Space Initiatives retweeted

Jun 13
That is IC lightning, so-called "sympathetic" intracloud or intercloud lightning. the storm is some distance away. The sky is domed with a specific charged diffracted status layer, from which the cell draws energy. Clouds without visible lightning sometimes produce very powerful thunder, which is synthesized from cavity resonances, and is actually low noise: its waveform can readily be decomposed through a Fourier cosine transform to show a discrete eigendistribution that is the same modes as would lightning produced in such a cloud be comprised of in its discrete sine transform.
2
1
1
176

Apr 8
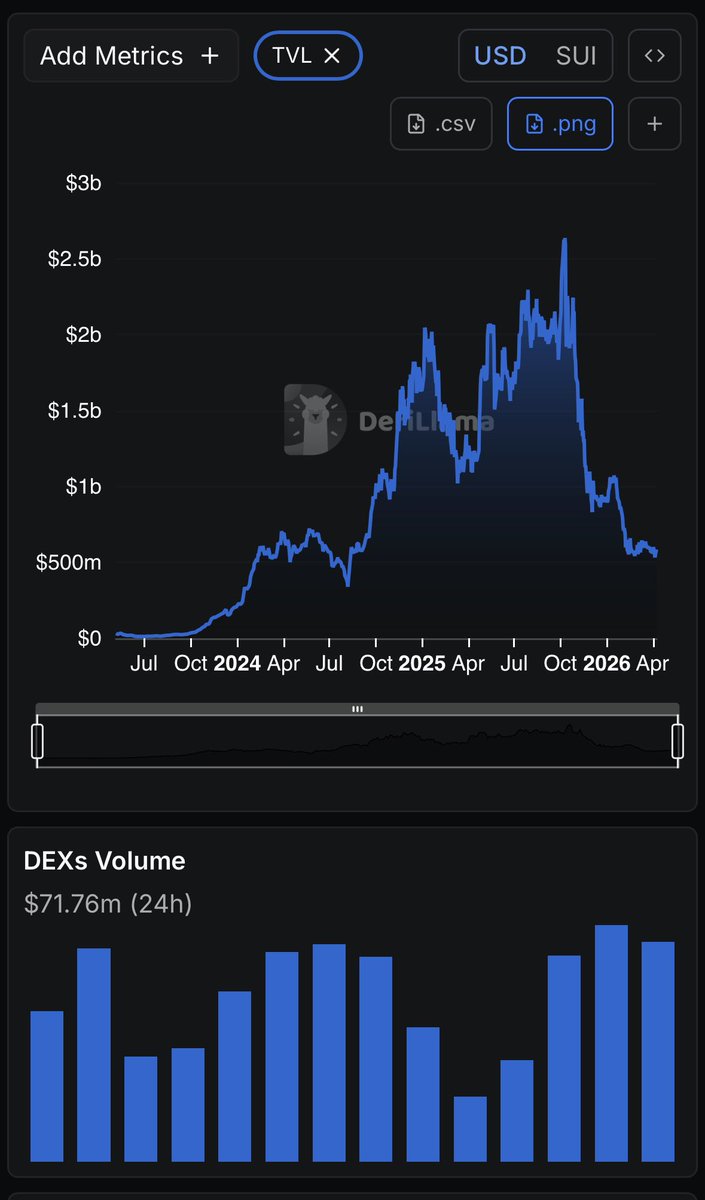
.@SuiNetwork & @Mysten_Labs in 2026 — here’s what’s actually happening.
-Private transactions confirmed for 2026.
Co-founder @EmanAbio : users won’t even need to opt in — privacy will be built directly into Sui payments by default. Regulatory compliant. No compromises.
-Alibaba Cloud partnership.
AI-powered Move coding assistant launched. Developer activity up 40%. TVL went from $200M → $1.5B in 2025. 2.5M daily active addresses.
-InterCloud Anapaya (SCION network).
Sui validator nodes now run on SCION architecture — isolated, resilient network paths that eliminate single points of failure and protect against IP-level attacks.  This is next-level infrastructure.
-EVE Frontier Square Enix XOCIETY.
Sui is the native blockchain layer for EVE Frontier. SuiPlay0X1 — the first blockchain gaming handheld — is live.  Square Enix is also building on Sui. 
The bigger vision:
Sui isn’t positioning itself as just another blockchain — it’s being built as a global coordination layer for the internet, with a target market far beyond traditional crypto ecosystems. 
#Sui @DefiLlama
1
4
41
1,390


Feb 20
Afternoon GMT 7. Cloud bills say “pay for what you use” while egress traps, cross‑zone tolls, credit expiry and SLA fog hide the real tax
I routed our Feb AWS GCP Azure spend onto receipts rails via @allscaleio; here’s what printed:
• Pricing/Rules: on‑demand vs reserved/savings/committed; spot/preemptible clocks; egress zone/region/intercloud; NAT/LB per‑GB; log ingest/scan; support tier; credit expiry; FX lock
• Proofs: SKU/rate‑card hash; usage IDs region/zone stamps; flow logs; K8s control‑plane meters; incident IDs; change‑ticket binds; policy/version hash
• Remedies: auto credit on egress misband, cross‑zone mischarge, expired credit applied post window, support tier misbilled, outage past SLA without credit; minute‑level settlement to $USDC $USDT $EURC or $AS under self custody
Next: rate‑parity boards by region/service, egress maps and outage‑clock ledgers; clean audits mint $ASP
#AllScale #Cloud #FinOps #DevOps #Transparency #Stablecoins $AS $USDC $USDT $EURC $ASP

4
5
203

Broadly, the "2026 Era" is described by tech experts as the "Era of Interconnectivity." * Intercloud Integration: Companies will no longer use just one cloud provider (like AWS or Google). #ITLG #ITLX #ITL #InterLink @C_Interlinklabs @reina_itl @kv_interlink

3
21

18 Nov 2025
"We are seeing a lot more #AI-driven conversations around #vector embeddings with #multicloud and intercloud support."💡
Discover how #YugabyteDB is bringing #AI vectors and data modernization to #distributedSQL in this new article from @bluefug for @Intellyx:
na2.hubs.ly/H025Gpt0

4
127

6 Nov 2025
$MU $SNDK $STX The architecture described replaces multi-tier hot–warm–cold storage with a single, uniformly high-throughput object store that prices data by recency but keeps every object immediately accessible at line-rate, with stated throughput up to 7 GB/s per GPU and zero request, retrieval, or egress fees. A representative 20 PB AI corpus is modeled with 20% monthly ingest, 30% reads, and 30% intercloud egress; under these conditions the usage-aware design yields a blended $0.026/GB-month and a $0.545M total monthly bill versus $0.779M for S3 Standard and $2.644M for S3 Express One Zone. The scenarios section quantifies 3–5 hour restore delays under tiered architectures and the resulting idle time on 512 GPUs for 4 hours costing $30K–$50K. These elements collectively favor all-flash storage because the operational goal is to eliminate rehydration latency across the entire dataset, not only a working set, while sustaining multi-GB/s per GPU feed rates that hard disk-based tiers cannot reliably provide without introducing bottlenecks or cache misses. The economic signal is explicit: consistent, flash-class performance is being extended to the “cold” majority of AI data and made financially palatable by usage-aware billing rather than by demoting bytes to slower media. This combination increases NAND bit demand structurally by shifting large AI datasets—and their long tails of inactive artifacts—onto flash-backed systems by design. 
The removal of retrieval and egress tolls creates elasticity in data retention and duplication that further expands flash consumption. When access taxes go to $0, teams no longer suppress secondary copies, cross-cloud collaboration, or long-term retention of checkpoints, logs, and intermediate artifacts. The assumptions table formalizes this with 30% monthly egress and 30% monthly reads on a 20 PB corpus—behavior that would be rationed under per-request and egress fee structures but is encouraged in a zero-toll model. More traffic across a uniformly hot object store means more bytes stay resident on high-performance media for longer periods, directly lifting the total NAND under management. The same cost model shows that lower “headline” $/GB on legacy hot tiers does not translate to lower all-in cost once access taxes are included; this reverses the historical economic argument for pushing most bytes to HDD- or tape-backed archives and is therefore positive for NAND mix. 
The performance target of up to 7 GB/s per GPU implies flash-centric designs at both the back-end object layer and the front-end servers. Sustaining multi-GB/s streams per accelerator requires parallel NVMe and low-latency media; the document frames a system where performance parity is maintained across billing levels instead of migrating objects to slower tiers. The practical result is a twofold pull on NAND: large all-flash object clusters sized in the tens of petabytes to hold full AI corpora, and significant local NVMe capacity on GPU nodes to avoid pipeline stalls. As AI estates scale from hundreds to thousands of GPUs, local NVMe footprints reach multi-petabyte aggregates, while back-end all-flash object stores grow faster than linearly due to replication, erasure coding, and multi-region resilience, which add 20–80% overhead depending on policy. This architectural stance makes flash the default substrate for both persistent lakes and transient staging, expanding enterprise SSD unit volumes and average capacities. 
The workload characteristics highlighted are favorable for QLC-heavy enterprise SSD portfolios. The 20 PB example assumes 30% reads and heavy reuse of artifacts; the scenarios stress immediate reaccess to historical outputs for regression analysis and audit, and the usage-aware system is explicitly designed for “keep everything” while avoiding restore lag. Read-dominant, large-object, append-heavy AI pipelines align with QLC endurance profiles, enabling vendors to ship higher-capacity, lower-cost drives without prohibitive write wear. As usage-aware pricing makes flash-resident retention economical for the 60–80% of data that is typically inactive, the physical media does not change even as the bill drops; the billing shift therefore operates as a demand catalyst for QLC/PLC layers rather than a substitution back to HDD. The claimed cost reductions of “more than 75%” achieved by existing users in this model increase the budget headroom to store more data hot, reinforcing a positive volume feedback loop for NAND suppliers. 
The operational consequences of eliminating rehydration are pivotal for capital allocation in AI infrastructure and translate into NAND pull-through. The scenario with 3–5 hour restore delays shows that tiering-induced latency idles expensive GPU fleets, which drives platform teams toward architectures that guarantee instantaneous access across the entire corpus. When downtime on 512 GPUs for 4 hours destroys $30K–$50K of compute utility per incident, the TCO equation tilts decisively toward all-flash designs even at a higher nominal $/GB, because the opportunity cost of slow media dominates. Usage-aware billing arbitrages this by preserving flash performance while charging based on recency, neutralizing the primary economic reason to demote data. The resulting standardization on flash-like performance for all objects, including “cold,” implies sustained expansion of enterprise SSD deployments and rising NAND content per AI dollar spent. 
The cost-comparison table underscores that once request, retrieval, and egress charges are internalized, a usage-aware, single-tier object store competes favorably against hot tiers at hyperscalers on an all-in basis. With a $0.545M monthly bill versus $0.779M–$1.010M for mainstream hot tiers, users gain both speed and predictability while cutting cost. This releases budget that historically funded archive tiers or lifecycle tooling and redirects it to higher-performance capacity. The redirection increases the addressable market for NAND at the expense of HDD/tape, because the architecture’s stated premise keeps all objects on a high-throughput substrate rather than migrating them physically to slow media. The economic gradient therefore supports a mix shift toward all-flash object storage in AI centers, which expands NAND bit shipments in both capacity drives and high-throughput NVMe formats. 
Investment implications are favorable for NAND producers with scale 3D NAND roadmaps and strong enterprise SSD franchises. The described model increases elastic demand for high-capacity NVMe and all-flash arrays, reduces customers’ incentive to prune data aggressively, and encourages multi-copy replication and cross-cloud sharing by zeroing out access taxes. These behaviors raise total bytes stored on flash, increase average SSD capacity per server, and extend data retention windows on NAND instead of HDD. Suppliers leveraged to QLC/PLC transitions and to high-power E1.S/E3.S form factors should see outsized benefit as AI clusters densify storage per rack to feed accelerators. Controller vendors and SSD assemblers benefit as unit volumes rise, but the primary beneficiary is upstream NAND bit demand, which becomes tied to the secular growth of AI corpora rather than the cyclical backup/archive market. The model also reduces the risk of sudden demand cliffs from tiering-policy optimizations, because billing, not media migration, is used to manage cost; that stabilizes utilization at all-flash object stores and supports more predictable procurement of NAND over multi-quarter horizons. 
Key risks to the bullish NAND view include aggressive compression and deduplication that lower effective stored bytes, hyperscaler responses that bundle low-latency object performance with HDD-backed tiers via larger caches, and potential reintroduction of access taxation by providers if zero-fee models prove economically unsustainable. Even under these scenarios, the need to guarantee instantaneous access across large AI corpora to protect GPU utilization keeps a substantial flash cache layer in the architecture, preserving a material baseline of NAND demand. The net effect of a usage-aware, performance-parity object store is a durable mix shift toward flash-first storage for AI, which is structurally bullish for NAND bit growth and enterprise SSD penetration. 
6 Nov 2025

could you please elaborate how “cutting costs by up to 75%” is bullish for NAND?
and why NAND and not HDDs for this?
5
4
62
14,377

Hey Nick, Here are some options. If you would like a bigger list / selection just drop me a DM :
Jackpot. ai
Embargo. ai
Ascension. ai
ReRun. ai
GameFi. ai
Kody. ai
Altcoin. ai
Shiba. ai
Airdrops. ai
Payable. ai
ABET. ai
NetSuite. ai
RisingSun. ai
PayBot. ai
Hillman. ai
Tetris. ai
Downloader. ai
DevCon. ai
InterCloud. ai
SecurePay. ai
SecureNet. ai
ACompany. ai
RedPoint. ai
MoneyFlow. ai
GoCompare. ai
PayNet. ai
DataDrop. ai
WorldPay. ai
HashPower. ai
YieldFarm. ai
SharePay. ai
OpenFinance. ai
HyperCast. ai
CloudFront. ai
FutureHealth. ai
HomeGenie. ai
DreamPath. ai
PremierHealth. ai
CloudMe. ai
ChainPay. ai
FinBox. ai
FastNet. ai
CourseHero. ai
SmartBanking. ai
GlobalPayments. ai
AlgoBot. ai
CoinBit. ai
TradePay. ai
SafeTrade. ai
Tickers. ai
Agrobotics. ai
Trawler. ai
4
36
6,362

3 Oct 2025
@Livepeer : Video infrastructure network with a P2P marketplace where users get to contribute GPU resources for workloads such as AI-powered video processing and transcoding.
@nosana_ai : GPU marketplace for AI inference, where AI users can plug in to access cheap computing power provided by GPU owners with idle computing hardware.
@aleph_im : Cloud computing P2P network that provides decentralized storage, confidential computing, and access to GPU resources for high-performance workloads.
@gensynai : Machine learning computation protocol, with a global marketplace for AI compute. It connects people with unused hardware, including GPUs, with devs who need the computational power to train AI models.
@CUDOS_ : CUDOS Intercloud provides access to globally distributed computing resources, such as GPUs and CPUs, for AI, high-performance computing, Web3, and rendering workloads.
@ASI_Alliance : ASICloud is a GPU Cloud and AI inference platform by @CUDOS_ and @SingularityNET that evolves CUDOS Intercloud into an AI compute layer and provides access to a GPU marketplace with enterprise-grade hardware.
@RunOnFlux : FluxEdge offers a decentralized GPU compute cloud that allows users to access, rent out, or utilize GPU power for tasks like AI model training and LLM execution.
@vast_ai : P2P GPU marketplace that makes enterprise-grade GPUs globally accessible at affordable prices, offering up to 5-6X savings on GPU compute.
@AIOZNetwork : DePIN platform powered by a global network of Edge Nodes. It allows users to contribute their idle GPU and CPU resources to power services like AI model training and video processing.
@exa_bits : Global GPU network that includes both enterprise-grade GPUs from its data centers and consumer GPUs from users, creating a large, accessible pool of computing resources.
@nodeshiftai : Decentralized cloud platform that aggregates GPU and storage resources from independent data centers globally, making them available via a unified interface at reduced costs.
@fluidstack : Distributed computing platform that provides on-demand GPU and CPU power to AI companies and enterprises by pooling idle server resources from a network of data centers.
@GamerHashCom : Decentralized platform that allows gamers to earn by contributing their idle GPU computing power, which is primarily used for crypto mining and AI inference.
1
4
552

26 Sep 2025
18
35
320
74,313

24 Sep 2025
ASI:Cloud evoluciona CUDOS Intercloud en la capa de cómputo de la @ASI_Alliance.
🌐 Lo que ya está live hoy:
• Inferencia LLM lista para API
• Precios per-token
• Acceso vía wallet
• Modelos potentes
• Login con ASI Wallet
• Nuevo dashboard
• Y créditos para desplegar 🚀
1
2
36

ASI:Cloud evolves CUDOS Intercloud into the compute layer of the @ASI_Alliance.
🌐 What’s live today:
• API-ready LLM inference
• Per-token pricing
• Wallet-based access
• Powerful models
• ASI wallet login
• New dashboard
• And credits to deploy
1
6
153

11 Sep 2025
(5) Kudos, CUDOS ☁️✨
The Intercloud is growing to new heights, and Squid is powering cross-chain payments with UX that feels light as air.

May was all cloud, and CUDOS Intercloud hit new highs:
🔧 First @ASI_Alliance containerised hardware deployment
💸 @squidrouter live with 70 chains for payments
📈 Record high revenue and GPU hours
🌐 @Consensus2025 insights
Read the full recap here 👇
cudos.org/blog/the-may-cudos…

1
5
171
Every agent needs compute. Every model needs inference. And every intelligence stack needs to be free of enterprise choke points.
That’s why @CUDOS_ Intercloud matters.
Legacy GPU clouds weren’t built for #Web3 devs.
They were built for enterprise lock-in.
🔒CUDOS Intercloud flips the stack:
👛 Wallet-auth compute
🧠 #AI validator workloads
🔁 Pay from 70 chains
Early access is live. 📣
📧 Join with your email → cudos.org?utm_source=twitter…

1
21
204
8,934
Legacy GPU clouds weren’t built for #Web3 devs.
They were built for enterprise lock-in.
🔒CUDOS Intercloud flips the stack:
👛 Wallet-auth compute
🧠 #AI validator workloads
🔁 Pay from 70 chains
Early access is live. 📣
📧 Join with your email → cudos.org?utm_source=twitter…
2
6
28
10,912

28 Aug 2025
Relying on centralized clouds means giving up control; logging, profiling and throttling creep into your pipeline.
With CUDOS Intercloud, developers can deploy private AI workloads with wallet-level access and no KYC friction.
It’s compute that moves at the pace you build, not the pace dictated by someone else’s infrastructure.
Running compute on centralized clouds?
You're exposing your pipeline to:
👁️ Logging
🛂 Identity profiling
🚫 Throttling
CUDOS Intercloud offers:
👛 Wallet access
🧠 Private #AI execution
🛡️ No KYC
Start deploying compute the right way → intercloud.cudos.org/?utm_so…

10
70
1,325
Running compute on centralized clouds?
You're exposing your pipeline to:
👁️ Logging
🛂 Identity profiling
🚫 Throttling
CUDOS Intercloud offers:
👛 Wallet access
🧠 Private #AI execution
🛡️ No KYC
Start deploying compute the right way → intercloud.cudos.org/?utm_so…
1
5
29
2,586
🎙️ We’re LIVE!
Join @metaverski from @CUDOS_ on @RunOnFlux’s X Space right now: “DePIN, DePAI, AI, Decentralized Cloud”
🧠 He will be sharing how CUDOS Intercloud powers permissionless infrastructure for #DePIN, #AI & #Web3.
🎧 Join the X space now: x.com/i/spaces/1DXxyWgeeyEGM
1
2
18
1,003