If a date is filled with empty cells or you don't want an error in calculation of a cell is zero, NULLIF is used.
If cells in an alpha-numeric column is empty or null, ISNULL is used.
Jun 11

NULLIF is not the same as ISNULL, they are just similar
1
3

開発:BASICトランスパイラー。
以下の命令のリファレンスとテストが終了。
ABS
ACS_ACOS
ARGS
ARRAY
ARRAY_ADD
ARRAY_AVG
ARRAY_DIV
ARRAY_FFT
ARRAY_FFT_VIEW
ARRAY_IFFT
ARRAY_MAX
ARRAY_MIN
ARRAY_MOD
ARRAY_MUL
ARRAY_SUB
ARRAY_SUM
ASIN_ASIN
ATAN2
ATN_ATAN
BIN
BIT
BREAK
BYTE
CBRT
CEIL
CHR_CHR$
CLS
CONTINUE
COS
DATA
DATATEXT
DATE
DEC
DEG
DIM
DIRS
DRAW
DRAW_LINE
DRAW_PEN
DRAW_PENSET
END
EOF
EXP
FILES
FILL
FILTER
FILTER_BLUR
FILTER_EMBOSS
FILTER_HALFTONE
FILTER_LUMINANCE
FILTER_MOSAIC
FILTER_SHARP
FILTER_THRESHOLD
FILTER_TONE
FIX
FLOOR
FOR-NEXT
FORMAT
FRAC
GOSUB
GOSUBX
GOTO
GROUP$
HEIGHT
HEX
IF...THEN
INPUT
INT
ISINF
ISNULL
KEY
LABEL
LEFT_LEFT$
LEN
LET
LOADIMAGE
LOG
LOG10
MID_MID$
OPTION_BASE
OPTION_BINARY_ARRAY_TRIM
OPTION_DELIMITER
OPTION_ENDIAN
OPTION_INPUT_PROMPT
OPTION_PI
OPTION_PRINT_DELIMITER
OPTION_PRINT_NULL
OPTION_READBIN_MAXSIZE
OPTION_READBIN_MAXSIZE_ERROR
OPTION_READDATA_MISSING
PARAM
PGET
PI
POW
PRINT
PRINT$
PRINTBIN
PSET
RAD
READ
READBIN
READDATA
READEXCELDATA
READHTML
READHTMLTEXT
READLINE
READTEXT
REM
REPEAT-UNTIL
RESTORE
RETURN
RETURNX
RIGHT_RIGHT$
RND
ROUND
SAVEIMAGE
SAVEPDF
SAVESVG
SAVEWORD
SCREEN
SGN_SIGN
SIN
SIZE
SPC
SQR
SRAND_RANDOMIZE
STR
SWAP
TAN
TIMER
TRUNC
TYPE
VAL
VALS
WHILE-WEND
WIDTH
2
127
S THE ANALYST retweeted

Jun 11
NULLIF is not the same as ISNULL, they are just similar
Jun 10
Not all empty cells are nulls
1
1
12

Jun 12
The new "big" thing I tried in this session was keyed findings. Everything that gets written to an md file gets an ID before it gets written up. B-001 for a branch in the code, R-001 for a rule we need to lock in and test, T-001 for a table in the db, etc.
Now every fact has an address. The agent reasons way better when its own findings are keyed, it can point to R-014 and check it against everything else instead of juggling "that ISNULL(...) rule on the PD branch". The keys are there for me too when I review, but mostly they keep the agent grounded.
This was the biggest difference vs previous attempts of something of this scale, I think.
1
1
1
30

Jun 10
Every Monday morning, before any stakeholder sees a number, I run the same four checks.
Not because I distrust my pipeline. Because I have been burned enough times to know trust is not a substitute for verification.
The pattern in Python:
import pandas as pd
df = pd.read_csv('weekly_report.csv')
# 1. Row count sanity check
print(f"Rows this week: {len(df)}")
# 2. Nulls on key columns
print(df[['revenue','customer_id','date']].isnull().sum())
# 3. Date range check
print(df['date'].min(), 'to', df['date'].max())
# 4. Revenue outlier flag
outliers = df[df['revenue'] > df['revenue'].quantile(0.99)]
if len(outliers) > 0:
print(f"{len(outliers)} outlier rows detected")
Two minutes. Has caught broken pipelines, missing date ranges, and one load error heading into a board pack.
Senior analysts trusted by leadership are the ones who catch their own before anyone else does.
What does your pre-send data check look like?
1
1
7
216

وجود القيم الفارغة قد يسبب أخطاء في الكود أو يؤدي إلى نتائج وتوقعات غير دقيقة للنماذج. لمعرفة حجم المشكلة في مكتبة Pandas، نستخدم دالة ()isnull().sum لتحديد عدد القيم المفقودة في كل عمود والبدء في وضع استراتيجية للتعامل معها.
#Python #DataScience
1
64

セールスフォースの数式項目で「ある項目が空欄の場合はAを、空欄ではない場合はBを返す」という式を作る場合、= null ではなく ISBLANK()かISNULL()を使う必要があります。二つの違いはこちら。
note.com/effinous/n/n136b3f4…
#Salesforce
1
184

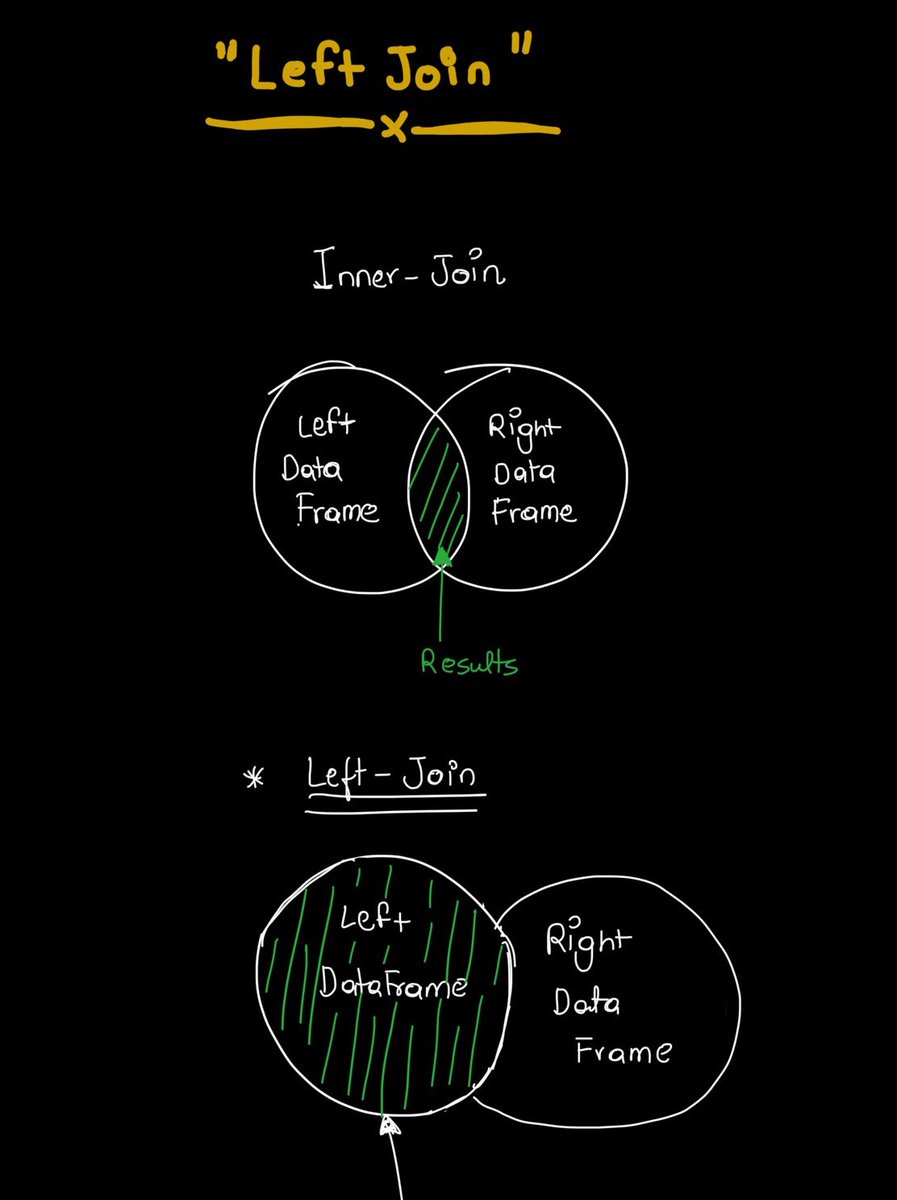
Day 5 of #60DaysOfLearning2026
DataFrame Merging & Joins
Merged movies dataset with taglines using pd.merge()
Learned different joins: Left, Right, Inner & Outer
Handled missing values using .isnull().sum()
@lftechnology #LSPPDay5 #60DaysOfLearning2026 #LearningWithLeapfrog



2
32
開発:BASICトランスパイラー。今夜の段階で説明かけたのは以下のもの。現在CodexがDEC()の仕様変更に対応してるところ。配達時間なので、ここまで。
ABS,ARGS,CEIL,CONTINUE,COS,END,FLOOR,FOR-NEXT,GOSUB,GOTO,INPUT,INT,ISNULL,LABEL,LEFT,LEN,LET,OPTION_BASE,OPTION_PI,PI,PRINT$,PRINTBIN,REM,REPEAT-UNTIL,RIGHT,ROUND,SGN_SIGN,SIN,SIZE,SQR,SRAND_RANDOMIZE,STR,SWAP,TAN,TIMER,TRUNC,TYPE,VAL,VALS,WHILE-WEND

3
197

Jun 2
5 Pandas Series functions every beginner should know:
- isnull() — Identifies missing (NaN) values in a dataset.
- fillna() — Replaces missing values with a specified value.
- dropna() — Removes missing values from the Series.
- astype() — Converts data from one data type to another.
- apply() — Applies a custom function to every element in the Series.
These are some of the most frequently used Pandas functions and form the foundation of working with real-world data.
1
5
244
May 26
Pandas is one of the most important Python libraries in Data Science, ML and Data Engineering.
It helps you:
• Read CSV/Excel files
• Clean messy data
• Handle missing values
• Filter and sort data
• Analyze large datasets
• Prepare data for ML models
Core structures:
• Series → 1D data
• DataFrame → table-like 2D data
Some important beginner functions in Pandas:
• read_csv() → read CSV files
• head() → first 5 rows
• info() → dataset summary
• describe() → statistics
• shape → rows & columns
• columns → column names
• isnull() → check missing values
• dropna() / fillna() → handle null values
• loc[] / iloc[] → select rows & columns
• sort_values() → sorting
• groupby() → data analysis
• merge() → combine datasets
• value_counts() → frequency count
• to_csv() → save files
1
3
21
685

May 20
WHERE句にISNULLを持ってきているせいで、いらん完全NULLレコードが取得されてしまっているのでは……?
いやでも昨日まではちゃんと動いてたんだよな~~~~~
何が悪い
2
60

May 18
機械学習を始める前にやること、知ってる?
モデルを作る前にまずこれ👇
① データの形を確認(shape)
② 欠損値を確認(isnull)
③ 分布を確認(describe/hist)
モデルより前処理が8割。
ここをサボると後で必ず詰む🔥
#機械学習 #Python #駆け出しエンジニアと繋がりたい
2
69

May 17
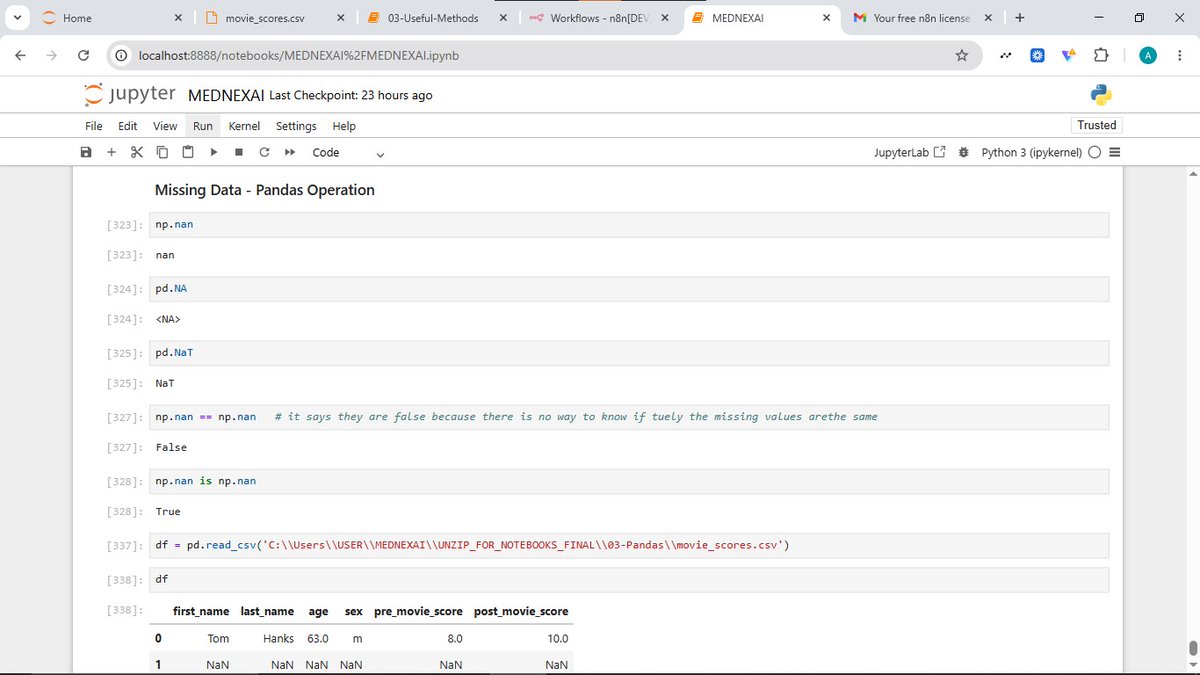
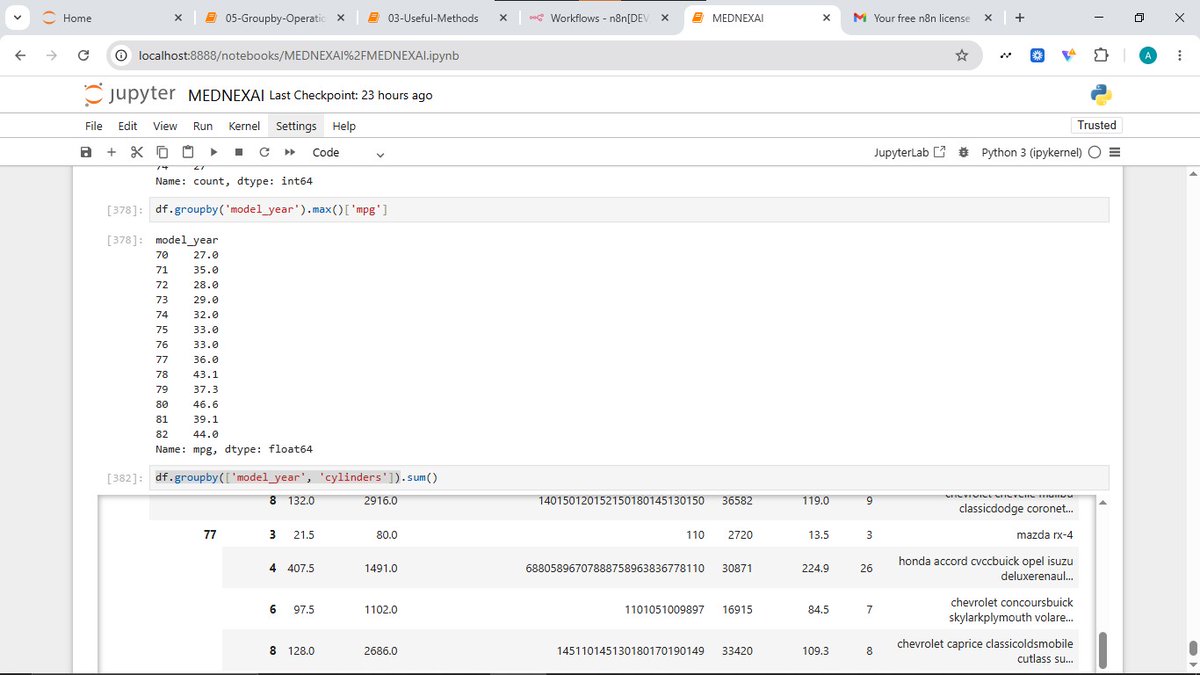
Day 7
Today,
I learned:
• What to do with missing data ( keep it, remove it, or fill it)
• How to use .isnull() and .notnull()
• Using groupby() to categorize data
• That groupby() is often used with aggregation functions like .mean()
#LearnInPublic
May 16

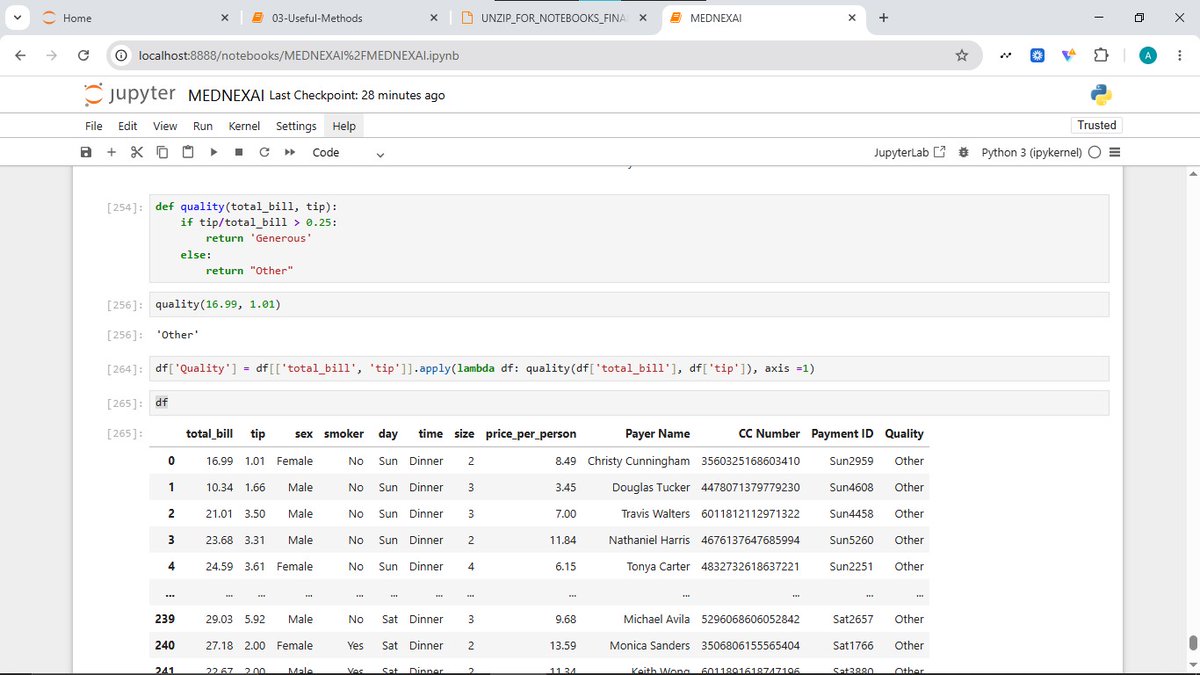
Day 6
Today, I learned:
• Using .apply() on multiple columns
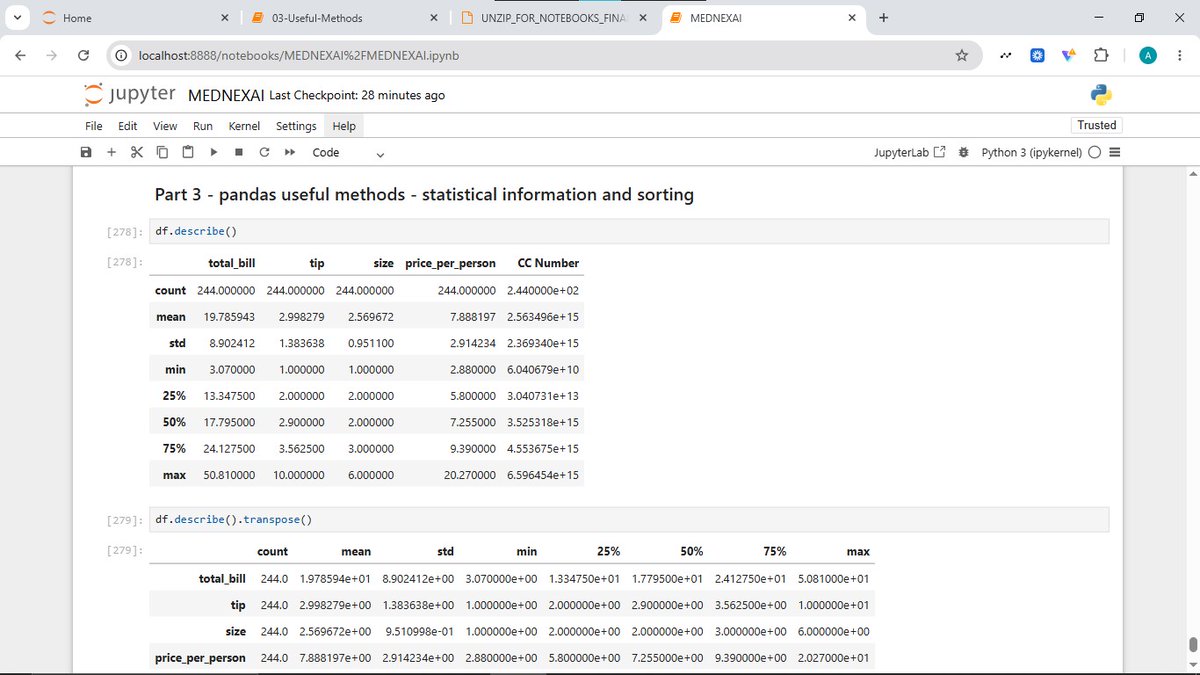
• Using lambda functions in a DataFrame
• Getting statistical information with .describe()
• Sorting data using .sort_values()
• Checking and dropping duplicates in Pandas
#AI #DataScience #LearnInPublic
1
5
74

There is a reason why ISNULL is in SQL.
NULL values doesn't always mean something is wrong or the data needs cleaning.
Experience will eventually teach you that.
4
98

【5/13 本日の学習】
所感:新しいメソッドを学ぶことができたよかった。
メソッドを利用したその裏でなにが起きているかも合わせて理解することが重要実感
≪ 学習内容 ≫
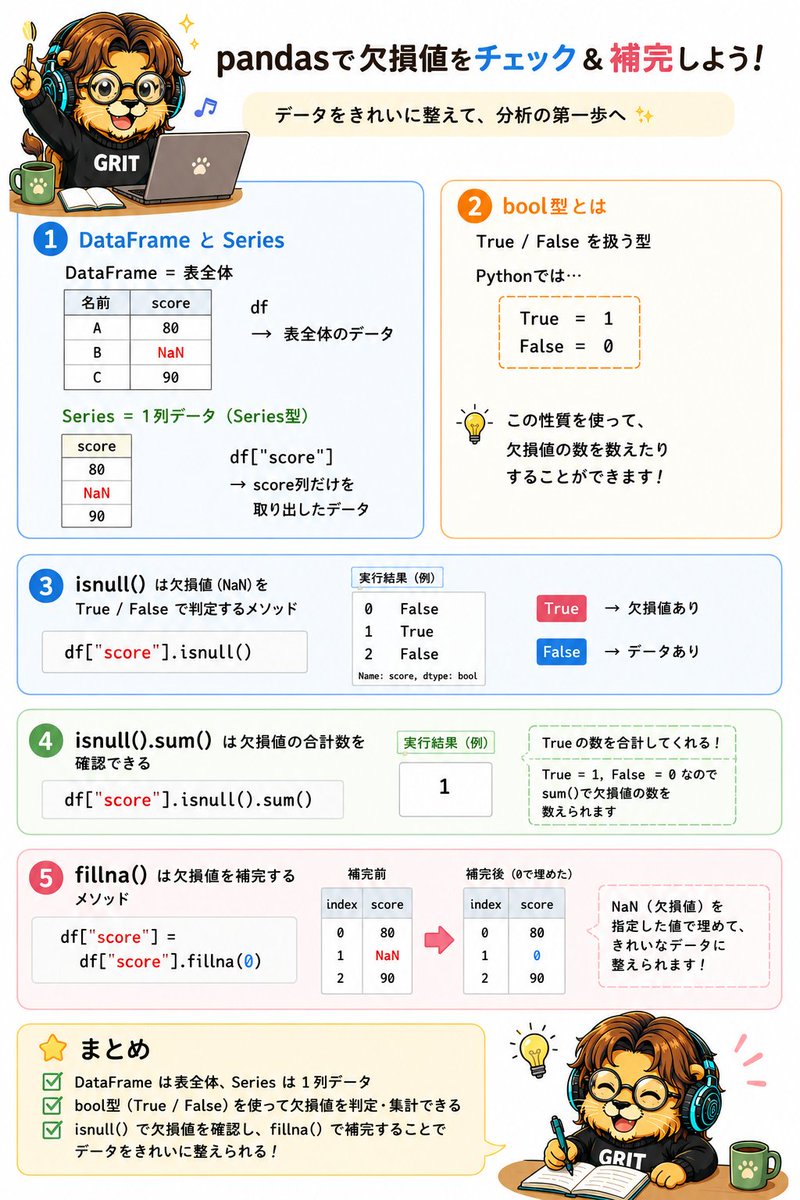
① DataFrame
→ 表全体のデータを扱う
② Series
→ DataFrame の1列データを扱う
③ bool型
→ True / False を扱う型
④ isnull()
df["score"].isnull()
→ 欠損値(NaN)を True / False で判定するメソッド
NaN → True
値あり → False
⑤ isnull().sum()
df["score"].isnull().sum()
→ 欠損値の合計数を確認できる
True = 1
False = 0
として計算されるため、
True の数 = 欠損値の数になる
⑥ fillna()
df["score"] = df["score"].fillna(0)
→ 欠損値(NaN)を指定した値で補完するメソッド
例:
NaN → 0
に置き換えている。
4
51

📚 DS独学 Day 2
・欠損値の確認(isnull・fillna)
・データ型の変換(astype)
・円グラフの作成(matplotlib)
・糖尿病データセットで実践
欠損値の確認と対処、データ分析っぽくて嬉しい。
学習時間:1.5時間 / 累計:2.5時間
#Python #データサイエンス #100DaysOfCode
1
4
67


May 9
Poor teacher just needed an ISNULL handler, and it could be whatever number she wanted
1
3
637