Shao-Hua Sun retweeted

May 27
Introducing EXPO-FT – Efficient, Reliable & Open-Source VLA Finetuning!
EXPO-FT unlocks π0.5 for challenging manipulation tasks:
Routing string lights & inserting the power connector to illuminate them
Striking pool ball into pocket
Inserting flower into wine bottle
(1/5)
13
32
230
73,573

Putz, @matvelloso .. Eu estava aqui festejando, pois para um fine tuning, foi algo bacana... Mas aí ver o cara pular e falar um monte de besteira, sem saber o que é um finetuning, e ignorar que é um modelo chinês, meu Jesus amado. No máximo, deveria ser um post parabenizando o time
2

1h
I’ll retrain the 500M 1920s model from scratch again
Then do some instruct finetuning so it’s conversational, it was just base checkpoints before
The data is mainly Gutenberg but all slop filtered out
3
138


Sarvam is a scam. They're just dependant on handouts from indian government. The members are sarvam are formed by ai4bharat which was funded by indian government. They have no novel research. They're just collecting data and finetuning opensource models. When asked about models they are complaning thay indian government did not provide them gpus. 😂😂
14

LoRA in simple terms: Instead of updating all weights, you train small low-rank matrices that get added to the original model. Result: much lower memory compute, similar performance for many tasks. #FineTuning
12

Por ser especialista em IA, digo justamente isso. Eu acho que foi dahora o que eles fizeram, usaram uma técnica interessante para fazer o finetuning, porém EU ELZO BRITO, não acho que gastar 500k para treinar um modelo que ninguém vai usar um bom negócio.
Até falei isso pro pesquisador que treinou o modelo, se eles não podem treinar modelos menores e quantizados, para que muito mais pessoas usem, vejo mais sentido em treinar um modelo do tamanho Gemma4:e2b que treinar um modelo gigante.
1
28

i guess you don't believe in the country of geniuses, cause doing finetuning only has short term relevancy
9

O povo falando besteira sobre o finetuning do RIO 3.5
vocês tem noção que isso é o começo de um movimento da cadeia?
vai tu fazer finetuning em 397B porra
depois é pre train original e o SOTA vai ser nosso
35

let's all ask codex to make a dataset of all our claude code sessions with fable for qlora finetuning and rent a gpu to train a small-ish open source model on our fable outputs
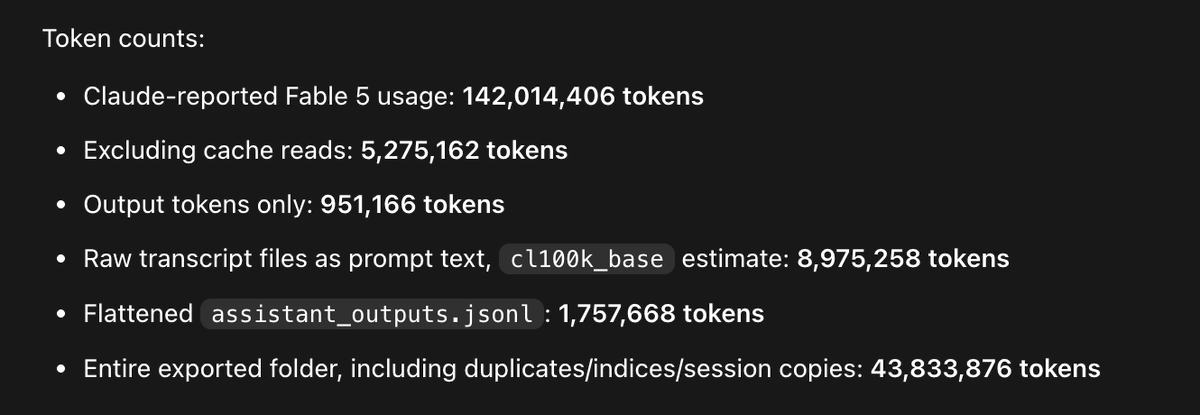
46


imho the first step would be a company doing what cursor does with composer, a top tier class model finetuning an open source model
1
1
163

Pior que nem foi um simples FineTuning, mexeram pesado no modelo, e olha que é o modelo antigo do Qwen 🤣
576

Different optimization definitely leads to different outcomes after finetuning arxiv.org/abs/2605.02105
2
85


Même s'ils visent un domaine en particulier, c'est déjà trop tard et la régulation nous empêche d'évoluer (inversion de la charge de preuve pour l'entrainement avec données protégées par droit d'auteur). De plus, impossible de faire un LLM spécialisé sur du code par exemple s'il n'est pas un minimum bon dans d'autres domaines (maths, logique, etc...).. Les modèles bon en code le sont aussi dans d'autres domaines, c'est obligatoire... Pour moi le LLM spécialisé est un mythe, a la limite tu finetune un modèle de fondation et c'est tout (comme Qwen Coder est un finetuning du modèle de fondation Qwen).
1
18

Compute:
We were the first team in India to train at scale. We trained the sovereign models at the scale of ~3400 H100s. We are now putting serious capital behind the next step. India's first Blackwell cluster is now online and used by us, and we are building momentum towards operating 10s of megawatts in compute on Indian soil by 2027.
Models:
With Sarvam 105B, India's first sovereign model built from scratch, we showed that highly capable models can be trained here, independently. More importantly, the capability is now compounding across data, training, evaluation, systems, alignment, and deployment intuition. And we are scaling up to trillion-parameter class models, with larger runs built for coding, agents, and security. A coding model is coming soon...
Inference:
We already host our own models, with third party usage tripling in the last three months. We are soon taking live a production-grade token factory with the price, throughput, latency, reliability, and governance that banks, governments, enterprises, startups, and developers need for real systems.
Products:
Our products are now reaching India scale. Voice was our first wedge. It powers millions of interactions per day, doubling in the last three months, while we continue to optimise costs. Like voice, another modality at scale in India is documents, and we are hitting exponential growth of our new document intelligence product. Our fully managed agents product is live with enterprises and is being launched for all next month.
Deployment:
Most of the value in AI is unlocked in the last mile. We learned that by doing it across engagements in enterprises, government, and strategic sectors. Now we are turning that learning into a platform that allows every organisation to hill climb on its own use cases - whether it is building an agent, customising the harness, creating the data/tool backbone, or finetuning the model on custom data.
Talent:
Serious researchers are joining us across pretraining and RL, including people who have done meaningful work at the frontier. We are also starting our San Francisco office as the conduit for frontier AI ambition for India first, then the world.
18
105
620
34,461

practically speaking, if you're building agents: you can get way better error correction by just moving the model's intermediate reasoning into a different role slot before asking it to verify. no finetuning, no external verifier, no weight changes. just prompt structure.
1
4