

Jan 24
이번 JPM에서 @jrkelly 가 발표한 내용은 @Ginkgo 투자자라면 꼭 봐야할 것으로 생각합니다.
동영상을 보실 시간 없는 분들을 위해 아래 한글 번역 전문 공유합니다.
(00:01) 안녕하세요. 제44회 JP모건 헬스케어 컨퍼런스에 오신 것을 환영합니다. 저는 JP모건 헬스케어 투자은행 팀의 어소시에이트 유 황입니다. 오늘 다음 발표 기업인 Ginkgo Bioworks를 소개하게 되어 매우 기쁩니다. 그럼 공동 창업자 겸 CEO, 제이슨 켈리를 모시겠습니다.
네, 좋습니다. 오늘 여기 오게 되어 정말 기쁩니다.
(00:30) 솔직히 말씀드리면, 지난 며칠 동안이 제가 지난 10년 JP모건 행사 중에서 가장 즐거웠던 것 같습니다. 메리어트 마키(Marriott Marquee) 로비에 저희 로보틱스 시스템을 설치해두었는데, 많은 분들이 지나가시면서 자율 실험실(autonomous labs)에 대해 배우고, 저는 거기 서서 직접 설명해드릴 수 있었거든요.
(00:51) 그래서 오늘 발표에서 제가 가장 집중해서 말씀드릴 건, 바로 그 내용입니다. 요즘 관심이 정말 뜨겁고, 이게 **깅코의 “생물학을 더 쉽게 공학적으로 다루게 만들자”**라는 미션과도 아주 잘 맞는다고 봅니다. 저희 관점에서는 앞으로 그 기술적 기반이 **‘자율 실험실’**이라는 개념 위에 놓이게 될 거라고 생각합니다.
(01:09) 또 상업적 측면에서도 운이 좋았습니다. 최근 새롭게 출범한 Genesis Mission 하에서 계약을 하나 따냈거든요. 이건 트럼프 대통령이 “AI를 과학에 접목하자”는 취지로 내린 행정명령입니다. 그 아래에서 저희가 미국 에너지부(Department of Energy)와 4,700만 달러 규모 계약을 체결했고, 워싱턴주에 있는 **Pacific Northwest National Lab(PNNL)**에 97대 로봇 규모의 대형 자율 실험실을 구축하게 됐습니다.
(01:33) 그리고 이건 아주 최근인 작년 12월에 첫 18대 로봇(대형 실험실의 축소 버전)을 먼저 오픈했고, 당시 에너지부 장관인 **라이트 장관(Secretary Wright)**이 와서 리본 커팅도 했습니다. 12월 말에는 기자회견도 했고요. 즉, “이런 개념이 실제로 시장에서 움직이기 시작한다”는 신호가 보이기 시작했습니다.
그래서 오늘은 조금 깊게 들어가서, 앞으로 5~10년 동안 깅코가 어떤 방향으로 쌓아올릴지 말씀드리려 합니다.
(01:57) 먼저, 자율 실험실이 왜 바이오테크·제약은 물론 과학 전반을 바꿔놓을 것인지를 말씀드리고,
두 번째로는 자율 실험실의 기술적 기반, 즉 “기존의 실험실 자동화(lab automation)와 자율 실험실은 무엇이 다른가”를 설명하겠습니다. 실험 도구 산업에서는 자동화가 오래전부터 있었거든요.
마지막으로, **깅코가 이걸 어떻게 시장에 내놓을지(Go-to-market)**를 말씀드리겠습니다. 크게 두 가지 방식이 있습니다. 하나는 DOE처럼 “고객에게 실험실을 직접 구축해서 판매”하는 것이고, 다른 하나는 보스턴에 있는 깅코의 대형 자율 실험실을 기반으로 “서비스를 판매”하는 방식입니다.
(02:27) 자, 시작하겠습니다. 저는 IBM 역사에 약간 ‘덕후’ 성향이 있습니다. 특히 1950~60~70년대 IBM을 좋아하는데, 그 시기에 IBM이 계산(computation)에 자동화를 들여오면서 오늘날의 테크 산업 기반을 깔았다고 생각하거든요.
(02:50) 여기 1951년 IBM 광고가 있습니다. “이 IBM 전자 계산기는 150명의 엔지니어가 하는 일을 한다”라고 되어 있죠. 제가 이걸 좋아하는 이유는, 저걸 잘 모르실 수도 있는데, 당시 엔지니어들이 들고 있는 건 **슬라이드 룰(계산자)**입니다. 수동 계산 도구죠.
제가 과학자들에게 실험실 자동화를 이야기하면 “그럼 과학자 일자리가 사라지는 거 아니냐”는 걱정이 종종 나오는데요.
(03:18) 이 장치는 수동 계산을 하던 엔지니어 150명을 대체했습니다. 그런데 오늘날 IT 분야의 엔지니어 수는 1950년보다 훨씬 많습니다. 오히려 계산을 자동화했기 때문에 더 많아졌죠. 자동화 덕분에, 그 엔지니어들의 머릿속 지식이 훨씬 더 큰 레버리지로 쓰이게 되면서 투자 대비 수익(ROI)이 크게 올라갔기 때문입니다. 계산이 자동화되자 사람의 역량이 ‘더 넓게’ 퍼져 나갈 수 있게 된 거죠.
(03:47) 이 프레임이 이해되시나요? 그래서 저는 컴퓨터 산업과 다른 산업의 역사를 조금 이야기한 다음, 그게 실험실에 무엇을 의미하는지 말씀드리겠습니다.
(04:04) 단순히 자동화만으로는 충분하지 않습니다. 제가 머릿속에서 이렇게 정리합니다. 세로축(y축)은 자동화의 정도입니다. 아래쪽(낮은 자동화)은 슬라이드 룰이나 종이 노트처럼 완전 수동이고, 위쪽(높은 자동화)은 IBM 전자 계산기 같은 겁니다.
(04:24) 가로축(x축)은 또 하나의 중요한 요소인 **유연성(flexibility)**입니다. 메모지와 슬라이드 룰은 온갖 계산을 다 할 수 있어서 유연성이 매우 높습니다. 반면 그 시절 IBM 전자 계산기는 나눗셈/뺄셈/덧셈 같은 제한된 기능만 했어요. 즉 자동화는 높지만 유연성이 낮았던 거죠.
(04:47) 진짜 돌파구는 10~15년 뒤 IBM 메인프레임에서 왔고, 결국 우리 삶에 완전히 들어온 건 개인용 컴퓨터였습니다. 컴퓨터는 자동화와 유연성을 동시에 줬습니다. 왜냐하면 코드로 움직였기 때문입니다. 다른 코드를 넣으면 다른 일을 하게 만들 수 있죠.
이해되시죠? 그래서 바로 이 오른쪽 위(자동화도 높고 유연성도 높은) 영역이 전체 테크 산업을 만들었습니다.
(05:10) 그리고 지금 비슷한 일이 또 다른 영역, 즉 **교통(transportation)**에서 일어나고 있다고 봅니다. 100년 전을 생각해보면, 샌프란시스코 트롤리나 뉴욕·보스턴의 지하철 같은 게 있죠. 이건 자동화가 높습니다. 타기만 하면 알아서 갑니다. 하지만 유연성은 낮아요. 정해진 역으로만 가죠.
(05:29) 반대로 자동차는 유연성은 엄청나지만 완전 수동입니다. 운전자가 직접 운전해야 하죠. 지난 80~100년 동안 우리는 오른쪽 위(자동화 유연성)를 사실상 못 가졌습니다. 그런데 최근에 거리에서 많이 보셨을 겁니다. **자율주행차(autonomous cars)**가 등장하면서 그 돌파가 일어났습니다.
(05:49) 자율주행차는 자동화되어 있고 유연합니다. 뒷좌석에 앉아서 목적지만 말하면 어디든 갑니다. 제 관점에서 이건 컴퓨터와 같은 존재입니다. 자동화와 유연성을 동시에 주기 때문에, 앞으로 교통 산업 전체를 자율성 위에서 다시 구축하게 될 거라고 봅니다. 컴퓨터가 1960년대에 그랬던 것처럼요.
(06:11) 그렇다면 과학, 특히 실험실 작업(제약 산업과 신약 개발을 만들어내는 엔진)에서는 어디쯤 와 있을까요?
(06:35) 사실 실험실에는 자동화가 이미 있습니다. 30~40년 전부터요. 제가 그림에서 왼쪽 위에 둔 **자동화 워크셀(automation work cells)**입니다. Thermo Fisher나 HighRes Bio 같은 곳에서 살 수 있고, 여러 전문 업체들이 있습니다. 이런 워크셀은 주로 하이쓰루풋 스크리닝(HTS) 같은 데 쓰입니다. 예를 들어 10만 개 화합물을 특정 세포 어세이에 걸어서 “건초더미 속 바늘”을 찾는 식이죠. 진단 검사실에서도 수천 개 혈액 샘플에 동일한 패널 검사를 반복하는 데 쓰입니다. 즉 유연성은 낮고 자동화는 높습니다.
(06:53) 오른쪽 아래는 수동 실험대(manual lab bench)입니다. 유연성은 높지만 수동이죠. 놀라운 건, 머크(Merck)나 화이자(Pfizer) 같은 회사 실험실에 들어가도, 실험대는 100년 전과 크게 다르지 않은 모습을 많이 보게 된다는 겁니다. 왜냐하면 과학자에게 유연성을 주니까요. 파이펫을 들고, 지난주 논문에서 본 실험을 바로 해볼 수 있습니다.
(07:24) 그래서 깅코가 지금 목표로 하는 건 오른쪽 위입니다.
자율주행차가 “어디든 데려다 주는 자동화 유연성”이라면, 우리는 과학자에게 **‘자율 실험실’**을 제공하고 싶습니다. 완전 자동화되어 있지만, 지하철처럼 한 가지 정해진 작업만 하는 게 아니라, 웨이모(Waymo)처럼 과학자가 원하는 실험이면 이전에 한 번도 요청받지 않은 실험이라도 그날 수행할 수 있는 실험실 말입니다.
(08:05) 이걸 구축할 수 있다면, 컴퓨터나 웨이모처럼 “자동화 유연성” 위에서 산업을 다시 짤 수 있을 거라고 기대합니다. 매우 강력하죠. 왜 이걸 하고 싶은지는 여기까지로 하고요.
(08:22) 핵심 기술 질문은 이겁니다. “어떻게 하느냐?”
어떻게 하면 자동화도 높고 유연성도 높은 오른쪽 위로 갈 수 있느냐는 거죠.
(08:43) 자율 실험실은 전통적인 실험실에서 하던 일을 “수동 노동 없이” 수행할 수 있어야 합니다. 그러려면 먼저 전통적인 실험실이 어떻게 돌아가는지부터 정리해보죠.
참고로, 제가 요즘 링크드인에서 ‘인플루언서 시대’에 들어섰다는 말도 들으니 혹시 보셨을 수도 있습니다.
(09:04) 전통적인 실험실은 이런 모습입니다. 예를 들어 포유류 세포 공학, CAR-T 같은 일을 하려고 실험실을 열면, 장비가 15~20개 정도 있습니다. 문을 열고 들어가면 장비들이 벤치 위에 놓여 있고, 벤치도 한 개가 아니라 보통 5~8개 정도 있어 과학자들이 서서 작업합니다. 벤치 위에는 파이펫이 있고 각종 시약에도 접근할 수 있죠.
(09:19) 과학자들이 매일 하는 일은 크게 세 가지입니다.
첫째, 시약을 꺼내 파이펫으로 액체와 재료를 수동으로 다뤄 반응 샘플을 만듭니다.
둘째, 그 샘플을 실험실의 10~15개 장비 사이로 옮깁니다. PCR로 가져가고, HPLC로 가져가고, 원심분리기로 가져가고, 한 장비가 끝나면 다음 장비로 옮깁니다.
셋째, 샘플을 장비에 넣을 때마다 장비 설정을 직접 입력합니다. 원심분리기 RPM은 얼마로 할지, 써모사이클러 프로그램은 어떻게 할지 같은 것들을 과학 지식으로 결정해서 입력하는 거죠.
즉 조합은 다양하지만, 본질은 이 세 가지 활동입니다.
(10:08) 그렇다면 이걸 자율 실험실로 바꾸려면 무엇이 필요할까요?
(10:28) 첫째, **신뢰할 수 있는 액체 핸들링(liquid handling)**이 필요합니다. 파이펫을 로봇으로 대체해야 합니다. 다행히 Tecan, Hamilton, 그리고 OpenRS 같은 신규 업체들까지 30년 동안 액체 핸들링 로봇을 만들어왔고, 실제로 꽤 훌륭합니다. 솔직히 말하면(여기선 조용히 하죠), 실험대에서 사람이 하는 것보다 더 안정적인 경우도 많습니다.
다만 사용하기 쉽진 않습니다. 프로그래밍이 어렵죠. 그 부분은 조금 뒤에 이야기하겠습니다.
(10:43) 둘째, 15개 장비 사이를 오가며 **물질을 운반(transport)**할 수 있어야 합니다.
셋째, 장비들의 설정값을 소프트웨어로 제어하는 **파라미터 제어(parameterized control)**가 필요합니다.
넷째, 15개 중 일부만 있으면 안 됩니다. 15개 전부, 즉 “실험실 전체”가 한 세트로 있어야 합니다. 미리 어떤 샘플이 A에서 G로 갈지 알 수 없기 때문입니다.
다섯째, 이게 까다로운데, **병렬 작업(parallel work)**을 지원해야 합니다. 전통 실험실에서는 한 사람이 들어가 문 잠그고 “오늘은 나만 쓴다”가 아니죠. 여러 과학자가 동시에 장비 사용을 조율하며 씁니다. “나는 이 장비 2시간 쓸게요.” “그럼 전 4시간 인큐베이션 하고 나서 쓰겠습니다.” 이런 식으로요. 여러 파이펫 스테이션도 있고요.
따라서 동일한 15개 장비를 많은 사람들이 동시에 쓰게끔 시스템이 설계돼야 합니다.
(11:52) 마지막으로, 사용이 전통 실험실만큼 쉬워야 합니다. 전통 실험실을 쓰는데 소프트웨어 개발자가 될 필요는 없죠. 자율 실험실도 과학자가 쓰려면, 코드를 직접 짜는 방식이 아니라, 요즘 AI 모델이나 노코드 에이전트처럼 자연어 기반 인터페이스에 가까운 형태가 되어야 합니다.
(12:14) 이 리스트가 이해되시나요? 이걸 다 해결하면, 세상에 존재하는 거의 모든 실험실—머크 같은 제약사, 진단 회사, 모든 대학 연구실—에서 하는 일을 자율 실험실이 할 수 있게 됩니다. 그리고 24/7로 더 높은 신뢰도로, 더 효율적으로 수행할 수 있죠.
(12:54) 하지만 이건 정말 어렵습니다. 하드웨어와 소프트웨어 모두에서 아주 어려운 기술 문제입니다. 그래서 저희가 무엇을 했고 어떤 접근으로 문제를 풀고 있는지, 그리고 지금 어디까지 와 있는지 말씀드리겠습니다.
(13:11) 여기서 핵심 부품이 나옵니다. 이게 깅코가 만든 것인데, **RAC(Reconfigurable Automation Cart)**라고 부릅니다. 기본적으로 앞서 말한 “실험실의 15개 장비 중 하나”를 감싸는 **표준화된 외피(엔벨롭)**라고 보시면 됩니다. 어떤 생명과학 장비든(수많은 업체들이 파는 서드파티 장비든) 이 RAC 표준 안으로 ‘감싸서’ 넣을 수 있습니다.
(13:34) 이렇게 감싸면 몇 가지가 가능합니다. 여기 보시면 6축 로봇팔이 있고, 마그네틱 기반 운송 시스템(예: magnumotion 트랙)이 있어서 샘플을 로봇팔까지 가져다줍니다. 로봇팔이 샘플을 집어(여기서는) 원심분리기(빨간 박스)에 올립니다.
아래쪽에는 전자 하드웨어가 있어 장비와 연결됩니다. 전원 리셋도 하고, 설정도 바꾸고, 과학자가 실험대에서 할 수 있는 일을 소프트웨어로 다 할 수 있습니다.
(14:09) 그리고 중요한 점은 표준화입니다. 장비마다 크기는 조금 다르지만 높이가 같고 구조가 규격화되어 있어서, 레고처럼 붙여서 확장할 수 있습니다. 3개든 15개든(아까 예시 실험실) 97개든(DOE 프로젝트) 한 덩어리의 시스템으로 만들 수 있습니다.
(14:27) 실제 모습을 보여드리면 이해가 더 쉬울 겁니다. 지금 보시는 영상은 워크플로우(프로토콜)가 시스템에 들어가 실행되는 장면입니다. 보스턴에 있는 저희 시스템은 RAC가 40개 있고요. 시스템 제약 중 하나는 샘플이 SPS 표준 포맷, 즉 96/384/1536웰 플레이트 형태로 이동한다는 점입니다. 업계 표준이고 많은 장비들이 이 플레이트를 받습니다.
(14:51) 보시면 샘플이 원심분리기로 이동했고, 이제 Echo 액체 핸들러로 갑니다. 이건 Labcyte의 음향(acoustic) 액체 핸들러입니다. 액체 핸들링 장비 중 하나죠.
(15:09) 그 다음에는 또 다른 액체 핸들링 장비로 넘어갑니다. Agilent Bravo입니다. 이 경우는 ‘액체 스탬핑’ 방식으로 여러 팁을 한 번에 집어서 액체를 찍어 넣습니다.
여기서 포인트는 첫 장비는 Danaher 산하(Labcyte)이고, 두 번째는 Agilent라는 점입니다. 그런데 과학자는 Danaher 소프트웨어도, Agilent 소프트웨어도 쓸 필요가 없습니다. 오직 깅코 소프트웨어만 쓰면 되고, 저희 소프트웨어가 각 장비의 서드파티 소프트웨어로 번역해줍니다.
(15:48) 이게 정말 중요합니다. 장비마다 소프트웨어가 다르면 미쳐버립니다. 그래서 통합이 핵심입니다. 이제 샘플은 셰이커로 갔다가, 최종적으로 써모사이클러로 가서 반응을 돌리고 어세이를 합니다.
(16:05) 또 좋은 점이 몇 가지 있습니다. 각 카트에 카메라가 있어서 모든 과정이 기록됩니다. 에러가 나면 확인할 수 있고, 데이터도 계속 쌓입니다. 실험대에서 사람이 파이펫 할 때는 “어느 웰에 잘못 넣었는지” 같은 기록이 없습니다. 반면 자율 실험실에서는 모든 단계, 모든 행동이 전자적으로 기록됩니다. 즉, 전체 로그가 남습니다. 수동 노동이 0이 된다는 것 외에도 부가적인 이점이 많은 거죠.
(16:44) 다음은 **병렬화(parallelization)**입니다. 앞 영상은 하나의 런만 보여드렸지만, 이건 어제 보스턴 시스템 화면을 캡처한 것입니다. 각 줄은 장비 하나, 가로는 시간입니다. 색깔 하나가 서로 다른 프로토콜입니다.
(17:08) 아까 말했듯이 전통 실험실에서는 “PCR 기계 언제 비나요?” “3시간 뒤요.” “그럼 저는 4시간 인큐베이션 먼저 하고, 그 다음 PCR 넣겠습니다.” 이런 식으로 사람끼리 조율합니다. 여기서는 그걸 컴퓨터가 합니다. 과학자가 프로토콜을 제출하면 시스템이 “오늘 이 프로토콜을 끼워 넣을 수 있나? PCR은 그때 비나? 원심분리기는 비나? 여러 프로토콜을 재배치해서 네가 끼워 들어올 수 있게 할 수 있나?”를 계산합니다.
(17:56) 이게 두 가지 이유에서 중요합니다.
첫째, 많은 과학자들이 제출한 서로 다른 프로토콜을 동시에 돌릴 수 있다는 점입니다. 지금은 17개 프로토콜이 동시에 돌아가고 있죠. 그리고 제가 강조하고 싶은 건, 현재 세계의 어떤 실험실 자동화 시스템도(우리 말고는) 이 규모로 이런 병렬 스케줄링을 하지 못합니다.
둘째, 전통 실험실에서는 “오늘 장비가 바쁘네요. 그럼 내일 할게요”가 자주 발생합니다. 그래서 장비 가동률이 30%도 안 되는 경우가 많습니다. 비싼 장비가 대부분 그냥 놀고 있는 거죠. 인간의 수동 스케줄링이 형편없기 때문입니다. 우리는 알고리즘으로 거의 최적화에 가깝게 스케줄링을 해서 장비 활용률을 크게 올릴 수 있습니다.
(18:58) 그리고 작은 규모로도 시작할 수 있습니다. 메리어트 로비에는 장비 4개짜리 시스템을 돌려놨고요. 보스턴은 40개, 그리고 PNNL에는 더 큰 규모로 갑니다.
(19:19) 오늘 자세히 다 말하진 않겠지만, 앞으로 더 이야기할 주제입니다. 중요한 건, 과학자가 프로토콜을 제출할 수도 있지만, AI 과학자도 프로토콜을 제출할 수 있다는 점입니다. 구글도 AI 과학자를 실제로 만들고 있고, OpenAI나 Anthropic도 이런 영역을 계속 발표하고 있고, Edison 같은 전문 회사들도 AI 과학자를 만들고 있습니다.
하지만 이 회사들이 가진 막대한 데이터센터와 모델에도 **“실험실에서 직접 손이 되는 것”**이 없습니다. 바이오·제약에서 AI가 진짜 힘을 받으려면, 추론 모델에 “실험실 손”을 달아줘야 합니다. 그 방법이 바로 자율 실험실입니다. 사람을 중간에 끼우지 않는 엔드투엔드가 되어야 합니다.
(20:12) 고객 입장에서 자율 실험실의 가치 제안을 정리하면 이렇습니다.
(20:32) 첫째, 실험실 운영 비용(오버헤드)을 크게 줄입니다. 제 목표는 단지 “하이쓰루풋 스크리닝 워크셀”을 대체하는 게 아닙니다. 물론 그 시장(연 4~5억 달러)에도 들어갈 수 있고, 발판으로 삼을 수는 있습니다. 하지만 제가 진짜 하고 싶은 건, 미국의 모든 실험실이 문을 닫고, 자율 실험실로 대체되는 것입니다. 과학자는 컴퓨터로 실험을 ‘주문’하고 수행하는 방식으로요. 특히 미국은 중국에 비해 과학 인건비 경쟁력이 약하니, 생산성 향상이 없으면 경쟁 자체가 어렵습니다. 그래서 Genesis mission, AI for science 같은 흐름이 나오는 겁니다.
(21:11) 둘째, AI 모델을 위한 연구 생산성입니다. AI는 전통적인 수작업 실험으로는 만들기 어려운 훨씬 더 큰 데이터셋을 필요로 합니다. 워크셀로도 일부는 가능하지만, 사람들은 시간에 따라 필요 데이터가 계속 바뀝니다. 데이터셋마다 일회성 워크셀을 새로 만드는 건 비효율적이죠. 대신 “무엇이든 바꿔가며 수행할 수 있는” 대형 자율 실험실 위에 올라타는 편이 낫습니다.
(21:41) 셋째, AI 과학자에게 실험실 손이 필요합니다. 요즘 제약사들에서는 이를 “lab in the loop”라고 부르기도 합니다. 수요가 조금씩 보이고요. 그리고 첫째, 둘째는 결국 미국의 모든 실험실이 체감할 장점이라고 생각합니다.
(21:55) 그럼 시장 진입은 어떻게 하느냐.
제가 생명과학 도구 산업을 보면 Thermo, Danaher 같은 대기업들이 전부 “실험대에서 손으로 하는 과학”이라는 패러다임 위에 서 있습니다. 손으로 쓰는 액체 핸들링 도구, 손으로 열고 닫기 좋은 튜브 형태의 키트, 사람이 터치하는 터치스크린 장비… 전부 “수동 과학”을 전제로 한 도구 스택입니다.
(22:44) 우리가 자율 실험실을 성공적으로 구축하면, 생명과학 도구 스택 전체를 다시 만들어야 합니다. 그걸 깅코가 하려고 합니다.
단기적으로는 두 가지 방식입니다.
첫째, 고객 사이트에 자율 실험실을 직접 구축해서 판매합니다(DOE처럼). 진단, 제약, 워크셀 딜 등에서 경쟁하면서 들어갑니다.
둘째, 보스턴에 있는 세계 최대급(프런티어) 자율 실험실을 운영하면서 그 위에 서비스를 판매합니다. 현재 RAC 40개이고, 5~6월쯤에는 100개로 늘릴 계획입니다.
(23:33) 보스턴 실험실 위에서 제공하는 서비스는 두 가지입니다.
첫째 Solutions(솔루션): 깅코 과학자들이 자율 실험실을 활용해 고객의 연구 결과물을 만들어주는 모델입니다. 전통적으로 해오던 방식이고, 로열티·마일스톤·바이오벅 같은 형태로 수익을 얻습니다.
둘째 Datapoints(데이터포인츠): 지난 1년 반 동안 새로 시작한 서비스로, 고객 과학자들이 보스턴 실험실에 **실험을 “주문”**합니다. 현재는 “메뉴형 서비스”로 제공하고 있고, 장기적으로는 정말 ‘클라우드 랩’처럼 아무 실험이나 주문할 수 있는 형태가 되길 기대합니다.
(24:22) 저희가 이렇게 직접 대형 자율 실험실을 운영하면 이점이 있습니다.
첫째, “가능한 것의 수준(art of the possible)”을 고객에게 보여줄 수 있습니다. 예를 들어, 과학자 10명이 하루에 20개 프로토콜을 올려도 시스템이 불타지 않고 돌아간다는 걸 제가 먼저 증명할 수 있죠. 그러면 머크 같은 회사의 R&D 책임자도 “이미 된다”는 걸 보게 됩니다.
둘째, 하드웨어 위에서 실제 과학을 돌리기 때문에, 전통적인 로봇/도구 회사보다 훨씬 빠르게 기술을 개선할 수 있습니다. 저희 팀이 매일 시스템을 깨뜨리니까, 소프트웨어 팀이 바로 버그를 고치고 개선합니다. 고객 피드백을 긴 주기로 받는 회사들과는 다르죠. 흔히 말하는 “dogfooding(자기 제품을 스스로 쓰며 개선하기)”입니다.
(25:08) 솔루션 측면에서는 250개 이상의 파트너십을 해왔고, 제약·산업바이오·농업 등 다양합니다. 다만 지난 1년 반 동안은 솔루션 판매 영역을 강하게 좁혔습니다. 현재는 주로 치료제(therapeutics) 중심, 농업은 일부만 합니다. 이게 비용 구조를 줄이는 데 큰 도움이 됐습니다. 그래도 2025년에 기존 고객/신규 고객 대상으로 솔루션 딜은 계속 했고, 정부 R&D 프로젝트도 많이 했습니다.
(25:46) Datapoints는 제가 말한 CRO 서비스, 즉 고객이 원하는 데이터셋을 만들어주는 서비스입니다. 지금 세 가지 라인이 있습니다.
첫째 Omics: 기능유전체학 어세이입니다. “내가 좋아하는 세포주가 있는데, CRISPR 편집 5,000개를 만들어서 drug-seq를 하고, 전사체 데이터를 깨끗이 정리해서 S3(아마존 버킷)에 넣어 ML팀이 바로 쓸 수 있게 보내달라” 같은 주문이 가능합니다. 이런 건 지금 WuXi 같은 데서 받기 어렵습니다. 즉 AI 시대에 맞춘 대규모 데이터 생성형 CRO입니다.
둘째, 항체 developability(개발가능성) 관련 서비스입니다.
셋째, 최근에 런칭한 ADME입니다.
(26:28) 그리고 저는 요즘 Chai Bio의 Lilly 딜 같은 걸 보면서, “빅파마가 좋은 AI 모델을 라이선스하기 위해 큰 돈을 낸다”는 비즈니스 모델이 나오기 시작했다고 봅니다. 그런데 그런 AI 모델이 “흥미로운” 이유는 결국 독점적(proprietary) 데이터로 학습했기 때문입니다. 한때는 “가장 똑똑한 AI 인력이 누구냐” 경쟁 같았지만, 아주 빠르게 “누가 어떤 데이터를 가지고 있느냐”로 옮겨가고 있습니다. 항체 결합/개발가능성/스몰몰 등 무엇이든요.
(27:23) 다음에 Lilly와 또 큰 딜을 하는 회사가 나온다면, 그건 결국 “대규모 독점 데이터셋을 만들어냈기 때문”일 가능성이 큽니다. 그리고 우리는 그 데이터 생성(scale data generation)을 해주는 회사가 되고 싶습니다. 예전에 OpenAI가 초기에 데이터 생성에서 도움을 받았던 것처럼, 우리는 AI 모델 회사들이 직접 실험실을 구축하지 않고도, 컴퓨팅 팀에 집중하면서 데이터 생성은 우리 보스턴의 클라우드형 자율 실험실에 외주 줄 수 있게 하려는 겁니다.
(27:44) 우리는 일부 데이터셋을 공개로도 배포합니다. 공개로 나온 것 중 가장 큰 항체 developability 데이터셋을 냈고, drug-seq도 그렇고, ADME도 그렇고요. 이런 데이터 드롭을 계속할 겁니다.
그리고 Ginkgo 팀이 AI for bio 커뮤니티에서 커뮤니티 빌더 역할을 정말 잘하고 있다고 봅니다. 항체 developability 대회도 했고, Datapoints Summit 같은 큰 행사도 했고, VCPI(가상 세포 약리학 이니셔티브)도 운영하고, 데이터 드롭도 인기가 많습니다.
그리고 이 서비스는 1년 조금 넘게 됐는데, 지금은 Top 20 제약사 중 10곳과 협업하면서 데이터 생성도 해주고, 스타트업 AI 바이오 쪽도 일부 같이 합니다. 공개 가능한 회사만 아래에 보이겠죠.
(28:33) 또 솔루션과 데이터포인츠는 자율 실험실 “직접 판매” 비즈니스를 키우는 동안의 수익 기반이 됩니다. 장비, 소프트웨어, 궁극적으로는 시약까지 고객에게 판매하려면 시간이 걸리니까요.
재무적으로는, 지난 어닝콜에서 연간 매출 가이던스 1억 6,700만~1억 8,700만 달러를 재확인했고, 서비스 매출 비중이 상당합니다. 또 지난 1년 반 동안 현금 소진(cash burn)을 73% 줄였고, Q3 말 기준 현금 4억 6,200만 달러, 은행 부채는 없습니다. 저는 이 포지션이 좋다고 봅니다. 런웨이가 길고, burn이 통제되는 상태에서 자율 실험실 리더십을 가져갈 수 있으니까요.
(29:11) 다시 보스턴 실험실 사진입니다. Seaport에 있고, 오실 분은 방문하셔도 좋습니다.
깅코는 실험실 작업의 자율화 전환을 이끌기 좋은 회사라고 믿습니다.
자본도 충분하고, burn도 줄였고, 10년간 자동화와 스케일을 위해 별별 시도를 다 해봤습니다. 어디에서 문제가 터지는지(‘어디에 시체가 묻혀 있는지’)를 알고 있고, 그 경험이 RAC 하드웨어뿐 아니라 특히 소프트웨어에 녹아 있습니다. 과학자가 프로토콜을 올리면, 그 프로토콜이 안전하게 돌아가도록 하는 여러 체크가 깅코의 암묵지(tacit knowledge)를 반영해 작동합니다.
그리고 우리는 미션 드리븐입니다. 포기하지 않을 겁니다. 생물학은 아직 “IBM 모먼트”를 겪지 못했습니다. 아직 수동 시대에 살고 있습니다. 이걸 넘어서면, 우리가 할 수 있는 가장 중요한 일이 될 겁니다.
(30:28) 저는 50~60년 뒤에 “우리가 DNA 프로그래밍을 해금했다”는 식으로 회고되길 바랍니다. 컴퓨터 코드가 자동화로 풀린 것처럼, DNA도 자동화와 수동 노동 제거를 통해 프로그래밍이 가능해지는 시대를 열자는 겁니다.
오늘 듣고 계신 과학자 분들이 계시다면, 파이펫을 내려놓고 자율 실험실에 합류해 주셨으면 합니다. 우리가 보고 싶은 세상을 함께 키워갑시다. 제 이메일은 저기에 있고요. 질문 받겠습니다. 감사합니다.
감사합니다, 제이슨.
(31:07) >> 질문 하나 받겠습니다. DNA 합성에서 가장 긴 선형 서열은 어느 정도까지…?
질문은 “자동화 워크플로우에서 합성할 수 있는 DNA의 최대 길이가 얼마나 되느냐”는 거죠.
(31:41) 쉽게 말씀드리면, 이 시스템은 DNA 합성처럼 “한 가지 작업만”을 하도록 설계된 게 아닙니다. DNA 합성이든, 단백질 발현이든, 하이쓰루풋 스크리닝이든 뭐든, 결국 목표는 “실험실 전체를 대체”하는 것입니다.
어떤 프로토콜이 Echo, 써모사이클러 등을 쓰는 DNA 합성에 적합하다면, 그 프로토콜을 시스템에서 그대로 재현할 수 있습니다. 깅코도 일부 그런 일을 하고 있고요. 예전 Gen9 기술로는 50~100kb 정도도 만들었을 겁니다.
하지만 그게 핵심은 아닙니다. 핵심은 “내가 제공하는 특정 독점 프로토콜이 최고다”가 아니라, 다른 사람들이 훌륭한 프로토콜을 개발할 수 있게 해주는 인프라를 제공하는 겁니다. 이해되시나요?
(32:24) >> 물질 핸들링, DNA 블록 같은 로지스틱스 관점에서… 작은 분자 등은 재료 인벤토리가 다양해지면 더 복잡해지는데, 그게 자동화의 전통적 허들이었습니다.
네, 중요한 포인트입니다. 데이터센터는 정보가 움직이지만, 실험실은 **원자(atoms)**가 움직입니다. 결국 시스템에 “원자”를 넣어줘야 합니다.
현재는 우리 팀이 시약을 플레이트 형태로 준비해서 시스템에 투입하고, 그걸 바탕으로 과학자들이 주문한 커스텀 반응을 수행합니다.
장기적으로는, 제가 말한 “도구 스택 전체를 재구축해야 한다”는 맥락에서, 시스템 안에 “필요한 시약을 다 갖춘 카트”가 있을 겁니다. 주문이 들어오면 거기서 자동으로 뽑아 쓰고, 사용량 기반으로 과금하는 방식이 되겠죠. 이미 비슷한 모델이 있습니다. 예를 들어 Thermo나 다른 회사에서 냉동고를 임대하고, 사람이 꺼내 쓰면 과금되는 방식이 있거든요. 자율 실험실에서도 비슷하게 갈 수 있다고 봅니다.
(33:47) >> 어제 대화의 연장인데요. 소프트웨어 통합 문제입니다. 이게 되려면 API가 없는 서드파티 장비에도 연결해야 하고, 어떤 벤더들은 소프트웨어 수익 때문에 일부러 통합을 어렵게 하기도 합니다. 어떻게 극복하시는지, API 표준이 필요하지 않나요?
네, 맞습니다. 벤치탑 장비에는 표준이 거의 없습니다. “단일 장비를 사람이 만지고, 사람이 장비 사이의 접착제 역할을 한다”는 패러다임이라 장비끼리 대화할 필요가 없었고, 그래서 API 표준도 없었습니다.
플레이트에 SPS 표준이 있는 것도 사실 운이 좋은 편입니다. 화학 쪽은 그것도 없거든요.
장비 API 표준은 장기적으로는 분명 생길 거라고 생각합니다. PyLabRobot 같은 오픈소스 노력도 있고요.
다만 지금 당장은, 고객이 원하는 장비가 나오면 우리가 그 장비를 시스템에 붙이는 일을 합니다. 경우에 따라 API가 있기도 하고 없기도 합니다. 없으면 장비에 직접 드라이버를 짜서 붙이기도 하고요. 할 수 있는 건 다 합니다. 정말 불가능하면, 비슷한 기능을 가진 다른 회사 장비로 바꾸는 방법도 있습니다.
그래도 지금까지는 꽤 잘 통합해왔고, 새 장비를 붙이는 데 1~2개월 정도 걸립니다. 한 번 붙이면 그 뒤로는 계속 쓸 수 있고요. 이런 작업을 계속 해왔습니다. 지금 거의 100개 가까이 붙였을 겁니다.
(35:36) >> 자율 실험실이 바이오파마에 어떻게 도입될까요? 채택을 이끄는 동인은 무엇일까요?
핵심 질문입니다. 현재 자동화 시장(왼쪽 위 워크셀)은 HTS나 진단 검사실 등에서 꾸준히 RFP가 나오고 있습니다. 연 4~5억 달러 규모 시장이고, 3개 정도의 기존 강자가 장악하고 있죠. 우리는 그 시장에도 들어갈 수 있습니다.
방법은, 완전히 신규 업체라 쉽진 않지만 “우리 시스템은 더 일반적이고, 나중에 자율 실험실로 발전할 수 있다. 일단 너희가 한 가지 목적만 원하더라도 우리로 시작하자”라고 제안하며 발을 들여놓는 겁니다.
(36:31) 두 번째는 제약사 내부의 AI 책임자입니다. 이 사람들은 전통적인 drug discovery 관점과 다르게 실험실을 봅니다. 회사에 따라 다르지만, 내부 데이터 생성을 새 방식으로 하라는 미션을 가진 경우가 많고, 이런 경우 자율 실험실 직접 판매로 더 이어질 수 있습니다. 다만 시간이 좀 걸릴 거고, 그래서 서비스(보스턴 대형 실험실)가 중요한 겁니다. 우리가 “가능한 수준”을 보여줄 수 있으니까요.
Jan 23

Lately you have probably been hearing a lot about autonomous labs. Hear our CEO Jason Kelly explain what they are and how they will transform biotechnology at the JP Morgan Healthcare Conference last week in San Francisco.
youtube.com/watch?v=KkS58gon…
9
9
39
13,948

4 Nov 2025
先日パシフィコ横浜で行われた #日本動物実験代替法学会 38回大会に出展いたしました。
当社は今後も研究用ヒト培養組織LabCyteシリーズを通じて、動物実験代替に寄与してまいります。


21
372

18 Feb 2025
Learn how @ArzedaCo leveraged technology from TeselaGen, Labcyte and @TwistBioscience to accelerate their synthetic biology workflow and build a better DNA assembly line. teselagen.com/customer-stori… #synbio #biotech #biotechnology

1
1
8
780

looks tight. 💪
grew up on Gilson and CRS. Then onto way to Cavro & Tecan. Then came Velocity 11, Hamilton and finally HighResBio. But my favorite tool to this day is Labcyte ECHO...so much untapped potential still to be unlocked there. @Mdfctri09 MFC & Rich Ellson GOATs!
1
4
453

Sinéad’s experience working with health tech start-ups began when she joined Trinity College Dublin start-up company Deerac Fluidics in 2008.
During her time at Deerac Fluidics, the company was acquired by US multinational Labcyte Inc.
1
3
42


18 Jun 2022
We recently installed a new Labcyte @LabcyteInc Echo 525, an equipment that automates and miniaturizes the library preparation process (reduces the quantities of samples, reagents, etc. used in the process). Thereby facilitating efficiency and speed.



4
19
67

3 Mar 2022
The labcyte echo is just a very cool piece of hardware you got to give it up for em
4
28

Evaluating the LABCYTE Echo 525 Acoustic Liquid Handler for genomic applications. Incredible speed and accuracy when delivering nanoliter droplets for NGS library quantification, normalisation and pooling. @BeckmanCoulter @OusResearch



3
3

15 Dec 2021
Labcyte is a global biotech company revolutionizing liquid handling with the Echo® acoustic liquid handling technology. This company developed innovative technology that produces faster and more accurate results than traditional pipetting methods. deep-pharma.tech/advanced-te…

3

25 Jun 2021
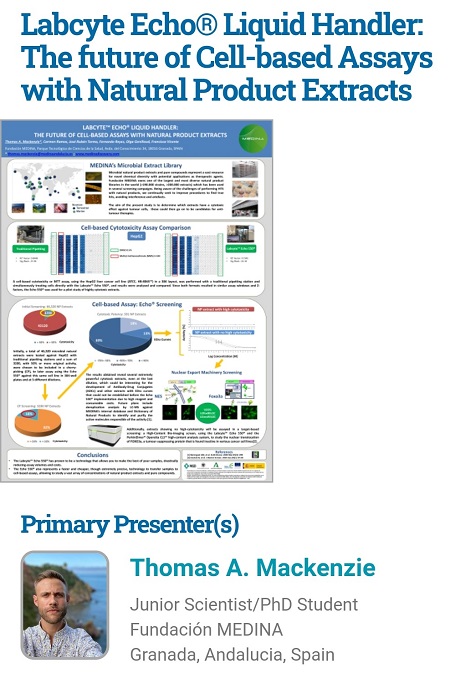
@MEDINADiscovery is attending the #SLASEurope21 Thomas Mackenzie,Junior Scientist at Fundación MEDINA is presenting his poster Labcyte Echo® Liquid Handler: The Future of Cell-Based Assays with Natural Product Extracts.
3
1



26 Jun 2020
#Trending Compound Management Market 2020 In-depth Analysis by Leading Players: @Brookslifesciences, @Tecan_Talk, @HamiltonCompany @Biosero @Labcyte
Read More: vihaan24.hatenablog.com/entr…
#compound #management #Software #biotech #biopharma #lifescience #trendingtopic #Covid_19

1
6

27 Apr 2020
Se lo strumento è effettivamente questo: google.com/amp/s/amp.padovao…, costa un fottio, già 3-400k euro per i modelli più vecchi e/o ricondizionati, ma pare ne vogliano prendere un secondo per Verona! Se interessati a vedere cosa fa, cercate "Labcyte Echo" in YouTube...
1
2

5 Feb 2020
Look ma, no pipette tips! We use the way cool Labcyte Echo liquid handlers to set up our PCRs (amongst many processes) at Ginkgo. They’re Greta Thunberg approved!
5
7
79

29 Jan 2020
Before the end of #SLAS2020 be sure to stop by BOOTH 828 and learn how the addition of the Labcyte Echo and Access products to our Biomek portfolio makes us Better Together.
1
2
27 Jan 2020
Visit us at BOOTH 828 at #SLAS2020 this week and learn how the addition of the Labcyte Echo and Access products to our Biomek portfolio makes us Better Together. Are you an expert @ #liquidhandling? Test your skills at our Lab Run video game and win a t-shirt!
2
3
Visit us @SLAS2020 in San Diego, Jan 27-29, Booth 828, learn about the latest advancements & discover how the addition of the Labcyte Echo and Access products to our Biomek portfolio makes us Better Together. For discounted exhibition-only passes visit bit.ly/2Fs9dfw
1
2
6

24 Sep 2019
Labcyte has been acquired by Beckman Coulter Life Sciences. As part of the acquisition, our updates will now come from @BCIlifesciences. Please follow us there. Learn more: bit.ly/2LomgBw

3
4