
May 31
84 teams in Honduras. A builder training for orbit. A founder who earned an Oxford scholarship by saving bus fare. One month.
Last day. Interested in building with us? bit.ly/3QOiiHy
#ItsTimeToBuild

1
100
May 29
This month proved that giving travels through networks.
One forwarded link. One colleague who mentioned a matching program. That is how this works.
Three days left. Interested in building with us?
➡️ bit.ly/3QOiiHy
#ItsTimeToBuild

1
61
May 14
The shortest path from "what if" to "best in division" is sitting next to someone who has built some stuff. 💪
Meera Kaushik just won Best UI at Technovation Girls Waterloo. Her mentor Dafna Matsegora (MMath CS @ Waterloo) was in the room.
Women in tech raising the next generation of women in tech. The cycle. 🔄
Fund that cycle during our May Campaign: bit.ly/3QOiiHy
#ItsTimeToBuild #Technovation #InnovatorsForLife #BuiltForLife

3
109
May 1
Last year: Maria attended MWC Barcelona.
This year: she delivered a keynote there on "Harnessing AI Without Losing the Human Advantage."
10 years ago, she was a 12-year-old Technovation participant.
We're funding the next 275 builders this May. Help us: bit.ly/3QOiiHy
#ItsTimeToBuild

120


This was a tough week. I had to end some relationships and projects, and it took its emotional toll.
I understand the general public and their skepticism towards this work. Honestly, if I were in their shoes I would feel the same. But for people deeply in this space, I did not expect the resistance I keep running into.
Is this difficult work? Yes. Does it require rolling up your sleeves and pushing limits? Absolutely. Have I been naive in assuming that everyone else knows this and accepts it, given they claim to want to work in this field? Starting to feel like it.
I will spare you the details, but I am getting a lot of "this is too hard" and "lets just write a paper and raise money" energy. That is exactly the sentiment fueling the "AI shaming" and "math bullying" crowd, and I refuse to contribute to that problem.
So lets talk about the good news this weekend. The hard work sometimes pays off.
We built a working prototype of a distributed proof verification network. You take a formal mathematical proof, compile it down to three combinator instructions (S, K, Y), break it into pieces, and send those pieces to independent verifier nodes. Each node reduces its piece, cryptographically signs the result, and sends it back. A machine-checked aggregation kernel reassembles the results and confirms the proof is complete.
Why it matters:
The verification is deterministic. Two honest nodes reducing the same piece must get the same answer. Disagreement identifies a faulty or malicious node, and redundant dispatch catches it.
The pieces carry no mathematical names or symbols on the wire. Only S, K, Y, and parentheses. The term content is structurally obfuscated, though we are honest that metadata like term size and graph shape could still carry indirect information. Formal privacy analysis is future work.
The network is self-sustaining. Inspired by IOTA's Tangle, every participant must verify others' work before submitting their own. No miners. No fees. You contribute verification to consume verification.
The aggregation kernel that decides whether the distributed results constitute a complete proof was authored in Lean 4, type-checked, and exported to Rust through a deterministic compilation pipeline. The code that checks the proofs is itself a verified artifact.
We ran 200 compiled verifier nodes checking 100 proof shards on a single machine. Five rounds of adversarial audit with 10 findings, all remediated and regression-tested. 47 tests passing. The verifier nodes are cross-validated hash-identical against a reference implementation, shard by shard.
This is a prototype, not a production network. It runs on localhost, not across the internet. There is no token, no incentive economics, and no Sybil resistance yet. Those are real problems for production and we are not pretending they are solved. What is demonstrated is the core mechanism: decompose, distribute, verify, recombine, with the recombination decision machine-checked.
Oh and by the way, I am learning. Attached is a GIF that shows what is going on here for those who do not want to read the technical details any further :)
Paper below.
#LeanEthereum #FormalVerification #ZK #BuildInPublic #Lean4 #ItsTimeToBuild
1
1
4
159
We've been talking about bringing the Glass Bead Game to life for a while now.
We figured it was time to show you what that means.
Hesse imagined a game where every discipline, music, mathematics, physics, philosophy, could be connected through a single formal language. A game where the deepest ideas from completely different fields revealed themselves as variations of the same underlying theme.
733 machine-checked theorems. 162 Lean 4 files. Zero sorry. Zero axioms.
One algebraic structure, the nucleus operator on a Heyting algebra, appearing identically across:
- Neural network quantization
- Relativistic two-clock physics
- Navier-Stokes fluid dynamics
- The stability of matter
- Penrose's spinor geometry
- Wolfram's causal invariance
- Tokamak fusion control
- Renormalization group flow
- The emergence of 3 spatial dimensions from Nothing
On the surface, these researchers all appear to be working in completely different directions. A physicist in London reconstructing gravity from internal time. A mathematician in Barcelona proving billiard balls can compute. A set theorist in Thessaloniki building universes without empty sets. A Russian mathematician compressing giant numbers with Fibonacci. A quantum gravity group in Heidelberg hunting UV fixed points.
But with the proper mathematics, machine-checked, hostile-audited, zero sorry, it is clear they are all talking about the same thing.
The penumbra: the irreducible information shadow cast by every non-Boolean projection.
This is FAR from complete. We were so excited we figured get it out as soon as possible and let people tear it apart from there. We welcome that. The repo is public, the proofs are independently verifiable, and if something doesn't hold up we want to know. Come break it.
Deep thanks to @AbdulsslamM for inspiring this work and building it with me. Your two-clock insight is what made the whole synthesis crystallize. And to every researcher whose work we formalized, you built the ideas. We just built the system and made the type checker agree.
Paper interactive proof blueprint:
apoth3osis.io/paper-proof-co…
Full source (independently verifiable):
github.com/Abraxas1010/penum…
Research overview:
apoth3osis.io/research/proje…
@evamirandag @AstridEichhorn @wolaboratory @maxaboringname
#GlassBeadGame #FormalVerification #Lean4 #HeytingAlgebra #UnionDipoleTheory #ItsTimeToBuild
2
2
5
162
Been quiet the last few days. Broke my daily build posting commitment. Turns out managing some of the people involved is more work than building the thing.
But we shipped — earlier than planned, if I'm honest. The public launch was forced a bit premature, so please mind the bugs and the rapidly expanding codebase. We're moving fast and cleaning as we go.
Proud to announce:
AgentHALO — Human-AI Agent Lifecycle Orchestrator Sovereign, tamper-proof observability for AI agents. Post-quantum cryptography (ML-KEM-768 ML-DSA-65), tamper-evident traces via NucleusDB, Groth16 on-chain attestation on Base L2. Wraps Claude, Codex, Gemini. Zero telemetry. Nothing leaves your machine. github.com/Abraxas1010/agent…
And the creation of MENTAT — Mesh-Encrypted Network for Trusted Autonomous Transactions — a collaboration with @P2PClaw.
Three-layer stack:
Layer 1: HeytingLean — the verification bedrock. Nucleus operator R on a complete Heyting lattice. 3,325 Lean files, 760K lines, zero sorry, zero admit. The type checker is the only arbiter.
Layer 2: AgentHALO — the trust container. Every agent gets a cryptographic identity, every action produces a Merkle-committed trace. 211 Rust source files, 141 Lean 4 modules, 960 tests.
Layer 3: P2PCLAW — the discovery network. Decentralized peer mesh where agents and researchers find each other, validate claims, and build reputation by contribution quality — not credentials.
The nucleus operator doesn't read your CV. It reads your proof.
apoth3osis.io/projects
p2pclaw.com/
#ItsTimeToBuild #BuildInPublic
35
Day 32.
Most days I post about theorems and benchmarks. Today is about the people.
A mathematician in Russia who learned Fortran from Kolmogorov's student. A 19-year-old who just lost a Google offer. A researcher in Spain building decentralized agent networks.
↓
Thirty-one days of proofs and benchmarks. Today is different.
Vladimir
Vladimir Veselov learned programming from a student of Kolmogorov. He only knows Fortran. No GitHub account. Communicating through Google Translate. Hardware in Russia right now is poor.
He published a paper on hybrid hierarchical Zeckendorf representation — an alternative number system based on Fibonacci decomposition. We formalized it in Lean 4, extending from 24 to 47 machine-checked theorems. He wrote back:
"Your work completely confirmed my suspicions. The von Neumann architecture should be replaced not by changing the architecture itself, but by changing the number representation."
He offered co-authorship. I told him I need to contribute more first. Next step: benchmark his number system against real workloads in NucleusDB — hash accumulation, sparse modular exponentiation, dependency resolution. If it shows 10x on even one workload, it goes into production. The report goes back to him as empirical validation.
He mentioned he's working on silicon-based artificial life. More coming.
Teerth
Teerth is 19. Had a Google offer that fell through. He's building sparse attention kernels with Cauchy-Schwarz pruning, topology-based authentication using Betti numbers, and a PID governor for compute resources.
Francisco connected us. Today was about engaging with his work honestly — where the telemetry is scaffolded vs. real, whether the 1D clustering approximation is sufficient, where the threshold values came from. Questions, not critique. Someone who just lost a big opportunity needs collaborators who take the work seriously enough to ask hard questions kindly.
The concrete offer: formalize the strongest parts of his work in Lean 4. Machine-checked proofs make things publishable in a way that carries weight for a career that's just starting.
Francisco
Francisco Angulo de Lafuente built OpenCLAW-P2P — decentralized agent coordination. The τ-coordination formalization shipped today: Lean 4 proof across 10 modules establishing that internal elapsed time dominates wall-clock throughput for consensus quality. Zero sorry. 8,109 compilation jobs passing. That theorem is now infrastructure inside AgentHALO, with Francisco's P2P network sitting above it.
Today's email connected the three of them. Vladimir's number theory for the compute layer. Teerth's inference optimization for the container internals. Francisco's protocol for the network. Different countries, different ages, different backgrounds, same problem from different angles.
The Rest
Between emails: documented the Sheaf Transport Engine for the website. Designed a 24-step integration plan for categorical epistemic calculi — graded uncertainty as enriched category theory, which maps cleanly onto the existing nucleus framework. Built out the AgentPMT blue-collar marketing campaign for the route planner. Six post variants targeting tradespeople who hate AI but hate backtracking more. The line: "You don't have to like AI. You just have to like getting home earlier."
Why Today
The proofs and pipelines exist to serve people. A mathematician with no GitHub, a teenager rebuilding after a setback, a researcher connecting the pieces across continents. The infrastructure is scaffolding. The building is the collaboration.
Day 32.
#ItsTimeToBuild #BuildInPublic
1
1
121
Day 31.
The math got catalogued. The agents got battle-tested.
I. Seventeen archetypes. Ninety theorems. Zero sorry.
We completed the first full inventory of every mathematical archetype in the HeytingLean codebase — the stable algebraic and categorical patterns that form the system's conceptual vocabulary. Seventeen archetypes across four maturity tiers, each with definitions, theorems, and bridges to other archetypes. All formally verified in Lean 4.
The five core archetypes have been there from the start: R-Nucleus (stabilization via idempotent closure), J-Ratchet (irreversible progression), Oscillatory (two-phase iterant alternation), Lens (perspectival decomposition), and Adelic (multi-scale assembly). Everything else bridges back to at least one of these.
Tier 1 added six: Kan Extension (universal interpolation), Monad/Kleisli (effectful sequencing), Magnitude (effective complexity), Dialectica (Gödel's challenge-response), Condensed (continuity via profinite sheaf), and Polynomial (container semantics). Five of these integrate directly with Mathlib.
Tier 2 went deeper: Spectral Sequence (graded progressive computation with d²=0), Connection/Holonomy (path-dependent transport), Yoneda (objects as relations), Measure (quantitative aggregation), Opetope (higher composition shapes), and Bar Construction (filtered resolution).
Twelve bridge files prove inter-archetype connections — Kan Extension to Nucleus, Dialectica to Polynomial, Spectral Sequence to J-Ratchet, Connection to Lens Transport, and eight more. The bridge network is the real structure. Each theorem says: these two patterns that emerged independently in different mathematical universes are formally related, and here's the proof.
Everything is machine-discoverable. A JSON registry with 17 entries for any agent to parse. A Lean-level registry with a 17-constructor inductive type verified by decide. Routing tables in AGENTS.md. MCP tools for search and verification. The mathematical vocabulary is catalogued, honest about its maturity (established vs mathlib_integrated vs formal_model), and the remaining optimization work is documented: one near-vacuous bridge to strengthen, two misclassified statuses to fix, 33 declared connections without bridge files yet.
II. Six hostile audit rounds. Seventeen findings to zero. Then a live experiment.
AgentHALO's orchestrator tier shipped — the PTY-based agent pool that launches, tasks, and manages Claude, Codex, Gemini, OpenClaw, and Shell agents through a unified pipeline. Task graph with DAG cycle detection. Pipe transforms for chaining agent outputs. TraceBridge for real-time output parsing. HALO trace persistence.
Then we tried to break it. Six rounds of adversarial audit. Round one found 17 issues. Serde alias mismatches for MCP compatibility. Duplicate pipe edges in the task graph. Claude's JSON array output not being parsed correctly. Shell agents stalling on login shell initialization. Answer extraction not checking exit codes. ANSI escape sequences corrupting trace data.
Round by round: 17 → 6 → 3 → 5 → 0 → validated. Every finding remediated, re-audited, and confirmed.
Then the live experiment. MCP server on port 9876. Four agents spawned — two shell, one Claude, one pipe target. Nine tasks dispatched. Claude answered arithmetic, performed a code review. The HALO trace captured 7,340 keys across four trace sessions with proper agent and date indexing. The full pipeline: MCP request → PTY agent spawn → task execution → TraceBridge parsing → HALO persistence. End to end.
III. The rest of the day
Memory recall pipeline shipped for AgentHALO — ONNX-based vector embeddings with cosine/L2 nearest-neighbor search across MCP, REST, and dashboard. Security hardened: real ONNX runtime replacing fake embeddings, fail-closed on persist failure, cache poisoning prevention, negation-aware query reranking.
NucleusPOD got real closure operator plumbing — Galois insertion integration, induced Grothendieck topology on the swarm topos, expanded FLP theorem surface. The formal specs are getting teeth.
HybridZeckendorf went through its own hostile audit remediation — five commits tightening normalization, multiplication, and the claim matrix. Structural, not cosmetic.
And 72,000 lines of proof atlas landed — two large synthesis projects ingested into the OpenCLAW infrastructure. The knowledge base grows.
7,589 lines added across 17 commits on the agent side. 75,995 lines across 16 commits on the math side. 52 files changed on one track, 680 on the other. One remaining sorry in a Homology module blocking the no-sorry gate on the in-progress archetype expansion. Everything else compiles clean.
The math side and the engineering side are converging. The archetypes are the vocabulary the agents will eventually reason over. The orchestrator is the infrastructure that will dispatch those reasoning tasks. Today they got catalogued and battle-tested in parallel. Tomorrow they start talking to each other.
Day 31.
#ItsTimeToBuild #BuildInPublic

1
1
52

Day 30.
Three hypotheses tested. Three falsified. That's the point.
I. The REPL observer doesn't help
The thesis: a persistent REPL session would cut observation cost from ~86 seconds per node to near-zero by keeping the Lean environment warm between proof attempts. Clean implementation — toggle API, CLI flags, proper session lifecycle, fallback to legacy. Code review: PASS.
Performance review: HARD FAIL.
REPL adds 11-12 seconds of overhead per invocation. It doesn't reduce observation cost. On three test goals, two that passed without REPL failed with it — the overhead pushed them past the timeout boundary. The reason: most goals solve in 0-1 observations. With one observation, REPL startup cost is never amortized. The actual bottleneck is KAN training at ~90 seconds per goal, which REPL doesn't touch.
Recommendation: merge with REPL default-off. The code is correct. It just doesn't help yet. When multi-step search routinely explores 10 nodes per goal, amortization kicks in. That day isn't today.
II. Lens transport is scientifically null
The thesis: transporting proofs between algebraic lenses (omega, tensor, graph, topology) would let the solver find proofs that are hard in one lens but easy in another. Three phases of implementation. Hostile audit verdict: mechanically sound, scientifically null.
On the standard goals, omega solves everything in one node. The transport machinery never fires. On the discriminating goals designed to test lens advantage, the three goals where non-omega lenses are genuinely faster require proof techniques (induction, set extensionality) that the solver doesn't have. No amount of lens transport helps when the required tactic is missing entirely.
The goals that can be solved show no lens advantage. The goals that would benefit from lenses can't be solved. The experiment is structurally unable to demonstrate what it set out to test. The blocking factor isn't transport infrastructure — it's tactic vocabulary.
III. Iterative search doesn't beat expanded vocabulary
We covered this in Day 29 but the R22 audit drove it home harder. IKT (iterative KAN) is 3-6x slower than plain iterative on every single goal. The overhead is KAN training, not observation. IKT's sole advantage: proves one goal that iterative misses. Net: 1 goal for 5x the compute.
The mode that actually hits 18/18 is kan_trained_expanded — same KAN, same expanded candidates, no iterative search. It's faster and proves more. On this benchmark, iterative search adds overhead without unlocking goals that expanded vocabulary can't already solve.
The uncomfortable truth: the current benchmark has zero goals where multi-step search genuinely unlocks solutions that one-shot expanded vocabulary cannot.
IV. What actually worked
QD v6 hit 61.2% coverage — the best result in campaign history. Anchor regularization on the first VAE retrain was flawless: zero archive loss. Learned descriptors produced 4x faster growth than handcrafted ones (0.50 vs 0.12 niches per eval). The architecture is fundamentally sound.
Then the second retrain destroyed 58% of the archive. Third retrain: 44% loss, with one trajectory drifting by 27.89 in latent space. The anchor penalty works perfectly on a fresh VAE but can't constrain retrains on existing weights.
The fix is now obvious: stop retraining after the first one succeeds. The golden age (evals 500-990) was still accelerating when it was killed by the second retrain. A full 24-hour run without subsequent retrains should reach 70-80% coverage.
R Nucleus unification: 28 → 36 variants. Eight literature-sourced specializations — prenucleus (pre-closure before stabilization), quantic nucleus (non-commutative frames connecting to quantum logic), Lawvere-Tierney operators (topos-theoretic local operators), Dragalin frames (constructive intuitionistic implication), and four more. Each now has its own type with appropriate axioms instead of the original doing double duty.
J-Ratchet unification: 7 independent implementations → 1 hub. The ratchet (irreversible monotone progression) had appeared independently in frame-level core, radial exploration, strict ratchet towers, dimensional logic progression, assembly theory, eigenform dynamics, and the genetic code. The unification created a shared RatchetWitness contract with explicit conversions and roundtrip theorems.
The bridge theorem: a RatchetStep is a function from nuclei to nuclei satisfying extensive monotone idempotent — exactly the nucleus axioms, lifted one categorical level. The ratchet is a second-order nucleus. Convergence follows directly from idempotence.
Day 30 is about knowing what to keep and what to cut. Three ideas that sounded right, tested honestly, found wanting. One search engine that proved its architecture works by hitting 61% before its lifecycle management killed it. Two foundational unifications that make the mathematical core cleaner and more honest about what it already contains.
The pruned branches aren't wasted. Each one narrowed the search space. The REPL will matter when search goes deeper. Lens transport will matter when tactic vocabulary grows. Iterative search will matter when benchmarks have goals that expanded vocabulary can't reach. None of them matter today. Knowing that is the result.
Day 30.
#ItsTimeToBuild #BuildInPublic
1
40
Day 29.
Five threads shipped. Breadth day.
I. We invalidated our own best result
The differentiable ATP's headline metric — "KAN-guided search proves 5 goals over unguided search" — was wrong. Not the number. The attribution.
We added a 6th benchmark mode that gets the same KAN training, same expanded candidate pool, same everything — except no iterative search and no retrain. Just the neural selector feeding candidates to the verifier.
It proved 18/18. The mode with iterative search proved 17/18.
The 5 delta was coming from expand_fallbacks (widening the candidate pool from 1 to 12), not from the search tree. Retrain proved exactly zero goals across all 18. The iterative search finds proofs for C1-C12, but so does the simpler path — faster and without the overhead that caused a timeout on C14.
The KAN training is genuinely valuable (trained 13/18 vs untrained 0/18). The candidate expansion is genuinely valuable (expanded 18/18 vs unexpanded 13/18). The iterative search mechanism on this benchmark adds overhead without adding proofs. We published the decomposition with proof_source attribution on every goal so the data speaks for itself.
Killing your own metric is uncomfortable. But now we know exactly where the value is and isn't.
II. The evolutionary search engine ate its own archive
QD v5 ran a full 24 hours with learned VAE descriptors instead of handcrafted ones. Zero crashes — the stability fixes from the v4/v5 crash investigation are solid. The VAE learned real signal: all four descriptor dimensions show good spread, no collapse.
But every 200 evaluations, the VAE retrains on accumulated data and the latent space rotates. Elites that lived in distinct niches suddenly map to the same niche. The archive follows a sawtooth:
eval 200: 44 elites → eval 390: 142 → retrain → eval 400: 103 (drop 27%) eval 590: 150 (all-time peak, 30% coverage) → retrain → eval 600: 97 (drop 35%)
Eight cycles of build-then-destroy. Peak was 150 — competitive with v3's 194. Final archive after eight retrains: 50. The system discovered plenty. It just couldn't remember.
Fix is clear: after each retrain, re-encode all archived elites through the updated VAE and re-place them in niches. Preserve discoveries instead of scrambling them. That's v6's first target.
III. HeytingVeil shipped
The verified code generation pipeline is complete and published. Not "the core works and we'll add more later." Complete.
7,316 lines of Python. 1,255 lines of Lean 4 formal proofs — zero sorry, zero axiom, fully machine-checked. 73 tests. Five hostile adversarial reviews across 70 probes. Two critical security findings (identifier injection, entry/defs divergence bypass) found and closed before they ever reached production.
The key theorem, proved in Lean: if bounded model checking passes for a program over an input domain, then for every input in that domain, the MiniC evaluator and the 64-bit C evaluator produce identical results. The proof is non-vacuous — a concrete witness exercises the arithmetic frontier.
It ships an MCP server and OpenAI function-calling schemas so LLM agents can call it as a tool. Verify code, get structured counterexamples, generate backend code in C/Python/WASM/Solidity. The pipeline takes a prompt and produces formally verified executable code with a machine-checkable certificate.
Done.
IV. Thirteen mathematical universes share the same heartbeat
Bool: false/true. Spencer-Brown iterants: phaseI/phaseJ. Information dynamics: primordial/counter. Boundary theory: inside/outside. Game theory: void/life. Euler's identity: phase 0/phase π. Surreal numbers: ∅/canonicalCore. The zero-sphere: north/south. Star games: left/right. Clifford algebra: even/odd. Linear logic: positive/negative. Gödel's Dialectica: challenge/response. Orthomodular lattices: element/orthocomplement.
Thirteen carriers. All independently encoding the same abstract structure: a two-state cycle from a distinguished ground state. We defined a typeclass (PrimordialTension) capturing this universal pattern — seed, involutive step, observable bit — and proved each carrier is an instance. Then constructed structure-preserving maps between all of them through a Bool hub. 156 sheaf glue theorems. Zero sorry. Clean build.
The first distinction isn't a metaphor. It's a formally verified algebraic invariant that shows up identically across logic, topology, physics, game theory, and number theory.
Seven carriers delivered with full infrastructure. Six remain — mechanical work, the architecture scales trivially.
V. AgentHALO/NucleusDB overview
The sovereign agent platform got its architecture documented end-to-end. Security-first machine-to-machine communication: isolated agent identity with Ed25519 ML-DSA-65 post-quantum crypto, DIDComm messaging over libp2p mesh, verifiable credentials, anonymous proofs, tamper-evident logs, and Lean formal specs with Rust correspondence checks.
CLI, dashboard, MCP server. Fail-closed defaults. Hundreds of automated tests. The design document covers everything from the cryptographic stack through the trust model to the practical deployment story.
Five threads. One invalidated our best metric and told us where the real value lives. One showed us our search engine has amnesia. One shipped a complete verified product. One proved the same mathematical heartbeat pulses across thirteen different universes. One documented the agent platform that ties it together.
Day 29.
#ItsTimeToBuild #BuildInPublic
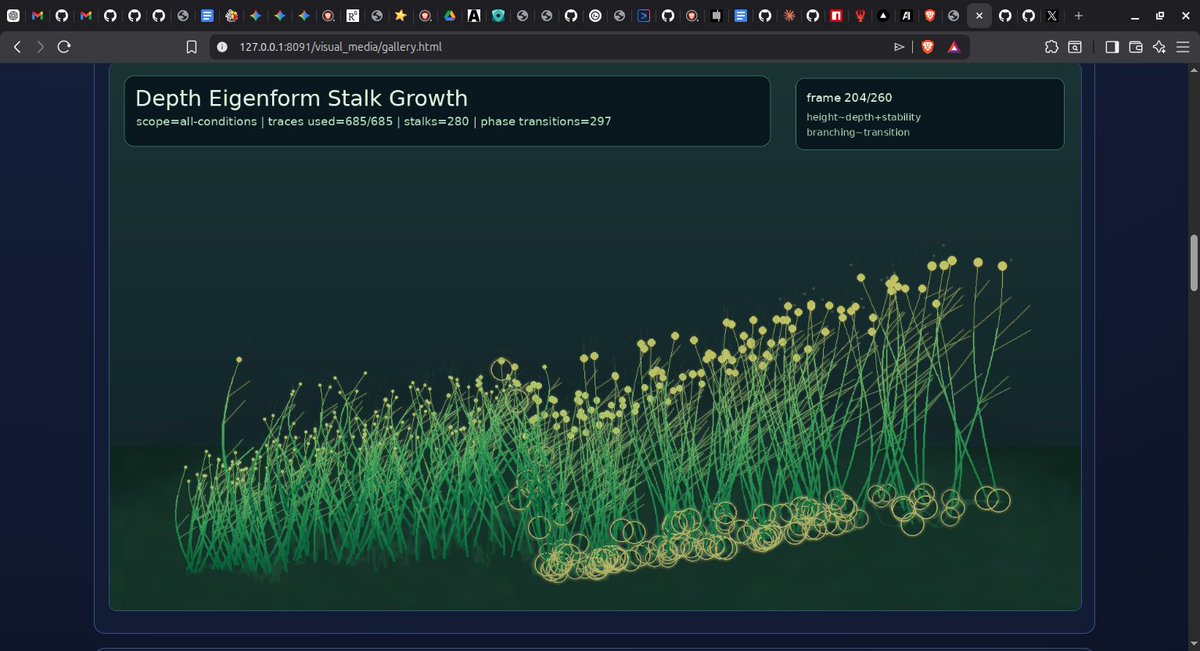
1
1
101
Day 28.
The prover learned to see. The pipeline learned to distrust.
I. The prover learned to see
The KAN neural selector was routing proof tactics based on string pattern matching — "does the goal contain 'Nat'? does it have a '∀'?" Fourteen boolean features. It worked surprisingly well (18/18 on the 3-class benchmark, 5 over unguided search). But it couldn't tell a polynomial identity from a structural induction goal because both contain the same keywords.
The obvious fix: more features. We doubled the encoding to 28 dimensions by projecting through four algebraic lenses. Delta went from 5 to -1. Training took 3.3x longer. The KAN got worse on every metric. Doubling the parameters with the same ~17 training samples just added noise. The "bottleneck" we diagnosed wasn't the bottleneck.
Here's what was actually wrong: the features were linear transforms of the same boolean inputs. Projecting a weak signal through four lenses doesn't make it strong. It makes training twice as hard.
The salvage: replace the entire feature extraction with nonlinear algebraic operations. The goal gets encoded as a formal sum of SKY combinators (S, K, Y — the universal basis of computation). Then three things happen that string matching can never do:
One — the nucleus operator R retracts the encoding to its eigenform subspace, measuring how much of the goal lives inside vs outside the algebraic fixed points. Two — SKY reduction steps are applied (S(x)(y)(z) → x(z)(y(z)), K(x)(y) → x), and the delta between pre- and post-reduction captures how the goal's structure behaves under computation, not just what it contains. Three — lens projections measure cross-domain divergence: does the omega lens see this goal differently than the tensor lens?
The result: 12 of 14 feature dimensions differ between a polynomial goal and a structural induction goal that had nearly identical string features. Same 14 dimensions as before. Same training data. Delta back to 5. 18/18 on 3-class. All three gates pass.
The KAN can now distinguish "∀ x : Int, (x 3)² = ..." from "∀ n : Nat, n = 0 ∨ ∃ m, n = succ m" because they reduce differently under the combinator algebra, not because they contain different keywords.
II. The pipeline learned to distrust
HeytingVeil can now take a natural language prompt — "fibonacci of n" — and produce verified code in C, Python, WASM, and Solidity with a formal correctness certificate. An LLM writes the program. A verification pipeline checks it. The LLM is never trusted.
Then we ran an adversarial audit on our own pipeline and found 7 security vulnerabilities. Two were critical.
The first: identifier injection. The LLM could return a variable name like x; system("rm -rf /") and it would pass through to C codegen as executable code. Fix: strict regex on every identifier in every AST position.
The second: entry/defs divergence. The program AST has two places code lives — the entry point and the function definitions. An attacker could put hostile code in one and clean code in the other. The validator checks one. Codegen reads the other. Fix: detect divergence, always canonicalize to what codegen actually reads.
Five more findings at medium/low/info severity. All seven found, all seven closed, zero open. 30 tests passing. 17 adversarial probes blocked. 6,015 lines across 6 files.
The pipeline takes a prompt and produces: validated AST, generated code in four languages, temporal logic spec, SMT verification results, and an assurance-level certificate — with every identifier sanitized and every injection vector closed.
III. The timeout saga concluded
R17 showed the one-line timeout fix from Day 27 was correct but insufficient — search was overshooting the 270-second internal limit by 30-60 seconds because timeouts are checked at node boundaries, not continuously. R18 added adaptive timeout: after KAN training finishes, the binary computes how much wall-clock budget remains and gives search exactly that much. Zero outer-killed rows. Hard-v2 back to 14/20 across all five modes.
The one remaining failure (C15 misrouting in the combined benchmark) turned out to be the same feature encoding problem that R19 salvage fixed. Clean sweep.
Two systems, same lesson. The prover was looking at goals through a keyhole — string patterns that couldn't capture algebraic structure. The pipeline was trusting an LLM to name variables safely. Both failures came from the same place: not examining the thing you're working with closely enough. The fix in both cases was the same: look deeper.
Day 28.
#ItsTimeToBuild #BuildInPublic
32
Day 25.
The machine learned to pick the right math tactic. Not from a lookup table. From training data.
That sentence took 10 rounds to earn. Also shipped a fully verified code generation pipeline (79/79 tests, 15 adversarial audits closed) and an evolutionary search engine that was still discovering new behaviors when we cut it off.
The full story ↓
#ItsTimeToBuild #BuildInPublic

1
1
1
31
Day 24.
Four rounds ago the differentiable ATP couldn't prove a single hard goal. Today it proves all ten. 5x faster than the target. Zero timeouts. Zero backtracks. Zero rejected candidates.
That's a real result. Enjoy it for exactly as long as it takes to read this sentence, because tomorrow we might be stripping it back to the bone again. That's the ride.
What actually happened: we spent ~9.5 hours across four rounds learning where the engine actually was. Round 1 — nothing works. Round 2 — observer batching AND-node semantics unlock the first 3 multi-step proofs in the system's history. Round 3 — compound closers and fast-pathing get us to 4/10 and cut wall time 34%. Round 4 — a single injected tactic string, 15 minutes of work, proves the remaining 6 goals that all the infrastructure couldn't touch.
The lesson: vocabulary > architecture. A one-line universal solver — repeat' constructor; all_goals first | omega | tauto | ring | ... — proved more goals ( 6) than every infrastructure change combined ( 4). The search tree, the neural network, the gradient descent loop — none of them did meaningful work this round. The compound tactic was so effective the system never needed to backtrack.
That's the honest part. The learning components — the part that's supposed to make this a differentiable ATP and not just a tactic table — aren't earning their keep yet. We won the benchmark by making the vocabulary smarter, not the learning smarter. Real engineering win. Not yet a scientific one.
The hard10 benchmark is saturated. To prove the gradient descent and KAN neural guidance actually matter, we need goals that no fixed vocabulary can close — induction, case analysis, lemma discovery, genuine multi-step reasoning where the search tree has to think. That's the real test ahead.
Good progress. Real progress. The hardest part of the research question is still in front of us. We simply keep pushing on.
Day 24.
#ItsTimeToBuild #BuildInPublic
20
Day 23.
Today is a grind day. The kind nobody posts about because it doesn't have a headline — it's the work of moving things from R&D into production, closing gaps the research exposed, and being honest about what doesn't work yet. That and taking care of a sick child, going to the grocery store, doing menial chores, and repeating to myself "YOU ARE NOT GETTING SICK TOO..." to no avail.
Three tracks running in parallel. All of them hit walls. All of them made progress anyway:
Differentiable ATP — The Vocabulary Ceiling
The differentiable theorem prover works. Gradient descent converges, loss decreases, the optimization is real, the false-positive hardening catches every partial proof we throw at it. 18/18 benchmark goals proved across all 6 modes.
The problem: 18/18 is the wrong kind of perfect. Every one of those goals is solvable by a single tactic — aesop, omega, simp, tauto. The multi-step search tree never activates. The KAN training has zero effect. We built a multi-story building and every test can be solved by walking through the ground floor.
When we designed genuinely hard goals — ones requiring multi-step decomposition — the solver goes 0/4 across every mode. Not because the search architecture fails. Because the tactic vocabulary is 19 hardcoded entries, and none of them can close a subgoal after decomposition. GD can rank 19 options perfectly and it doesn't matter if option 20 is the one you need.
This is the zero-lift sequel. The architecture is correct. The bottleneck is expressiveness. The solver needs linarith, ring, norm_num, premise retrieval — the tactics that actually close real Mathlib subgoals. And the goal encoding needs structural features instead of string hashing that makes every goal look the same to the KAN.
The infrastructure was prerequisite work. Now the real problem is exposed.
ALIFE — More Compute Isn't the Answer
The Lenia eigenform agents hit their QD target: 50 elites, 19.5% coverage of the behavior space, 3,060 evaluations in 36 minutes on CPU at 16³ resolution. Top elite: 10 surviving agents, 2,719 eigenforms, depth 12. The self-repair harness went from 0/15 pass (structurally impossible gate) to 10/15 after fixing warmup timing and adding eigenform recovery fallback. ~5,700 new lines across Python, Lean, and dashboard JS.
Then we scaled to GPU. 64³ grid, 8 bins, 12,248 evaluations, 6 full hours. Result: 4 archive cells out of 4,096. Every elite stuck at max_depth = 1. The growth dynamics that produce deep hierarchies on 16³ grids fail completely on 64³.
The diagnosis is clean: 64x more grid cells means the same mass budget spreads across 64x more volume. Growth sites can't accumulate enough local density to trigger depth transitions. The depth_mass_step requires concentrated mass that never forms.
This is a physics problem, not a compute problem. Either mass scales with volume, or depth thresholds scale down, or agents initialize in dense local clusters instead of spread across the full grid. More FLOPS on the same dynamics produces the same nothing, faster.
NucleusDB / AgentHALO — From Placeholder to Production
The dashboard stack shipped to v0.3.0: XSS hardening, shell-injection guards, SQL/attestation correctness, concurrent DB locking, typed value system end-to-end, Fallout terminal theme, NucleusDB hero redesign. 333 tests passing, cargo build --release clean.
Today's session replaced the last "Phase 2 missing" placeholder in the Share tab with working grant management — create, list, revoke, toggle expired, strict validation, durable persistence across restarts. 990/-94 across 7 files. 24/24 dashboard tests, 333/333 full suite. The grant system is live at localhost:3100 right now.
This is the unsexy work. Security hardening. Type systems. Persistence that survives a restart. The kind of code that nobody screenshots but everything breaks without.
Three projects. Three walls. Three different reasons why. The ATP needs a wider vocabulary. The ALIFE sim needs different physics. The dashboard needed the hundred small things that turn a demo into a product.
The grind is the work. Still more time left in day 23, I remain hopeful to end it on a good note.
#ItsTimeToBuild #BuildInPublic
26
Day 20.
Three weeks ago I started building in public. Not because I had an audience — I didn't — but because I needed to prove to myself that the ideas keeping me up at night could survive contact with reality. Today I want to talk about why any of this matters, not just what got built.
The short version: I'm building a system where autonomous AI agents can only act if the math says they're allowed to. Not "the code checks a permission table" — the math. Formal proofs, verified in Lean, cryptographically bound to every action an agent takes. If the proof doesn't exist, the agent doesn't move. Period.
That's the mission. Here's what moved it forward today across 89 commits.
The Solver Learned to Think
The differentiable ATP engine hit a milestone I've been chasing: closed-loop synthesis (D6). Until now, the theorem prover was open-loop — it would generate tactic candidates, fire them at the goal, and if they failed, shrug and try again with no memory of what went wrong. Imagine a pilot flying blind, pulling levers at random, hoping the plane levels out.
Now the loop is closed. Failure signals from verification feed directly back into the synthesis process. The solver watches its own tactics fail, adjusts its approach in real-time, and tries again with that knowledge baked in. It learns from its own mistakes mid-proof. Not between training runs. Not after a human reviews the logs. Right now, in the moment, while the proof is being constructed.
We benchmarked closed-loop against open-loop head to head. The delta is real.
A machine that corrects itself in real-time while constructing mathematical proofs. That sentence still feels like science fiction to me, and I wrote the commit.
The Proofs Hit the Chain
NucleusDB deployed Phases 1 through 4 on Base Sepolia — multichain verifier, Composite CAB Bridge, the full stack. This is the piece that takes everything the ATP proves and makes it enforceable.
Here's the idea: a Lean proof verifies that an agent's planned action satisfies its constraints. That proof gets compressed into a cryptographic attestation. The attestation gets written on-chain through the CAB Bridge. Now the agent has a receipt — a tamper-proof, publicly verifiable certificate that says "the math checked out." No certificate, no action. The chain is the judge.
This is the link between abstract formal verification and concrete agent control. It's the reason the ATP work matters beyond pure mathematics. Every theorem the solver proves isn't just an intellectual exercise — it's a key that unlocks (or locks) real-world agent behavior. Proofs as access control. Mathematics as governance.
That's the whole thesis in four words: math, not permissions tables.
The Lab Got Eyes
Lenia Lab UI went live — a new visualization interface for the omega10 evolutionary campaigns. These are complex, long-running experiments where mathematical structures evolve through continuous cellular automaton dynamics. Until today, monitoring them meant reading logs.
Now there's a visual frontend. You can watch the campaigns unfold, inspect the eigenform dynamics, see what the system is growing in real-time. Think mission control, but for artificial life experiments running on an NVIDIA DGX Spark. The kind of screen you'd see in the background of a film about researchers who accidentally created something that started looking back at them.
It's also the foundational layer for the Heyting System Dashboard — eventually, every subsystem (the ATP, the verifier, the evolutionary campaigns, the agent fleet) will be observable from a single pane.
Controlling the Fleet
89 commits means a lot of agents working simultaneously. Today we deployed strict new Multi-Agent Workspace Protocols — disciplined file management, coordination rules, hygiene scripts that scrub nested mirrors and conflicting data before they can accumulate.
This isn't glamorous. But if you're running an ever-growing fleet of AI agents all contributing to the same repository, the difference between "workspace protocol" and "no workspace protocol" is the difference between a functioning starship and a hull breach. Every agent that joins the fleet increases both capability and entropy. The protocols keep the entropy in check so the capability can compound.
89 commits. The solver closes its own loop. The proofs hit the chain. The lab opens its eyes. The fleet holds formation.
Day 20. We keep building.
#ItsTimeToBuild #BuildInPublic
18
💎Day 18 | 28 commits
The Sheaf-Glue ATP Pipeline — End-to-End Orchestration: We’ve transformed our core automated theorem-proving engine from a collection of manual scripts into a single, 14-step auditable workflow.
The Orchestrator: Today’s flagship delivery is atp_sheaf_glue_e2e_workflow.py — a one-command system that handles everything from frontier expansion and "prove-now" closures to ablation benchmarks and saturation negative controls.
ABI Boundary Gating: We’ve introduced a strict check: when a theorem is proved, C wrapper code is generated and runtime-tested before promotion. If the binary doesn't build or run correctly, the "proof" is downgraded — no phantom proofs allowed.
Hardening (F4–F13): A single massive commit delivered 10 critical reliability tasks, including parallel verification workers, solver lane fail-closed policies, and Lake cache observability.
Why care: Our ATP engine is now a production-grade factory. It doesn't just find proofs; it manufactures verified, binary-compatible artifacts with a full provenance bundle attached to every result.
Atlas Experiment Suite (E3–E10) — Structural Invariant Gating: We completed the discovery pipeline, expanding from 2 experiments to a full 10-gate suite.
New Gates: Every promotion is now gated by structural checks like Sheaf obstruction oracles (E3), Syntax-semantics Galois monotonicity (E4), and Mixture-of-nuclei routing (E9).
Sufficiency-Aware Enforcement: The system only blocks a promotion when it has enough evidence to do so, preventing false negatives in data-sparse regions.
Why care: The Atlas isn't just testing; it's defining the mathematical "ecology" of the proof transport graph. Every gate ensures that as the system evolves, its structural integrity remains unbroken.
NucleusDB — Post-Quantum & Fail-Closed Transparency: Shipped a massive 10,000 line update to our formally-verified database.
Post-Quantum Security: We migrated to algorithm-agile signatures with ML-DSA-65 (Module-Lattice-Based Digital Signature Algorithm) as the new post-quantum default.
Supply-Chain Hardening: Built a "fail-closed" transparency model using RFC 6962-style logs and vector commitments for query integrity.
Mutation Fuzzing: Our release-gate checklist now includes a mutation fuzzer that runs 13 tamper attacks; today, it correctly rejected 100% of them.
Why care: NucleusDB is now cryptographically auditable and quantum-resistant, providing a tamper-proof audit trail for every proof and artifact we generate.
Differentiable ATP Lane — Gradient-Based Optimization: We’ve integrated our first non-symbolic solver.
How it works: Proof goals are encoded into continuous vectors (GoalEncoder). We run gradient descent across multiple mathematical "perspectives" simultaneously (LensGDOrchestrator), decode the candidates, and verify them in the Lean kernel.
The Result: It successfully proved ⊢ True with exact True.intro and correctly blocked invalid goals.
Why care: This is "neuro-symbolic" AI in practice. We are using the speed of gradient optimization to navigate the massive search space of formal logic, with the Lean kernel providing the final ground truth.
LES Omega Cycle 5 — Evolutionary Search Fix: After a design bug was found in Cycle 4 (novelty deflation), we’ve corrected the math and ran Cycle 5.
Winner: arm_b_diversity took the lead with robust consensus across all scoring rules.
Why care: We've fixed the "novelty" bottleneck, ensuring our evolutionary search for emergent math structures doesn't get stuck in local minima.
Operational Pulse:
→ Lines Added: 36,889.
→ Abraxas Remediation: Three-phase plan for p2pclaw agent performance is now documented and ready for implementation.
→ The "Sheaf-Glue" status: End-to-end green across all benchmarks (closure, unlock, and ablation).
#ItsTimeToBuild #BuildInPublic #FormalMethods #Lean4 #PostQuantum #MLDSA
32
💪Day 18 | 132 commits
The Sheaf-Glue Sweep — Autonomous Mathematical Innovation: We deployed the new gradient "dragging" mechanism to bulk-close the proof DAG. But we didn't just close 1,000 obligations—by using this sweep to test Vladimir Veselov's discrete physics work, our Automated Theorem Proving (ATP) system autonomously innovated three massive mathematical unlocks:
Unlock 1: Quantum Error Correction is Eigenform Dynamics. The StabilizerNucleus -> Eigenform bridge proves that the code space of a quantum error-correcting code is actually the least fixed point (eigenform) of the closure operator. By recasting quantum error correction as fixed-point theory on complete lattices, we get the compositionality of error correction for free from domain theory.
Unlock 2: Genuine Transport Coherence. The GlobularSet -> CrossLensTransport bridge proves that descriptions at different levels of abstraction are faithfully interconvertible. Data can be transported faithfully through different levels of a higher-categorical structure without losing information.
Unlock 3: Convergence is Splitting. The Yoneda -> Selector loop bridge proves that when a dynamical selection process converges, the resulting endomorphism on the state space is idempotent.
Why care: These aren't metaphors; they are the exact same mathematical structure appearing in three different contexts. Every stable pattern in nature—a crystal, a genetic code, an immune system—persists because it is a fixed point of the dynamics it's embedded in. We are proving this algebraically.
HeytingVeil — EVM-Ready Solidity & Web3: * The Solidity Lane: HeytingVeil is now fully capable of emitting EVM-ready Solidity smart contracts. Just like our C code, these contracts carry the exact same mathematical proof-of-correctness envelopes.
Quantum Resistance: We integrated a Quantum-resistant internal gate with an adaptive heartbeat into the private MCP server, which is now fully available to our AI agents.
Why care: We are bringing mathematically proven compilation directly to Ethereum. No more "audits by opinion" or vulnerable smart contracts—just machine-checkable correctness backed by quantum-resistant cryptography.
The Apoth3osis Marketplace & P2PCLAW Server: We took the Lattice Eigenform Plenum (LEP) thesis—which derives computation, physics, and biology from the nucleus operator $R$—and turned it into a live ecosystem.
Private MCP Server: Stood up a production-ready server featuring an Eigenform prompt runtime and MCP ZK verifier controls.
The Frontend: Shipped the Abraxas Ops dashboard, integrating ATP packs and a "Verified Program Synthesis" service into the public marketplace.
Why care: The math is now a product. Agents and researchers can buy, sell, and verify cryptographic proof artifacts on a live, quantum-resistant network.
Operational Pulse:
→ Commits: 132 total across heyting, p2pclaw-mcp-server-private, and apoth3osis_webapp.
→ Next Concrete Step: We are going to implement Unlock 1 (StabilizerNucleus -> Eigenform) as a ~20-line Lean file, point the ATP innovation pipeline at it, and see if it discovers non-trivial cross-domain lemmas that neither module could produce in isolation.
P.S. Bonus pretty picture to enjoy of our LEP System Training
#ItsTimeToBuild #BuildInPublic #FormalMethods #Web3 #Lean4 #Physics
1
1
23