
2000 PDF’in var ama içinde ne geçtiğini sen bile bilmiyorsun.
Chatbot yapacaksın ama hangi belgeyi okuyacak?
Hangisinden ne getirecek?
Evet yine Microsoft.
GraphRAG;
- Belgelerden bilgi grafiği çıkarır
- Konuları gruplar, özetler
- Bağlantıları anlamlandırır
- LLM’e doğru veriyi doğru anda verir
İncele;
👉 github.com/microsoft/graphra…
----------
Yapay zeka hakkında güncel kalmak için
👉 lnkd.in/d6dqu8WR

9


Done with GraphRAG. Next up is caching... But before that, it's time for the absolute worst thing in programming: writing tests and debugging.
Building an AI-based applications, is a special kind of torture.
Does anyone even like writing tests? Especially for personal projects?
1
3

4 Ele mesmo disse que precisou trocar "duas ou três palavras" do que a IA devolveu. Mas o que realmente chama atenção é que ele descreve haver por trás um ferramental composto por DAG, 24 agentes, 70 tasks, RAG e GraphRAG pra, no fim, reescrever um texto.
1
6

!知识库GraphRAG实践3种检索问答方式对白盒化拆解7个RAG问题案例参考
这期视频完整复盘一次 GNN-RAG 教学实验:先展示“三国文学 GraphRAG GNN 问答台”,用《三国演义》桃园结义和张飞怒鞭督邮两段情节,对比普通向量检索和融合 GNN 检索在生成答案、召回上下文、三元组和右侧图谱上的差异。
然后用 RAGLab 拆解两个流程:Simple RAG 的基础工作流,以及 GNN Hybrid RAG 中的实体抽取、图谱构建、图谱检索、GNN 传播和图谱融合。最后结合 HTML 复盘页,系统讲解我们遇到的 7 个坑:多检索方式召回拉不开差距、图结构相关不等于问题相关、GNN 命中节点不等于命中原文证据、Hybrid 融合噪声、问题设计不合理、自动评估分数误导,以及“无法回答”导致 RAGAS 接近 0 分。
这不是一个只展示成功结果的视频,而是一次完整的 GNN-RAG 实验排坑:怎么设计跨章节多跳问题,怎么看 retrieved contexts,怎么理解图谱路径,怎么避免 GNN 召回污染上下文,以及为什么自动评分必须结合人工复核。
21
Richard Delahaye retweeted

Feb 27
RAG vs GraphRAG vs KAG
Retrieval Augmented Generation (RAG), GraphRAG, and Knowledge Augmented Generation (KAG) represent successive attempts to ground large language models in structured or semi-structured knowledge.
From a graph practitioner’s perspective, the key questions are not prompt engineering but representation, identity, semantics, and the execution model.
Classical RAG emerged as a pragmatic response to the limitations of LLMs. Instead of attempting to encode all knowledge in model parameters, the approach externalised knowledge into vector indexes. Documents were chunked, embedded, and retrieved via similarity search.
The architecture was intentionally simple: a retriever, a vector store, and a generator. It did not require graph modelling, ontology design, or explicit semantics.
GraphRAG appeared later as practitioners recognised that document chunks lack explicit structure. Real-world data contains entities, relationships, hierarchies, temporal aspects, and constraints.
GraphRAG introduced graph traversal into the retrieval step. Instead of retrieving isolated chunks, it retrieves neighbourhoods of connected entities. It is important to emphasise that GraphRAG is an umbrella term rather than a formal standard.
Implementations vary widely in how graphs are constructed, traversed, and integrated with embeddings and retrieval. This reflects a shift from similarity-based recall to structure-aware retrieval.
KAG developed in parallel as a broader architectural idea. Rather than only improving retrieval, it aims to integrate a knowledge graph as a reasoning substrate. In this view, the graph is not merely a retriever index but a semantic backbone.
In practice, KAG varies significantly in implementation, from ontology-centric systems realised over RDF triple stores to Applied Knowledge Graphs implemented using the LPG model.
From a graph engineering perspective, these approaches differ in how seriously they treat identity, relationships, inference, and graph execution engines.
Sergey Vasiliev examines the different Graph Models and their realisations, does a comparative analysis and shows the architectural trade-offs, and offers practical guidance and a conclusion.
sergeyvasiliev.substack.com/…
#RAG #GraphRAG #LLMs #GenAI
--
Connected Data London 2025 brought together leaders and innovators. Were you there?
🎥 Watch the sessions: 2025.connected-data.london/
📩 Join the community: connected-data.london
Join community legends and new voices for all things #KnowledgeGraph #Graph #analytics #datascience #AI #graphDB #SemTech #Ontology

2
9
1,147
Richard Delahaye retweeted

Jun 10
I spent months optimizing GraphRAG retrieval.
But it turned out I was optimizing the wrong thing....
The biggest knowledge graph problems usually occur during ingestion (even though most conversations focus on retrieval).
Every new document creates a risk of graph corruption.
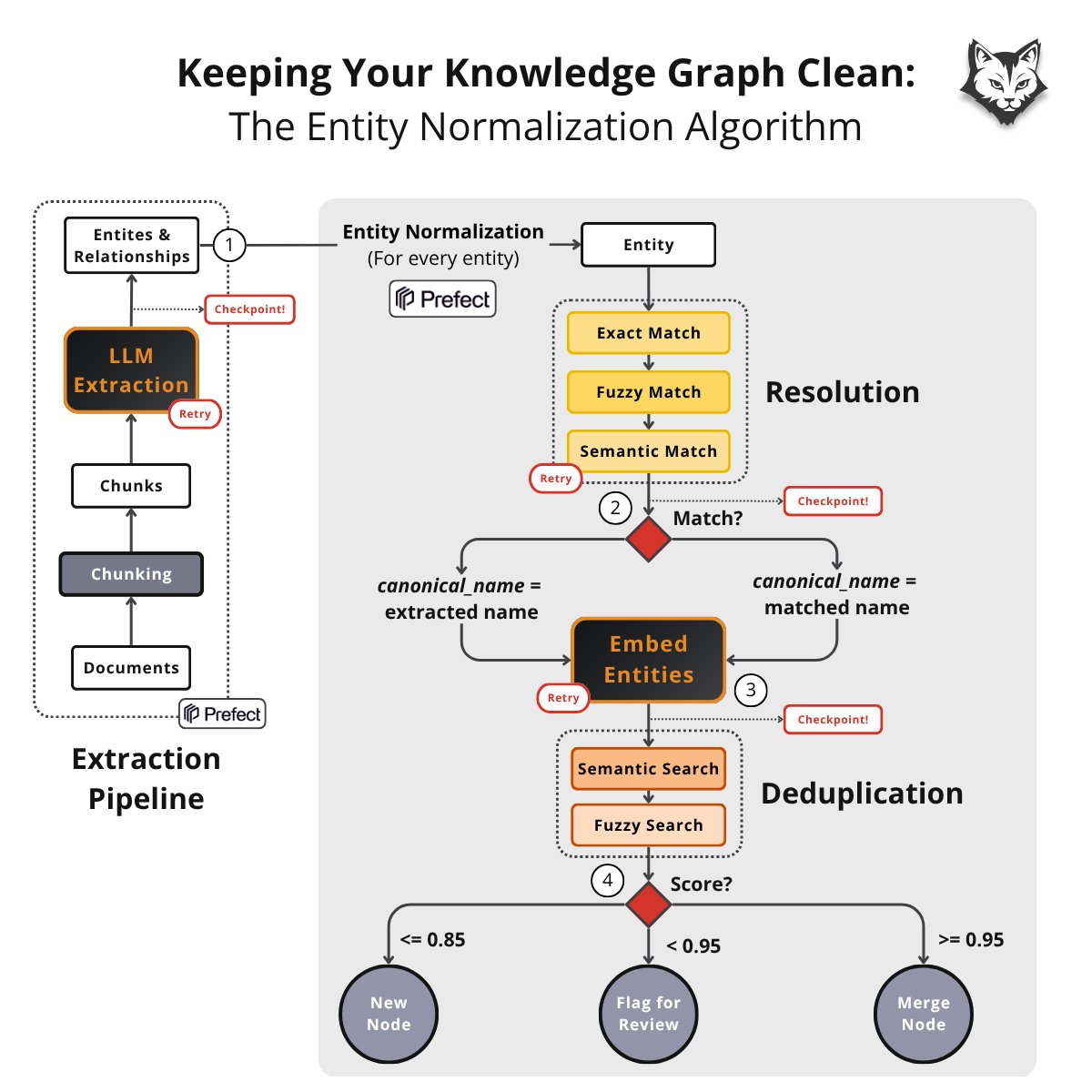
This is why I now think about knowledge graph ingestion as a 5-step pipeline:
1/ Extraction
Convert raw text into entities and relationships.
For example: Person → WORKS_AT → Organization
The goal is to extract what your ontology cares about.
2/ Resolution
This step standardizes names.
For example:
NYC → New York City
P Morgan → JPMorgan Chase
Jon Smith → John Smith
Most importantly, nothing has been merged yet.
3/ Embedding
Next, embed the entity's full context (not just the name).
Think:
Type
Attributes
Metadata
Relevant content
Because identity lives in context.
4/ Deduplication
Many systems fail here.
Because:
Apple the company ≠ Apple the fruit
Paris, France ≠ Paris, Texas
Two people can share the same name
Resolution answers naming.
Deduplication answers identity.
Those are two completely different jobs.
5/ Routing
Finally, the system decides:
Merge
Human review
Create new node
And the best systems follow a simple rule:
Evidence strength = permission strength.
Weak evidence → new node
Strong evidence → merge
Uncertain evidence → human review
Because false merges are expensive.
A duplicate node is annoying.
But a corrupted graph can silently poison retrieval quality for months.
My biggest takeaway?
Knowledge graph quality isn't determined by your retrieval strategy...
It's determined by the pipeline that creates the graph in the first place.
Get these five steps right... and retrieval becomes much easier.
P.S. I break down the full pipeline, entity resolution, deduplication thresholds, review queues, and production architecture in Decoding AI Magazine
Check it out here: decodingai.com/p/keep-knowle…
1
20
60
2,800

🚀 Neo4j Workshop III: GraphRAG & GenAI starts TODAY at 11:00 AM EAT!
Learn how GraphRAG makes AI apps smarter and more reliable.
🌐 Join Online: luma.com/xqv8fjn4
@DirectEdDev @AiKenya1 @MC_AgriFin

13

22h
Claude Fable 5 is built for loops. Claude Code /goal runs them. But neither can self-correct without seeing your codebase architecture — imports, call chains, and hidden dependencies.
Octocode is the structural memory layer. It gives any MCP client a live knowledge graph: semantic search, GraphRAG, and signature views across 15 languages.
Your agent stops guessing and starts understanding.
Fable 5 provides the loop. Octocode provides the eyes.
1
49

22h
helixdb showed up on HN this week and the architecture choice is the story.
graph-vector database in rust, built on object storage. not "we bolted a vector index onto neo4j" — the storage substrate is s3-compatible, writer/reader split, cache-on-ssd. infinite scale at object-storage prices.
founders: george curtis, matt sanetra, xav (top committer with 2k commits — 6x the next dev). yc batch, backed by nvidia and vercel. london sf.
5,035 stars on github, 153-point Show HN on june 10. the bet i keep coming back to: graphrag is the agent-memory architecture nobody wants to admit they need. vector-only retrieval forgets relationships, graph-only forgets semantics. whoever owns the hybrid substrate at the right price point eats the agent-memory layer.
kill-shot risk: native graph dbs (neo4j) have 20 years of query optimization. helix has to beat that AND make object-storage latencies feel native. their nov '25 benchmarks looked strong on edges-as-joins, but agentic-workload benchmarks don't exist yet — and that's the workload that matters.
what i'm watching: do letta, mem0, or supermemory adopt helix as a backend? if any one of them does, the memory wars collapse into a storage layer and helix is at the bottom of the stack.
github.com/HelixDB/helix-db
2
1
143

Neo4j Graph AnalyticsではCypherクエリできない(GraphRAGや知識グラフとして使えない)んだけど、Neo4j Virtual Graphだともしかしてできるのか。Available now in previewとあるけど、どういう形態で利用できるんだろう。
neo4j.com/product/virtual-gr…
66

🏗️ Coherent Product Strategies for LLM & Agentic Systems — the critical strategic & platform layer that prevents fragmentation, duplicated efforts, inconsistent experiences, and technical debt while turning abundant LLM possibilities into focused, high-impact, scalable products.
Just read this excellent grand finale technical white paper from @aasaitech — the perfect synthesis and conclusion to the entire series.
Key highlights: • 5-step Use Case Prioritization Framework (Business Impact, Technical Feasibility, Effort, Risk, Strategic Alignment) • Coherent Architecture Principles: Modular & composable, standardized interfaces, shared platforms (build once, leverage many) • Platform Thinking: Unified core (NLU, RAG/GraphRAG, Reasoning, Orchestration, Guardrails) powering multiple products • Coherent vs Fragmented approaches end-to-end strategic execution and success metrics
This is how industrial organizations avoid chaos and deliver sustained competitive advantage in manufacturing, maintenance copilots, edge orchestration, and beyond.
Full white paper infographic: x.com/aasaitech/status/20656…
How coherent is your LLM product strategy — shared modular platforms with strong prioritization, or still fighting fragmentation across teams and use cases?
#CoherentAIProductStrategy #PlatformThinking #IndustrialAI #AgenticAI #LLMStrategy #ManufacturingAI #EdgeAI

1
17