
The one thing I definitely want out of an OoT remake would be seamless overworld transitions so it would drastically reduce loadtime. Some other things I could think of would be expanding smaller towns, giving more sidequest progressions, or give NPCs more dialogue if your stuck
2
59

\long-haul planning,truck safely avg 50-55mph.--build accurate cargo transit estimate,factor:Fueling Brk: 30m break\8h//driving. Add 30-45m /day \fueling. Handling: 2-3h loadtime \ load-securing-paperwork. HOS limit a solo driver--11h//driving /14h.
1
11

Jun 3
You reminded me of an Andrew Kelley vid where he bragged about how very clean the Zig startup strace is. Having been building a runtime too, I was like yeah, that's not my goal at all. I don't do a lot of things at loadtime, but the few things I do do help save much time later on
1
3
137

May 18
have you tried (spiritual equivalents of) pi-autoresearch to "make loadtime for this website go down" ?
1
6
5,471

First-person shooters have been trash for the last 20 years. Bring back permanent damage, real save/load systems, and using the 1-9 keys on your keyboard to switch between weapons. And bring back enemies that are placed on the map at loadtime instead of spawning during gameplay
1
2
38

Apr 10
i was deliberately flattening ptx as ir/virtual isa ptx embedded for forward compat ptx jit vs native cubin the fallback behavior, as such, because on dgx spark hardware, a fallback in this manner (not emitting native cubin) is slower at loadtime, a time penalty that is incurred on first load/cache invalidation/miss, because at buildtime the cpu does cuda c->ptx->stop, producing a binary that contains ptx, which then, at loadtime, needs to be consumed by the driver jit to create native cubin containing sm_121-specific machine code; contrast with compiling to native cubin, where, at buildtime, cpu does cuda c->ptx->ptxas->sass, resulting in native cubin containing sm_121-specific machine code, which can be loaded directly for that target at loadtime, thereby skipping the ptx jit step.
1
2
52

Apr 1
i can send you the files tho. will make homepage loadtime around 30min-2days, unless you choose fedex shipment.
1
2
199
36,741

Mar 24
🌟 Why Boost Speed matters more than ever
New comprehensive guide covering:
✨ Core concepts
🔧 Practical examples
⚡ Performance tips
🎯 Best practices
Dive in 👇
🔗 kubaik.github.io/boost-speed
#LoadTime #SustainableTech #NetworkOptimization #CyberSecurity #programming
8

Mar 10
Can u make a playlist on Frontend Performance ? Topics like how to improve Loadtime and Runtime Performance of your Frontend Applications ?
2
372

◤◢◤◢◤ ⚠︎ Goal 1 Reached ⚠︎ ◢◤◢◤◢
[■■■□□□□□□□] 30% ᴄᴏɴɴᴇᴄᴛᴇᴅ...
Angora's much smaller, so of course she has a quicker loadtime!
Legs & accessories now parsed! 🎀✖️
We can do this together!
♡ ↻ ?
ꔫ┊ #ENVtuber ♡ #VtuberDebut ♡ #Vtubers

◤◢◤◢◤ ⚠︎ Model Reveal ⚠︎ ◢◤◢◤◢
Hmm... Looks like my synchronization is a little off!
I'll need a bit of support from our network!
♡ ↻ to stabilize connection and reveal your data angel?
ꔫ┊ #ENVtuber ♡ #VtuberDebut ♡ #VTuberUprising ♡ #ModelReveal
7
21
2,094


Just shipped some new changes to @pxxl_space
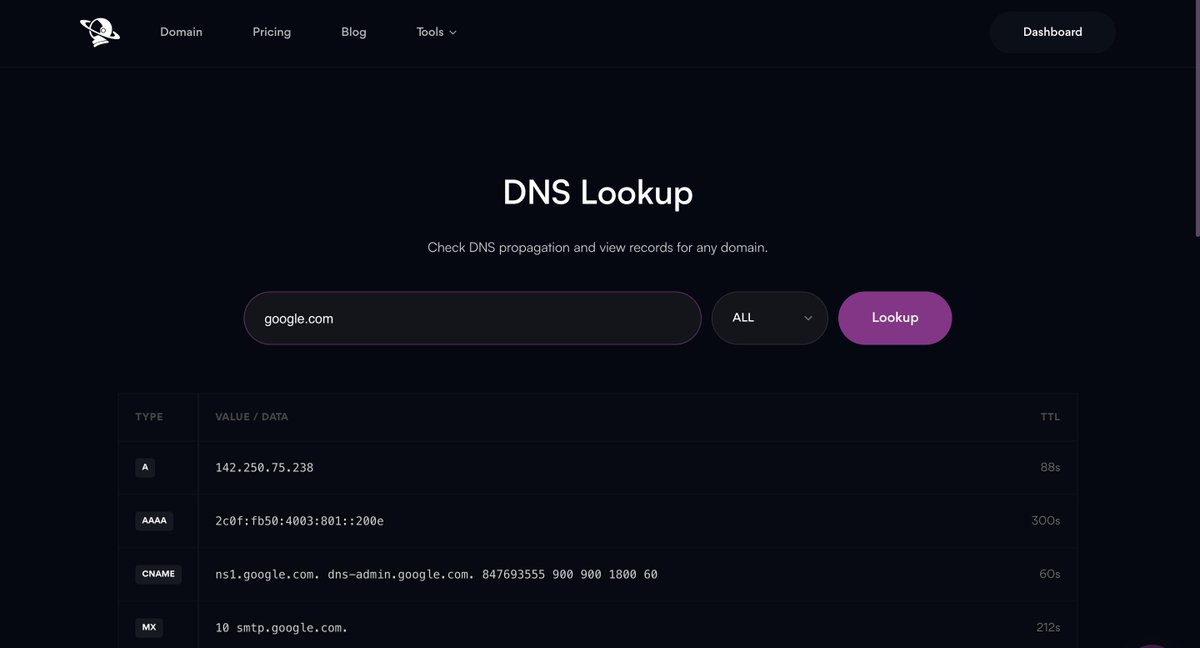
🟪 We added a new DNS lookup feature
🟪 Fixed the scroll bar issues for some devices
🟪 Fixed lagging on safari
🟪 Made the loadtime faster

We've pushed some new changes to prod!
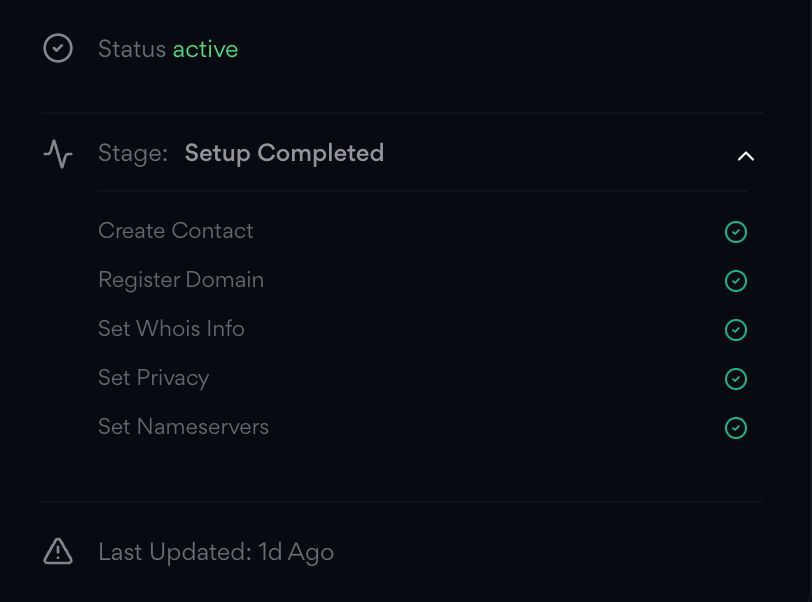
🟪 Added a new feature that shows you the status of your domain registration so you don't keep guessing
🟪 Changed the Nameserver sytem for faster resolution and better Interface
6
2
46
2,172


5 Sep 2025
Made a custom boombox that can play audios not uploaded to roblox:
- Performant
- Fast music loadtime
- Has custom playback loudness
- Not moderated (This is why this is a admin only tool, but still cool to chill with it)
#ROBLOX #RobloxDev #RobloxDevs
1
2
18
1,037

19 Aug 2025
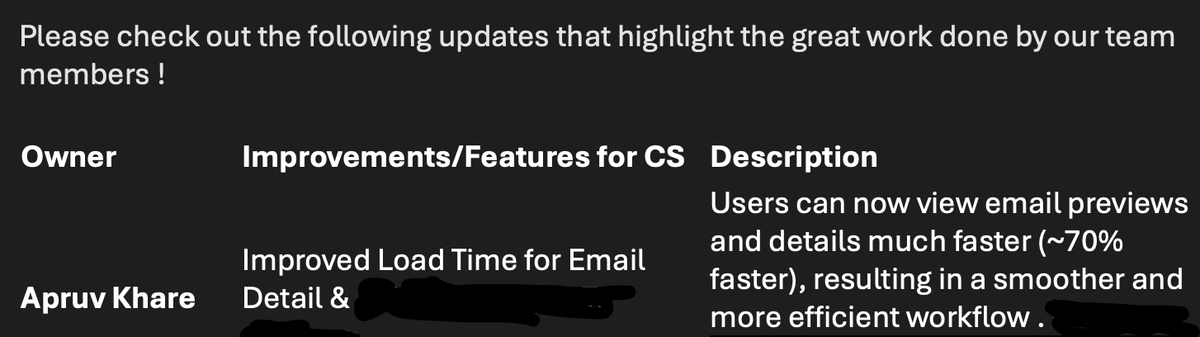
My manager sent out a mail today appreciating the amazing work done by our team. I had worked on investigating performance issues and improving the loadtime by ~70% of one of the critical pages of our product. Felt nice to be appreciated for the efforts ☺️
1
19
512

5 Aug 2025
I sent moth, baz, shlump, pearl, vic, vic, vick, syd, psy, and vopsea doodle gimmicks........time will tell but im lurking
strawpage has MINUTES before I tweak ab the loadtime...where are my sent text and doodle gimmicks.....

3
6
159


19 Jul 2025
I NEED A GAME PERFORMANCE/LOAD TIME EXPERT!
Adding a bunch of new features and content to help with playtime, including today’s event and next week! Should go up a bit!
BUT….
I think I have some load issues and FPS spike issues. Load time/smoothness and feature script optimization.
Looking for an expert in performance/loadtime. Can pay hourly, project, or % split. :)
Dm me with portfolio or examples of perf work and price.
If you refer me someone awesome I work with I’ll give you 5k robux!
2
398

24 Jun 2025
O bom do Quick resume não é o lado rápido, é vc poder voltar ao jogo exatamente no momento que desligou, vc congela o jogo quando desliga e volta de onde parou. Galera parece que não conhece isso e compara com loadtime
44
2,537

19 Jun 2025
THIS.
Ppl just convinienely forgot that base MHWorld didn't even run that well on PS4, everyone were moaning about loadtime, the game lacking contents, too easy, nothing to do, etc. When IB dropped I get walled by ViperKadachi for 2 months because loading the map crashs my laptop

ワールドもライズも当時は酷かったけどSteam版の発売が遅かったから目立たなかっただけで、同日発売になったワイルズのこれが正当な評価だよなと思いつつ、いくらなんでも5末アプデからの低評価の伸びがおかしくないか?とも思う
低評価されるのは理解できるけど、数の多さは自分の感覚と合わない
3
4
28
2,249