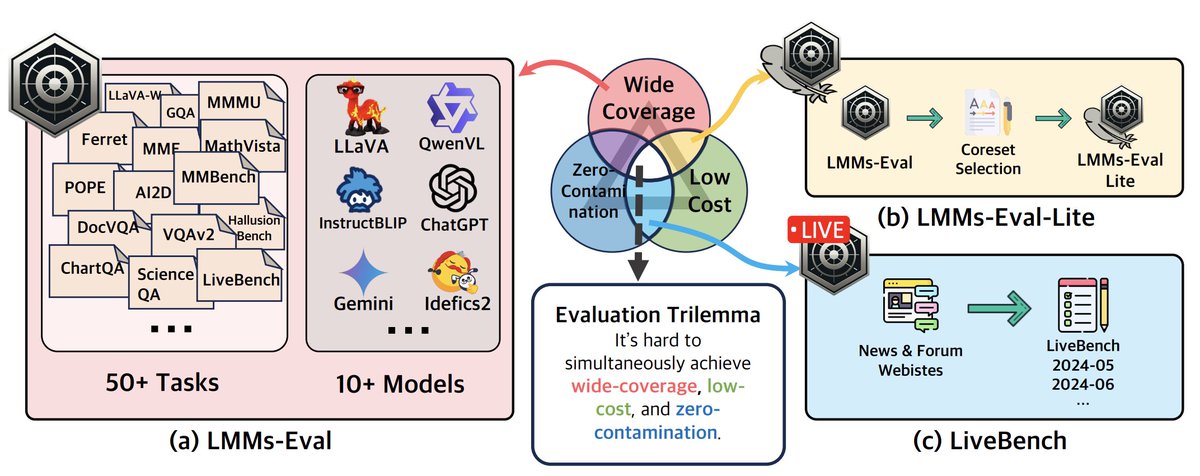
🔥Reality Evaluation on Large Multimodal Modals🔥
1)📊LMMs-Eval📊 integrates 80 datasets (image & video) and 10 models on HF @_akhaliq:
github.com/EvolvingLMMs-Lab/…
2)⚡️LiveBench⚡️ evaluates LMM's zero-shot generalization on most recent events @huggingface:
huggingface.co/spaces/lmms-l…
1
37
162
14,510
lmms-lab retweeted

10 Jul 2024
Very interesting work on a question I've been thinking a lot about: when can training a system on X' ~ G outperform training directly on X (where G is a gen model of X).
They find that retrieving task-relevant images from X outperforms sampling task-relevant images from G
1/n
10 Jul 2024

Will training on AI-generated synthetic data lead to the next frontier of vision models?🤔
Our new paper suggests NO—for now. Synthetic data doesn't magically enable generalization beyond the generator's original training set.
📜: arxiv.org/abs/2406.05184
Details below🧵(1/n)
6
23
202
38,300
lmms-lab retweeted
19 Jun 2024
🔥🔥 Lit, a super strong video demo, with a stronger upgraded video model behind 🔥🔥
19 Jun 2024

✊We've upgraded our LLaVA-NeXT-Video over the past two months, and the demo has been temporarily released to celebrate CVPR! Feel free to try it out!
Demo link: 2802e9e9a2970e5be6.gradio.li…
1
5
626
🌠🌠🌠Welcome to check our sota level video under standing model!
19 Jun 2024
✊We've upgraded our LLaVA-NeXT-Video over the past two months, and the demo has been temporarily released to celebrate CVPR! Feel free to try it out!
Demo link: 2802e9e9a2970e5be6.gradio.li…
213
lmms-lab retweeted

19 Jun 2024
✊We've upgraded our LLaVA-NeXT-Video over the past two months, and the demo has been temporarily released to celebrate CVPR! Feel free to try it out!
Demo link: 2802e9e9a2970e5be6.gradio.li…
2
3
28
4,737