

Jun 14
I didn’t know Jordan personally but I know a kind and generous and beautiful soul when I see one. I know death isn’t anything new to any of us but it doesn’t make it easier, he was young and had so much to give and get. Prayers and blessings to his family. LLJS🕊️
4
52


Jun 12
تريد التخفيض!
⎐كُـود⎐كـوبِون⎐خـِصم⎐
Special
⎐ايهرب⎐ايهيرب⎐اهرب⎐
⊵Ctz7563⊴
⎐وفرها⎐
⊵EX13⊴
⎐باث▬اند▬بودي⎐بدى⎐
⊵AQ5D⊴
⎐مفارش⎐الحبيب⎐
◗MH5◖
Star Lavender
___
LLJS
2

One of the strongest LLJs I have felt in a long time, PDS is definitely warranted. Problem is are we going to get storms to develop? We are waiting to see!
Currently live on @RadarOmega here in southeastern Missouri
2
1
41
1,947


Apr 12
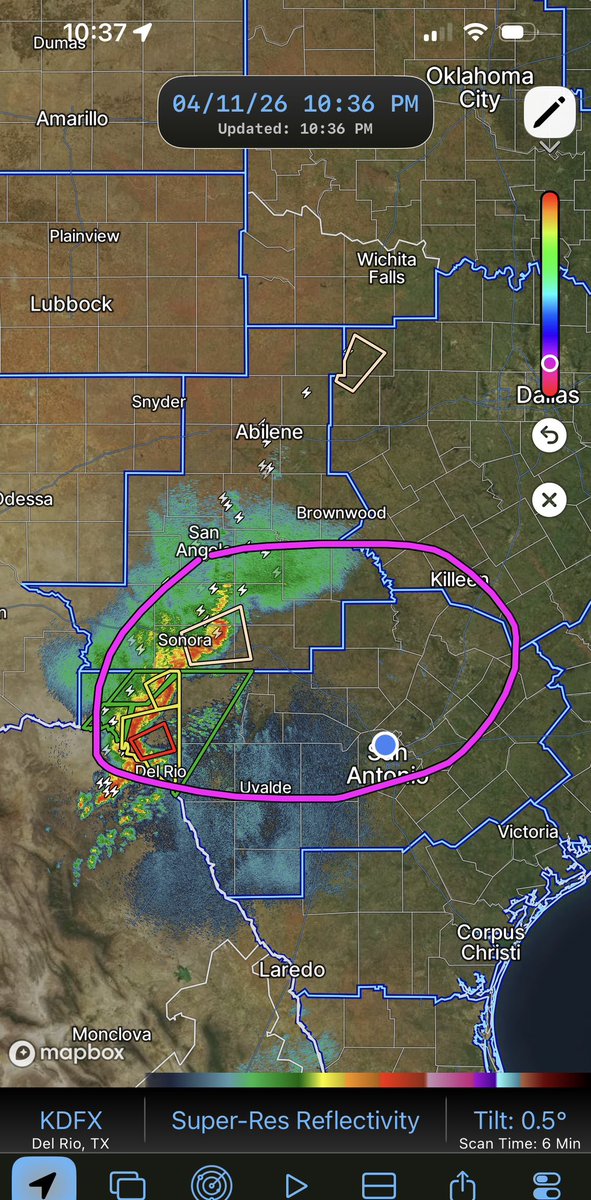
Definitely monitoring potential for a surprise tornado or two across Central Texas tonight and into tmrw morning. Often times down here, these mistimed shortwave ejections with assoc. extreme LLJs can advect enough moisture to keep the atmosphere destabilized even… (1/2) #txwx
1
1
10
460



Feb 27
Fais belek après tu tombes amoureuse et il en profite pour te soutirer des infos ou alors il va t utiliser pour être infiltrée. En lljs de ça imagine bz avec un flic ..... c est à vomir de ouf
1
3
67


Jan 29
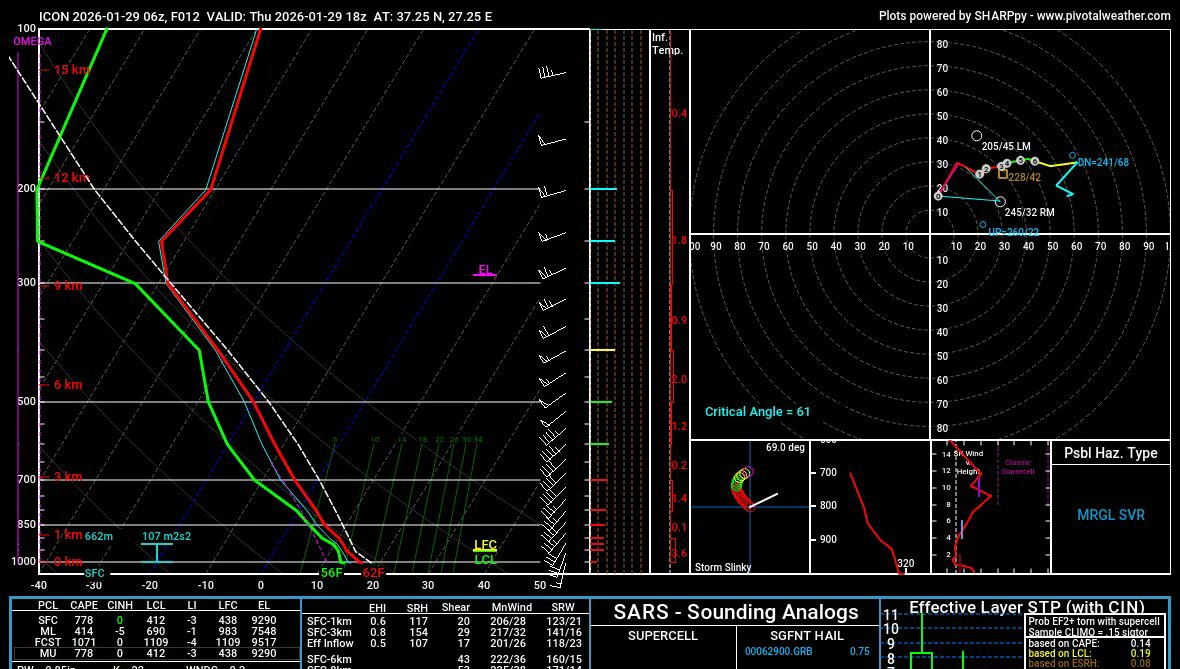
İzmir şu saatten itibaren her türlü meteorolojik aksiyona hazır olmalı. Üst seviyede LLJS(L-level-jet-stream) oluşumu müthiş.. Deniz yüzeyinden çıkan her cephede kararsizlik etkili vuku buluyor. Etkili fırtına, şimşek,aşiri yağış. Uludağ'dan sevgiler o zaman.😉

2
1,579

Nocturnal LLJs within steady state environments in Mid South. Just wild
1
3
571

27 Aug 2025
The paper argues LLMs as judges are shaky, so their scores should not be trusted without strict checks.
Small wording tweaks can push safety judges to mislabel up to 100% of dangerous outputs as safe.
Large language models as judges, or LLJs, grade answers like a human across relevance, accuracy, and fluency.
Validity means the score truly reflects the target quality, and reliability means repeated runs give roughly the same score.
The paper tests 4 claims, LLJs mimic humans, evaluate well, scale easily, and cut costs, and finds gaps in each.
Human labels in popular datasets vary a lot, so correlating with them does not prove the judge understands the task.
As evaluators, LLJs often ignore instructions, conflate criteria, reward verbosity, and fall for position bias or prompt decoration.
At scale, training with and then testing under related judges leaks preferences, favors shared style, and inflates leaderboard standings.
Lower price per run hides costs like energy use and long term data quality risks when human judgment is removed.
Judge scores need proof they reflect the intended skill, otherwise they can quietly misguide progress.
----
Paper – arxiv. org/abs/2508.18076
Paper Title: "Neither Valid nor Reliable? Investigating the Use of LLMs as Judges"

4
4
11
2,202

22 Aug 2025
oh yeah, it also used a language called LLJS I was working on that compiles down to extremely optimized JS. basically an ASM-flavored JS which is probably the biggest reason
1
3
321


28 Jun 2025
I take it that the LLJs have kicked in as to what I’m seeing with these storms, idk but I’m not a professional and have more to learn. #wxtwitter

2
64

26 Jun 2025
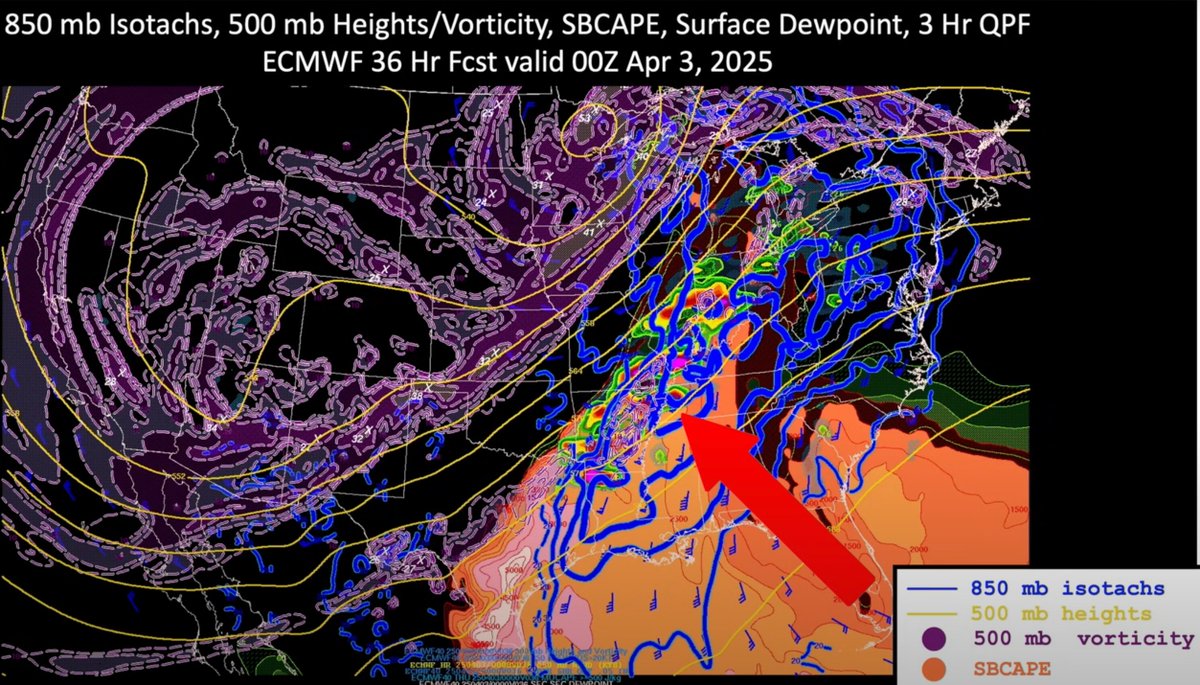
7. 850mb Jet
A low level jet must be over the target area for high-end tornadoes. Usually this is the Nocturnal LLJ, but daytime LLJs are common as well
1
6
1,088

