
Jun 12
Rethinking Breast Cancer Diagnosis through Deep Learning Based Image Recognition
mdpi.com/1424-8220/23/4/2307
#breast_cancer #image_classification

1
42
May 19
PLG-ViT: Vision Transformer with Parallel Local and Global Self-Attention
mdpi.com/1424-8220/23/7/3447
#image_classification #object_detection
1
3
115
Jan 22
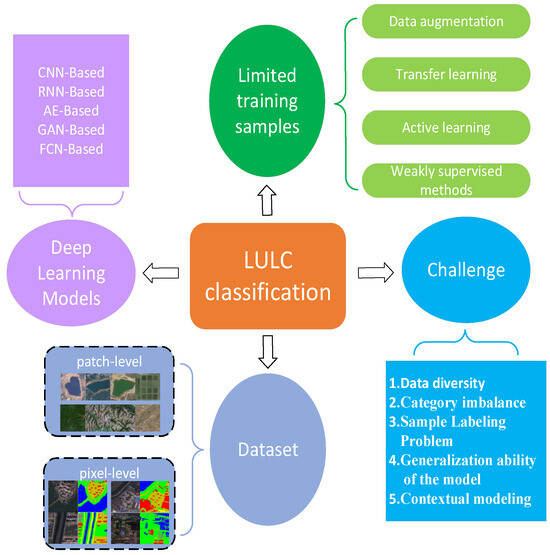
Land Use and Land Cover Classification Meets Deep Learning: A Review
mdpi.com/1424-8220/23/21/896…
#image_classification #remote_sensing
1
63

6 May 2024
just added an image_classification script to @TheZachMueller repo 🥳🥳
the cool part is that it shows you how to train your custom model with the trainer API.
make sure to give it a star if you love it 🌟
github.com/muellerzr/minimal…
1
8
2,370
19 Jan 2024
#highlycitedpaper
Explainable Artificial Intelligence for Bias Detection in COVID CT-Scan Classifiers
mdpi.com/1424-8220/21/16/565…
#computer_vision #Computerized_Tomography #Covid_19 #Explainable_AI #image_classification #medical_imaging

1
108

14 Dec 2023
💕New Special Issue "Deep Learning in Computer Vision", edited by Dr. Dong Zhang, from @hkust and Dr. Rui Yan, from @njuniversity, mdpi.com/si/191790
⏰Submission deadline: 15 September 2024
📩Welcome to contribute
#deep_learning #computer_vision
#image_classification

1
2
88

8 Dec 2020
Last video I explained how to data preprocess the data for fashion minst this time around I show everyone how to take that data to create a working model. #tensorflow #pythonprogramming #image_classification #numpy #machinelearning #artificialintelligence youtu.be/iliJsLF-zks

2
2


20 Jul 2018
Our paper "Boosting image classification through semantic attention filtering strategies" is already published in Elsevier @comp_science journal Pattern Recognition Letters! #image_classification #Computer_Vision #TOIC #Security
authors.elsevier.com/a/1XNyB…
1

14 May 2018
RMDL: Random Multimodel Deep Learning for Classification
GitHub: github.com/kk7nc/RMDL #DeepLearning #classification #MachineLearning #deep_neural_networks #Image_Classification #Text_Classification #EnsembleLearning
1
2

7 Nov 2017
The easy-to-use hyperparameter_tuning Image_Classification library is released under MIT Licence at github.com/anuragmishracse/s… , abbreviated as "smic".
Available to install from PyPI: pypi.python.org/pypi/smic/1.…
Built on top of Keras, thanks @fchollet . Suggestions welcome!
1
2
1